Exact posterior scores for inverse problems
EPS derives an exact posterior score for linear inverse problems and keeps standard denoiser training and sampling intact.

EPS derives an exact posterior score for linear inverse problems and keeps standard denoiser training and sampling intact.
- Research org: Unspecified in arXiv abstract
- Core data: Roughly an order of magnitude fewer denoiser evaluations
- Breakthrough: Closed-form posterior score under general Gaussian interpolants
Exact Posterior Score Estimation for Solving Linear Inverse Problems tackles a familiar mismatch in diffusion and flow-based restoration: the model learns an unconditional prior, but inverse problems need posterior sampling conditioned on measurements. The paper’s core move is to show that, for linear Gaussian inverse problems, the posterior score can be written exactly and then trained as a denoising objective without throwing away the structure of standard pretraining.
That matters because a lot of practical restoration systems live in one of two camps: either they keep a pretrained denoiser fixed and bolt on approximate measurement corrections, or they train a separate conditional model that no longer looks like the original denoiser. EPS is trying to keep the best part of the diffusion stack—the denoising backbone—while making it mathematically aligned with posterior sampling.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Diffusion and flow-based models are good at learning data priors by reversing Gaussian corruption. In plain English, they learn how to turn noise back into a plausible sample from the data distribution. But when you want to solve a linear inverse problem, such as recovering a signal from measurements, you do not just want a plausible sample. You want a sample from the posterior: something that is both realistic and consistent with the observations.
The abstract says existing methods usually miss that target in one of two ways. Some methods steer a fixed pretrained denoiser with approximate measurement-matching corrections. Others train a conditional restoration model, but that can abandon the denoising structure that made the original prior useful in the first place. EPS is positioned as a way out of that tradeoff.
For engineers, the practical issue is simple: if your sampler is fighting the measurement constraint with extra correction steps, you pay for it in complexity and compute. If you retrain a whole conditional model, you may lose the reuse benefits of standard denoiser pretraining. This paper is about removing that awkward middle layer.
How the method works in plain English
The key claim is a closed-form derivation of the exact posterior score for linear Gaussian inverse problems under general Gaussian interpolants. The abstract does not spell out the full derivation, but it does give the important interpretation: posterior sampling can be reduced to a denoising problem at an operator-dependent shifted pivot under an anisotropic noise covariance.
That sentence is dense, but the engineering idea is straightforward. Instead of treating conditioning as an external correction slapped onto a denoiser, EPS rewrites the posterior itself into a form that still looks like denoising. The “shifted pivot” depends on the measurement operator, and the noise is anisotropic, meaning it is not assumed to be the same in every direction.
From that identity, the authors build Exact Posterior Score, or EPS, as a denoising training objective. The important design choice is that EPS preserves the input/output structure of standard pretraining. In other words, you can train it from scratch or fine-tune a pretrained denoiser without changing the basic backbone shape.
At inference time, EPS uses the same sampler as the underlying backbone. The abstract explicitly says there are no likelihood gradients or projections. That is a notable simplification for deployment, because it means the posterior correction is absorbed into training rather than added as a separate runtime loop.
