Variable-Width Transformers cut wasted capacity
A new transformer design widens early and late layers while shrinking the middle to save compute and memory.

This paper shows transformers can use nonuniform layer widths to cut compute and memory.
- Research org: Unspecified in arXiv abstract
- Core data: 22% FLOPs reduction
- Breakthrough: Wider edges, narrower middle with parameter-free residual resizing
Variable-Width Transformers argues that not every layer in a transformer needs the same width. The practical idea is simple: keep the early and late layers wider, compress the middle, and let the model spend its capacity where it seems to matter most. For engineers, that matters because width is one of the main drivers of parameter count, compute, and memory footprint.
The paper is not claiming a brand-new training recipe or a magic optimization trick. Instead, it asks a more architectural question: if different depths in a transformer play different roles, why force them all to have the same hidden size? The authors test that idea across decoder-only language models from 200M to 2B parameters, plus a 3B MoE model, and compare against uniform-width baselines with matched parameter budgets.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most transformer stacks are built with a constant width from the first layer to the last. That makes implementation straightforward, but it also means every layer gets the same share of parameters and computation whether or not it needs them. In practice, that can be a blunt allocation strategy for a network where shallow, middle, and deep layers may be doing different kinds of work.
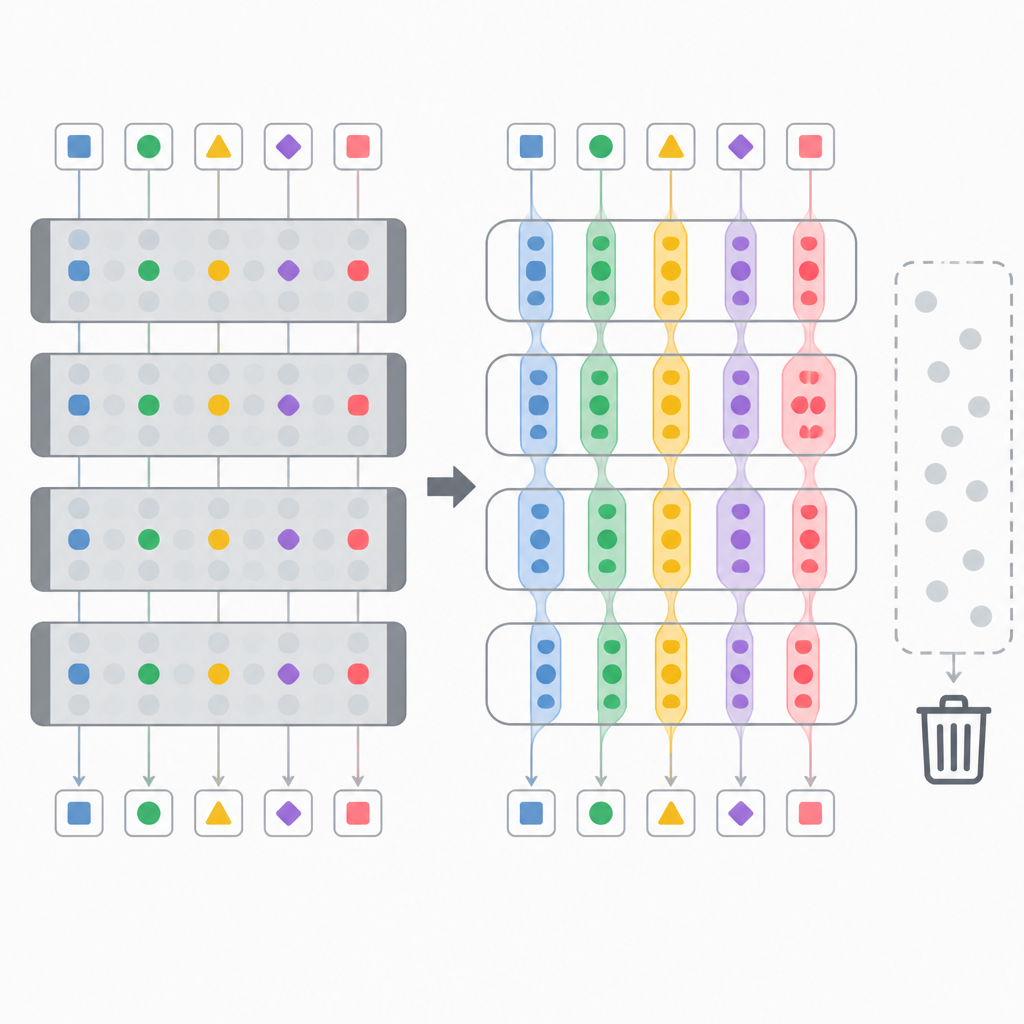
The paper’s premise is that width is being spent too evenly. If some layers are more important for representation building and others are more useful for refinement, then a uniform design may waste budget in places that do not need it. The authors frame this as a problem of capacity allocation across depth, not just a problem of making models bigger.
