可變寬度 Transformer 省算力
這篇論文證明,Transformer 不必每一層都同寬;把前後層加寬、中央層縮窄,可以在維持表現下減少計算與記憶體。

這篇論文證明,Transformer 不必每一層都同寬;把前後層加寬、中央層縮窄,可以在維持表現下減少計算與記憶體。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:FLOPs 減少 22%
- 突破點:前後寬、中間窄
Variable-Width Transformers 想處理的是一個很直白的問題:既然 Transformer 的不同深度,可能在做不同的事,為什麼每一層都要硬塞成同樣寬度?這篇論文提出的答案是,不用。它把容量重新分配到深度方向上,讓前段和後段更寬,中段更窄,目標是用更少的平均寬度,換到更好的效率。
這不是在改訓練技巧,也不是在發明新的優化器。它比較像是在重新畫模型結構圖。對工程師來說,這種改法的吸引力很直接:寬度會影響參數量、計算量、記憶體占用,還會牽動推理時的快取壓力。只要平均寬度能降下來,整體成本就有機會跟著下修。
這篇論文要解的痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
多數 Transformer 都是從第一層到最後一層維持固定 hidden size。這樣做的好處是簡單,實作也一致,但代價是每一層拿到的容量都一樣,不管那層到底需不需要那麼多資源。
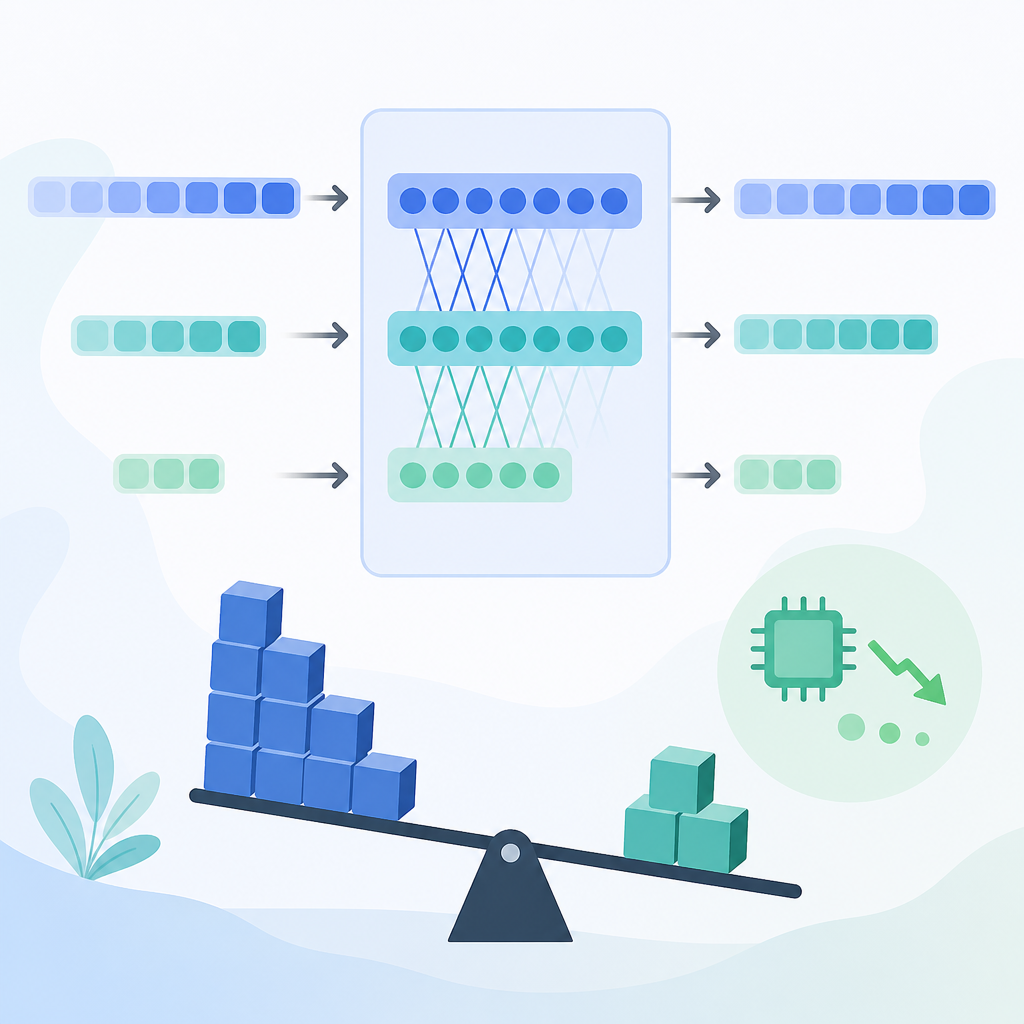
論文的切入點,是把這件事看成「容量分配」問題,而不是單純的「模型要不要更大」問題。作者認為,淺層、中段、深層可能承擔不同功能;如果真的如此,平均分配寬度就不一定是最省的做法。某些地方可能太寬,某些地方反而不夠用。
這個想法對受限環境特別有意義。當訓練預算、推理延遲、KV cache 大小都有限時,模型結構本身的設計就會直接影響能不能部署、能不能擴充、以及成本是不是還能接受。
方法怎麼做:把寬度做成「沙漏」