What the paper actually shows
The evaluation covers five linear inverse problems across FFHQ and ImageNet. The abstract says EPS outperforms both training-free and training-based baselines on fidelity, perceptual, and distributional metrics. It does not provide the exact metric values in the abstract, so there are no benchmark numbers to quote here.
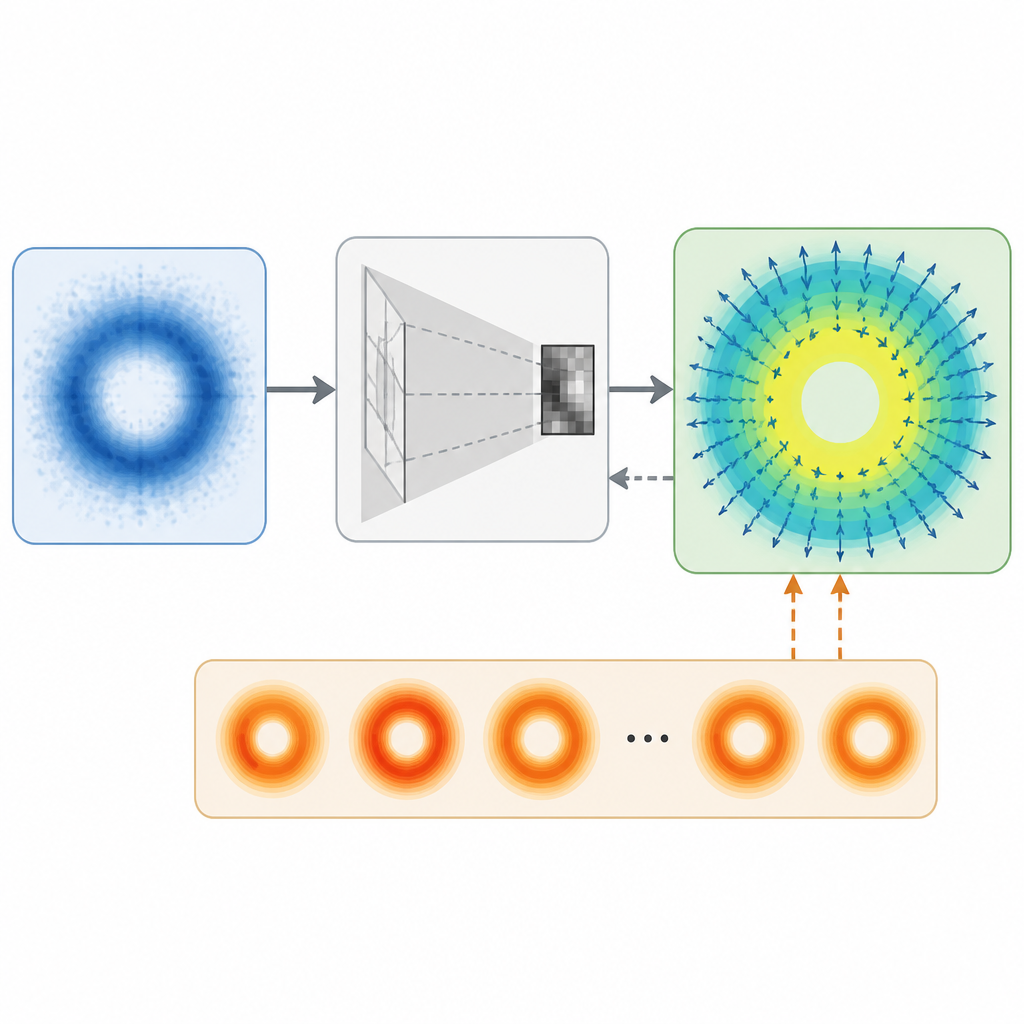
One concrete number does appear: EPS uses roughly an order of magnitude fewer denoiser evaluations than gradient-based posterior samplers. That is the most actionable result for practitioners, because denoiser evaluations are often a major part of inference cost in diffusion-style pipelines.
The paper also claims the method works in both training-from-scratch and fine-tuning settings. That makes EPS more flexible than methods that only make sense as a post-hoc correction layer or only as a fully conditional retraining recipe. The abstract does not say which backbone architectures were used, so you should not assume any specific implementation beyond the denoiser-based setup described here.
- Evaluated on five linear inverse problems
- Tested across FFHQ and ImageNet
- Compared against training-free and training-based baselines
Why developers should care
If you build restoration, reconstruction, or measurement-conditioned generation systems, this paper is interesting because it tries to make posterior sampling feel like ordinary denoising again. That can simplify your training stack, reduce inference-time hacks, and make it easier to reuse pretrained diffusion backbones instead of replacing them.
The compute angle is especially relevant. Roughly an order of magnitude fewer denoiser evaluations is not a cosmetic improvement; it can change whether a sampler is practical in a latency-sensitive pipeline. The abstract does not claim wall-clock timings, memory savings, or deployment benchmarks, so those remain open questions.
There is also a modeling tradeoff to keep in mind. EPS is derived for linear Gaussian inverse problems under general Gaussian interpolants. That is a meaningful class, but it is still a class. The abstract does not claim the same closed-form posterior score applies to nonlinear inverse problems, non-Gaussian observation models, or arbitrary measurement operators.
So the practical reading is: EPS looks like a cleaner way to do posterior-aware diffusion when the problem structure matches the assumptions. It does not read like a universal replacement for all conditional generation or all inverse problems.
What is still unclear
The abstract leaves out several details that matter for implementation decisions. It does not specify the exact inverse problems in the five-task evaluation, the denoiser architectures, the sampler hyperparameters, or the absolute metric scores. It also does not give ablation results showing which part of the method contributes most to the gain.
That means the strongest claim you can make from the source is narrow but useful: EPS provides an exact posterior-score formulation for a specific class of inverse problems, and it appears to improve both quality and efficiency relative to the baselines the authors tested.
For teams already using diffusion models in reconstruction or inverse rendering-style workflows, the paper is worth a close read because it attacks the conditioning problem at the score level instead of layering on more inference-time machinery. If the derivation holds up in code, that is the kind of change that can simplify a whole pipeline.
// Related Articles
- [RSCH]
Stablecoin remittances hit 9% in Bank of Italy test
- [RSCH]
Stablecoins Hit $308B as SVB’s Shock Still Echoes
- [RSCH]
Rust compiler speed wins from July 2026
- [RSCH]
Build a Small Language Model with DeepMind
- [RSCH]
PAC-MAN makes humanoid dodgeball safer
- [RSCH]
ReToken uses one learned token to fetch visual context