Language critiques improve imitation learning
This paper uses natural-language critiques to train policies from suboptimal demonstrations.

This paper uses natural-language critiques to train policies from suboptimal demonstrations.
- Research org: Unspecified in arXiv abstract
- Core data: No benchmark numbers in abstract
- Breakthrough: Trains policies with structured language critiques instead of scalar feedback
For engineers working on imitation learning, the practical problem here is familiar: real demonstrations are often messy. They are not always expert-quality, and the usual way to squeeze them into training data is to compress everything into a single score or weight. This paper argues that that compression throws away useful information about what went wrong, what progress was made, and what should happen next.
The authors’ core idea is simple but important: keep the supervision in language form instead of reducing it to a scalar. That means the training signal can explicitly describe task progress, identify suboptimal behavior, and suggest corrective actions. In other words, the model gets feedback that is closer to how a human would explain a mistake.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Imitation learning from suboptimal demonstrations usually depends on signals like confidence estimates, discriminator scores, or importance weights. Those work as compact supervision, but they are blunt instruments. A scalar can tell you that one trajectory is better than another, but it cannot say why, where the agent got stuck, or what kind of correction would help.

That limitation matters because many real-world datasets are not clean expert traces. If you are training on partial, noisy, or imperfect demonstrations, you often need more than a ranking signal. You need supervision that carries structure. The paper’s thesis is that language is a better container for that structure than a single number.
This is especially relevant for continuous-control settings, where behavior unfolds over time and mistakes are not always easy to summarize. Navigation, manipulation, and gameplay all involve sequences of decisions, and the quality of a trajectory may depend on subtle local failures rather than one global score.
How the method works in plain English
The method starts by constructing language labels from demonstrations. These labels are not generic commentary; they are meant to explicitly describe current progress, call out suboptimal behavior, and give fine-grained corrective guidance. That makes the supervision signal richer than a scalar reward proxy.
Next comes the language-critique loss. Instead of converting those critiques into a number and then training from that number, the objective uses the structured language directly. The abstract says this is done without reducing the critique to scalars, which is the key design choice behind the method.
The paper instantiates the idea in two familiar imitation-learning setups: behavior cloning and diffusion policies. Those versions are named LC-BC and LC-DP. So the contribution is not just a new model architecture; it is a training framework that can be plugged into different policy-learning families.
That makes the paper interesting from an implementation standpoint. If you already have a pipeline for behavior cloning or diffusion-based policy learning, the idea is not to replace the whole stack. It is to swap in a more expressive supervision channel for suboptimal data.
What the paper actually shows
The abstract does not provide benchmark numbers, so there are no exact scores, percentages, or throughput figures to quote here. What it does say is that the authors evaluate on diverse continuous control tasks spanning navigation, manipulation, and gameplay.