這篇論文的架構可以想成一個「×」形或沙漏形的 Transformer。前面的層比較寬,中間縮窄,後面再放寬。和傳統那種整條直線一樣寬的設計相比,它不是平均灑資源,而是刻意把資源往兩端集中。
要讓這件事可行,論文用了 parameter-free residual resizing。這點很關鍵,因為不同層的寬度不一樣時,殘差流要在不同維度之間轉換,不能只是把寬度改了就算。作者的做法是盡量保持輕量,不額外塞進很多新的可學參數,避免把架構變得更重、更難控。
白話一點說,就是讓模型在邊緣「呼吸」得更寬,中段「收縮」一下。它不是把每一層都變小,而是把總容量重新排版,讓平均寬度下降,但重要區段仍保留足夠表現力。
論文實際證明了什麼
這篇摘要裡最重要的結果,是可變寬度設計在語言模型 loss 上,穩定優於參數量對齊的 uniform baseline。作者測了 dense decoder-only 模型,規模從 200M 到 2B 參數,也測了 3B 的 MoE 模型。摘要提供的結論是跨這些設定都成立。
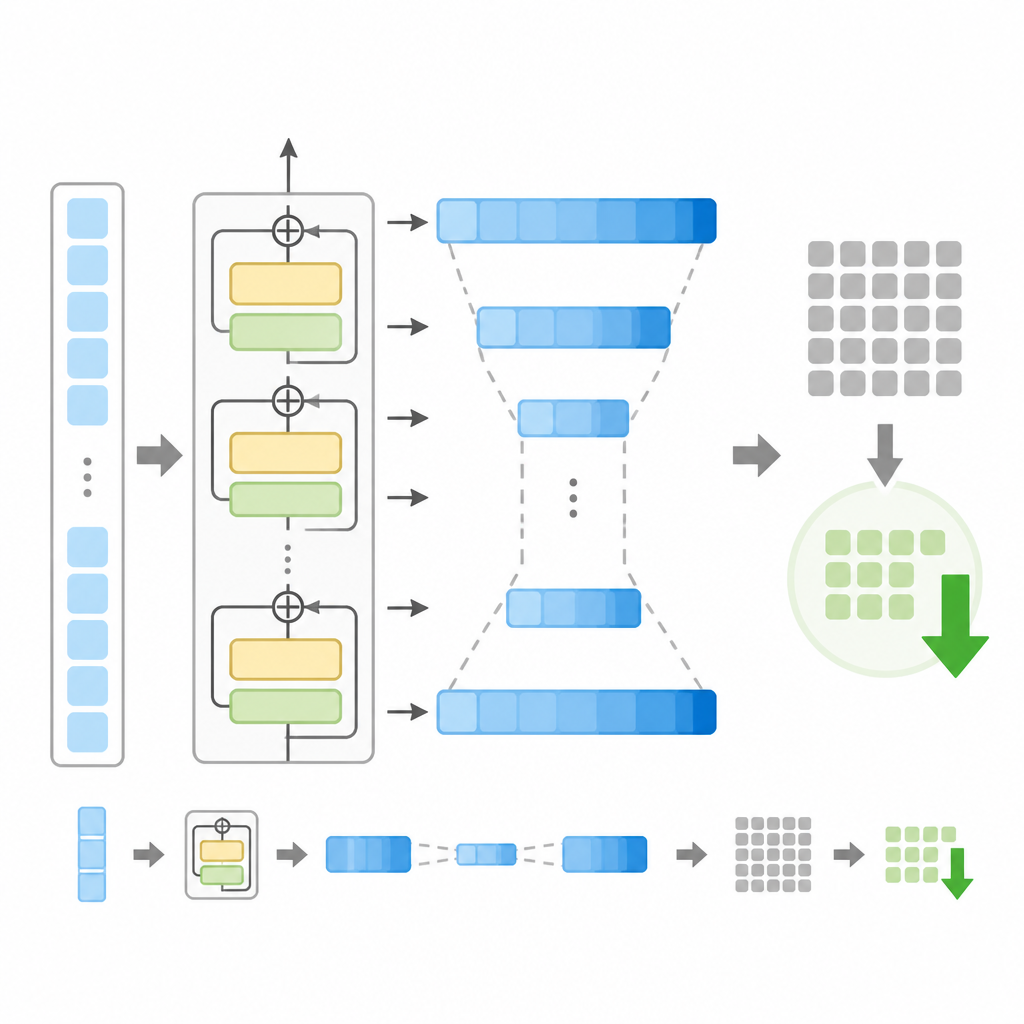
在資源面,作者也給出具體節省。根據 fitted loss-matched scaling curves,這種設計把整體 FLOPs 降了 22%。另外,KV cache 記憶體和 I/O 成本也降了 15%。對做推理部署的人來說,這兩個數字都很實際,因為它們直接對應到硬體壓力和服務成本。
論文還提到,這種 bottleneck 結構會讓 residual stream 的表徵出現質變。摘要沒有把所有診斷細節展開,但重點很明確:這不是單純把同樣的事情用更少 channel 做完,而是內部表徵動態真的變了,而且看起來和非均勻寬度安排有關。
不過,摘要沒有公開完整 benchmark 細節。沒有逐任務分數,也沒有每個模型的 loss 差距表。就摘要能看到的資訊來說,我們可以確定方向是正向的,但還不能把完整幅度講得太細。
對開發者有什麼影響
如果你在做模型訓練或部署,寬度其實是最貴的旋鈕之一。它影響參數量,也影響 activation 大小、KV cache 佔用,還會影響每層要做多少運算。只要平均寬度下降一點,訓練和推理的成本都有機會跟著下來。