That is a useful angle for anyone trying to run larger models under tight constraints. If a model can reach similar or better loss with less average width, then you may get a better tradeoff among training cost, inference latency, KV cache size, and I/O pressure.
How the method works in plain English
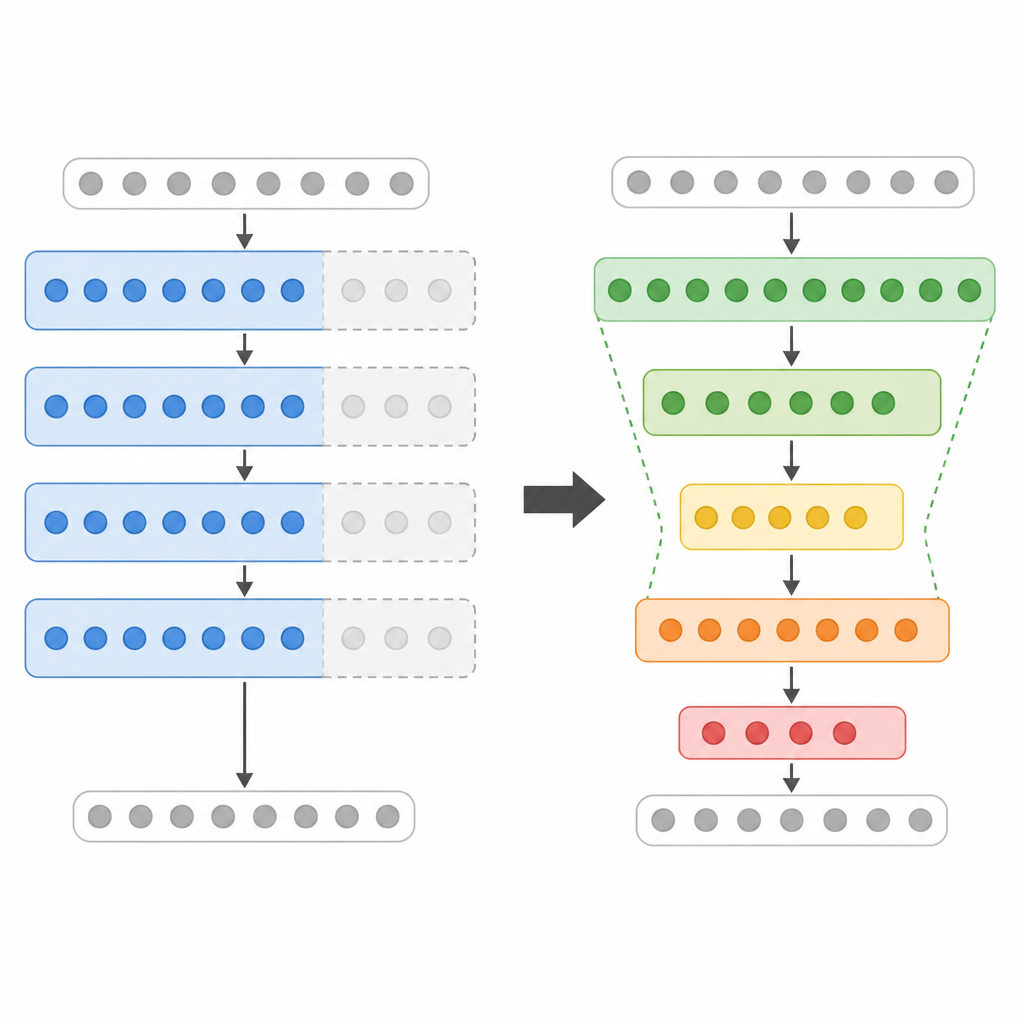
The architecture is described as a “×-shaped” > <former, which is an easy visual shorthand for what the width schedule looks like. The model starts wider, narrows in the middle, and widens again toward the end. So instead of a flat rectangle of constant width, the network becomes more like a bottlenecked hourglass.
