Headroom’s token compression is the right kind of MCP tool
Headroom is worth adopting because it reduces token usage without changing how MCP clients work.

Headroom cuts token use without forcing changes to Claude Code or Cursor.
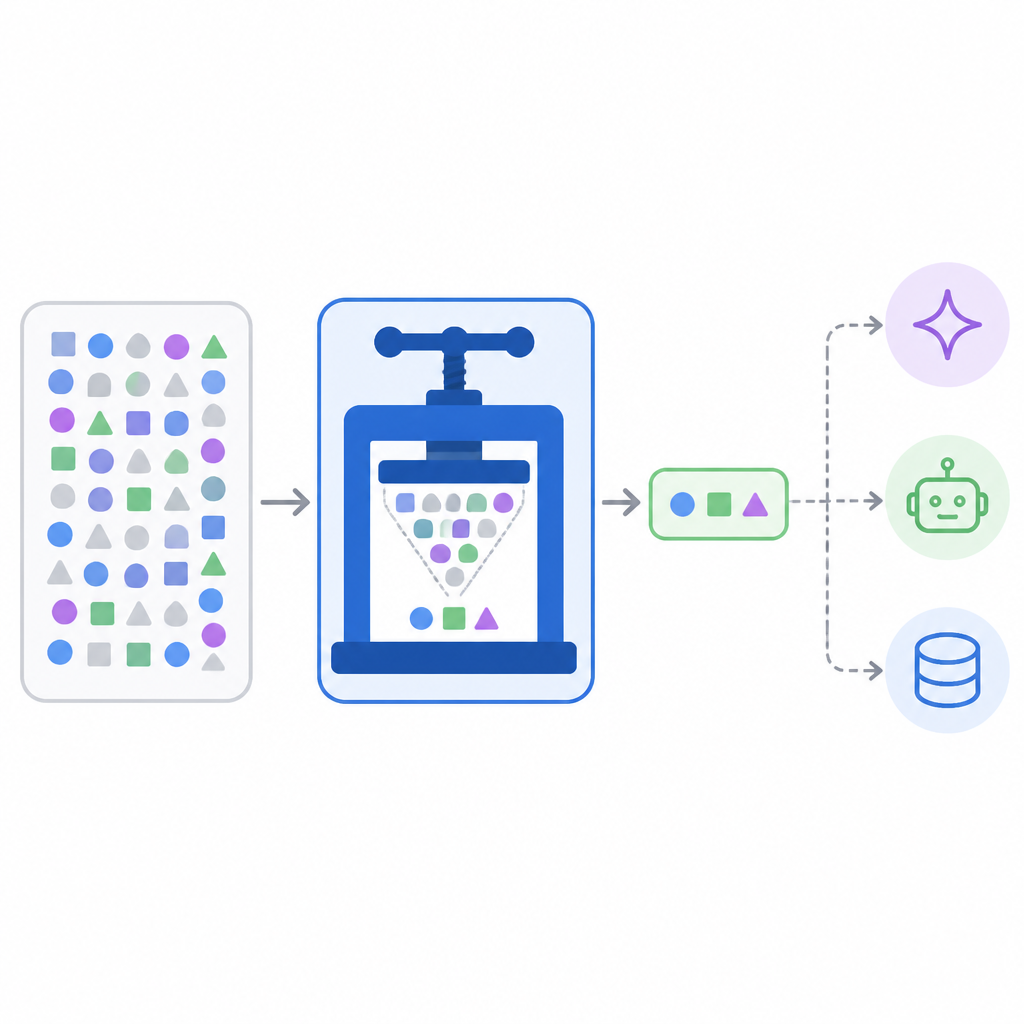
Headroom deserves attention because it solves a real cost problem with a boring, practical interface: an MCP server that plugs into clients people already use. The appeal is not novelty for its own sake. It is that headroom_compress, headroom_retrieve, and headroom_stats turn context trimming into a standard tool call instead of a custom integration project. In a market where every extra prompt token becomes recurring spend, a system that claims major compression and works inside native MCP clients is not a gimmick. It is infrastructure.
Token compression is a product feature, not a research demo
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most teams do not need a new model to save money. They need fewer useless tokens moving through the stack. Headroom attacks that directly by compressing context before it reaches the model, which means the savings show up where budgets are actually burned: in repeated long chats, large codebase prompts, and agent loops that keep re-sending the same material. A tool that lives at the protocol layer is easier to adopt than a rewrite of prompting workflows.

The strongest signal here is compatibility. Claude Code and Cursor already speak MCP, so a Headroom server fits into workflows without asking engineers to replace their tooling. That matters because adoption usually fails at the integration step, not the algorithm step. If a team can point an MCP client at a server and immediately call compress, retrieve, and stats, it turns compression from a side project into a default habit.
Open tooling beats private optimization in fast-moving agent stacks
Open source compression tools have an advantage that closed, vendor-specific tricks do not: they can be inspected, tuned, and swapped without waiting for a platform owner. Headroom’s open distribution makes it easier for teams to verify what is being removed, how retrieval works, and whether the output still preserves the details that matter. In agent systems, trust is not optional. If a tool silently mangles context, the failure looks like model weakness when it is really a preprocessing bug.
The star count is not proof of technical superiority, but it does reveal demand. A project that climbs to 44,000 stars is meeting a broad pain point, and token pressure is one of the most universal pains in LLM development. That popularity matters because it suggests Headroom is not solving a niche edge case. It is landing in the exact place where teams feel the cost of long context, repeated retrieval, and bloated prompts every day.
The counter-argument
The best objection is simple: compression can destroy meaning. If the tool strips away details that later turn out to matter, the model will answer faster and cheaper while becoming less reliable. That risk is especially serious in coding and research workflows, where a single omitted constraint can produce a wrong patch or a misleading summary. Critics are right to warn that token savings are worthless if they come from information loss.
There is also a platform argument against celebrating yet another utility layer. Some teams would rather rely on model-native long context, better retrieval, or upstream prompt discipline than add a separate compression service. That stance is rational when the workflow is small or the cost of mistakes is high. In those cases, extra machinery can become another place to debug.
That counter-argument is real, but it does not defeat Headroom. It sets the boundary for where to use it. Compression should not replace source-of-truth retrieval or careful prompt design, and Headroom does not need to. Its job is to reduce redundant context after the important material has been identified. When used that way, the risk is manageable and the savings are immediate. The alternative is paying full price for every repeated token while pretending context bloat is free.
What to do with this
If you are an engineer, test Headroom at the edge of your most expensive workflows: long code review sessions, multi-step agent runs, and any MCP-backed client that keeps resending the same context. Measure token spend before and after, then check answer quality on a fixed set of tasks. If the savings are large and the outputs stay stable, promote it to a standard layer. If not, keep it out of critical paths. The right decision is empirical, but the default should be to try compression before paying for more context.
// Related Articles
- [TOOLS]
Litefuse 不是 Langfuse 的补丁,而是 Agent 可观测的正确方向
- [TOOLS]
20 AI coding assistants, stripped down for 2026
- [TOOLS]
Open Code Review turns AI reviews into line-accurate checks
- [TOOLS]
Grok Imagine 1.5 turns prompts into 720p video
- [TOOLS]
OCR 4 turns PDFs into cited RAG input
- [TOOLS]
AI code review is beating human teammates