這篇論文的價值,在於它提供了一個不同於 pruning、quantization 的方向。不是先把模型做大再裁掉,而是從一開始就重新設計容量分布。對想做 scaling law、做 architecture search,或是在算力很緊的情況下維持品質的團隊,這種思路值得放進候選清單。
另一個實務重點是,省 FLOPs 的架構不一定值得用,如果它會帶來很重的實作負擔。這篇方法之所以有吸引力,就是因為 residual resizing 被做成 parameter-free,沒有把設計複雜度再往上推太多。至少從摘要看,它保留了相對乾淨的結構。
限制與還沒說清楚的地方
摘要沒有告訴我們,這個方法在下游任務上會怎麼表現。它目前講的是 language modeling loss,還沒有看到更完整的任務面證據。也沒有說明這個寬度分布是不是對所有模型家族都一樣有效。
訓練穩定性、對最佳化的敏感度、以及接到既有 codebase 會不會麻煩,摘要也都沒有交代。這些對工程落地其實很重要,因為一個架構只要多幾個維度轉換點,整個實作和除錯成本就可能上升。
還有一個問題是尺度外推。摘要給出的 22% FLOPs 降幅和 15% KV cache / I/O 降幅,都是在作者的 fitted scaling 分析和測試模型範圍內得到的。這代表它是個強訊號,但還不能直接當成所有情境都成立的保證。
總結
這篇論文的核心訊息很簡單:Transformer 不一定要每層同寬。把容量往前後層集中、把中間層縮窄,可能同時拿到更好的 loss 和更低的資源消耗。
對開發者來說,這提醒了一件事:模型效率不只來自剪枝或量化,也可能來自架構本身的重新分配。當你在意推理成本、記憶體壓力、或訓練預算時,怎麼分配寬度,可能比一味把模型做大更重要。
- 非均勻寬度在參數對齊下優於 uniform baseline。
- 摘要給出的節省是 FLOPs 降 22%,KV cache 記憶體與 I/O 成本降 15%。
- 方法核心是沙漏式寬度排布,加上 parameter-free residual resizing。