To make that work, the paper uses a parameter-free residual resizing mechanism. That detail matters because changing width across layers is not trivial: residual streams have to move between different dimensions without adding a lot of extra learned machinery. The authors’ approach keeps that resizing lightweight rather than turning the architecture into a more complicated hybrid.
In plain terms, this is an attempt to let the model “breathe” at the edges and compress in the middle. The design is not about making every layer smaller. It is about redistributing width so the average layer is slimmer while still preserving capacity where the authors think it is most useful.
What the paper actually shows
The headline result is that the variable-width design consistently outperforms parameter-matched uniform baselines on language modeling loss. That result holds across the model sizes they tested: dense models from 200M to 2B parameters and a 3B parameter MoE model.
The paper also reports resource savings. By lowering average layer width, the architecture reduces overall FLOPs by 22% under fitted loss-matched scaling curves. It also reduces KV cache memory and I/O cost by 15%. Those are concrete engineering wins, especially for inference setups where cache size and memory bandwidth can become bottlenecks.
There is another interesting piece in the analysis: the bottleneck structure produces qualitatively different representations in the residual streams. The abstract does not spell out every diagnostic detail, but the point is that the network is not merely doing the same thing with fewer channels. The internal representation dynamics change in a way that appears tied to the nonuniform width schedule.
What the abstract does not give us is benchmark table granularity. There are no task-by-task scores, no exact loss deltas, and no per-model breakdown in the source text provided here. So the safe reading is: the direction of the result is clear, but the full magnitude across every setting is not available from the abstract alone.
Why developers should care
If you build or deploy transformer models, width is one of the most expensive knobs you can turn. It affects parameter count, activation size, KV cache footprint, and the amount of work each layer does. A design that trims average width without losing performance can translate directly into cheaper training runs and more manageable inference.
This paper is especially relevant for teams thinking about scaling laws and architecture search. Instead of assuming that “bigger everywhere” is the best path, it suggests that smarter allocation of capacity across depth may be a better use of budget. That could influence how future model families are designed, particularly when memory or throughput is tight.
There is also a practical implementation takeaway: architectural changes that save FLOPs are not always useful if they add complexity elsewhere. The parameter-free residual resizing is important because it keeps the method relatively clean. Still, the paper only establishes this approach in the context of the tested decoder-only and MoE models, so broader generalization remains an open question.
What is still unclear
The abstract does not tell us how the method behaves on downstream tasks beyond language modeling loss, or whether the same width pattern is optimal for every model family. It also does not provide evidence about training stability, optimization sensitivity, or how easy the architecture is to integrate into existing codebases.
Another open issue is whether the same savings hold at much larger scales or under different serving constraints. The reported 22% FLOPs reduction and 15% KV cache and I/O reduction are meaningful, but they come from the paper’s fitted scaling analysis and tested model range. Engineers should treat that as a strong signal, not a universal guarantee.
Even with those caveats, the core message is straightforward: uniform width is not obviously the best default. This paper gives a concrete, testable alternative that rebalances capacity across depth and shows that the change can improve loss while reducing resource use.
Bottom line
Variable-width transformers are a reminder that architecture efficiency is not just about pruning or quantization. Sometimes the bigger win comes from designing the model shape itself more carefully. For teams chasing lower inference cost or better scaling efficiency, that is a result worth paying attention to.
- Nonuniform width can beat uniform baselines at matched parameter budgets.
- The reported savings are 22% fewer FLOPs and 15% lower KV cache memory and I/O cost.
- The method uses a bottlenecked width schedule with parameter-free residual resizing.
// Related Articles
- [RSCH]
The OpenAI Hugging Face breach proves agents need hard limits now
- [RSCH]
Systema turns AIVC scores into a harder test
- [RSCH]
Stablecoin remittances hit 9% in Bank of Italy test
- [RSCH]
Stablecoins Hit $308B as SVB’s Shock Still Echoes
- [RSCH]
Rust compiler speed wins from July 2026
- [RSCH]
Build a Small Language Model with DeepMind