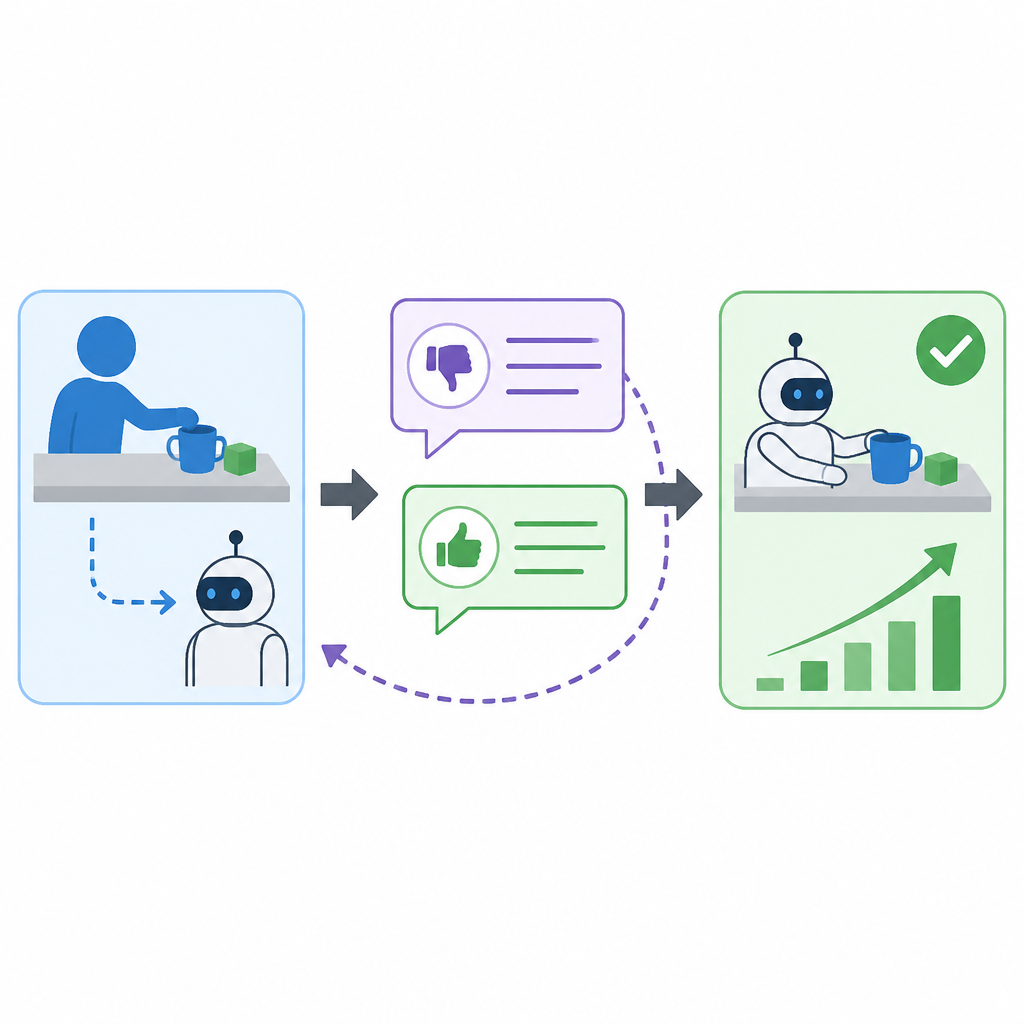
Across those tasks, the methods “consistently outperform” strong imitation learning and offline reinforcement learning baselines. That is the main empirical claim available from the abstract. It suggests the language-critiqued training signal is not just more interpretable in theory; it also appears competitive in practice against established approaches.
The paper also includes a theoretical result: under standard assumptions, the proposed objective upper-bounds the expert performance gap. In plain terms, the training objective is not just an ad hoc heuristic. The authors provide a formal guarantee connecting their language-critique loss to performance relative to the expert.
That said, the abstract leaves out a lot of details that matter for real deployment. We do not get the exact task suite, the language-labeling process, the model sizes, or the failure cases. We also do not know how expensive it is to generate or curate the language critiques compared with scalar labels.
Why developers should care
If you build policies from imperfect demonstrations, this paper points to a useful shift in mindset: supervision does not have to be a single score. Language can act as a richer intermediate representation for training, especially when the dataset contains mixed-quality trajectories.
For practitioners, the appeal is not just better interpretability. A critique can encode multiple signals at once: what the agent is doing, what is wrong, and what to do instead. That may make it easier to learn from noisy data without collapsing everything into one ambiguous weight.
There is also a broader systems lesson here. Many ML pipelines already depend on textual feedback elsewhere in the stack. This paper suggests that the same idea can be pushed into policy learning, where structured natural-language supervision may outperform more compressed forms of guidance.
What is still unclear
The biggest open question is scalability. The abstract does not say how the language critiques are produced, whether they come from humans, another model, or a hybrid process. That matters because the cost of generating high-quality critiques could determine whether the method is practical at scale.
Another question is robustness. Language is richer than scalars, but it is also more variable. If critique quality changes across annotators, domains, or prompt styles, the training signal could become inconsistent. The abstract does not address that.
Finally, the paper focuses on continuous control tasks. That is a strong and relevant testbed, but it is still a specific slice of imitation learning. It remains to be seen how well the approach transfers to other settings where demonstrations are suboptimal, sparse, or highly multimodal.
Still, the core message is clear: if your current imitation-learning setup throws away too much information by compressing feedback into a number, language may be the better training signal. This paper gives that idea a concrete method, a theoretical argument, and empirical support across several control domains.
- Scalar supervision from suboptimal demos is often too compressed
- Language critiques preserve progress, failure mode, and correction signals
- LC-BC and LC-DP adapt the idea to behavior cloning and diffusion policies
// Related Articles
- [RSCH]
One Transformer Layer Can Carry RL Gains
- [RSCH]
BINEVAL uses binary questions to score LLM outputs
- [RSCH]
RLMF teaches LLMs to express uncertainty better
- [RSCH]
QVal tests dense supervision before training
- [RSCH]
Self-Explanation Training Still Tracks Model Behavior
- [RSCH]
WorldEvolver lets LLM agents revise foresight