VLK trains humanoid motion from synthetic scenes
VLK synthesizes vision-language-kinematics supervision to train humanoid loco-manipulation from reconstructed indoor scenes.

VLK synthesizes vision-language-kinematics supervision to train humanoid loco-manipulation from reconstructed indoor scenes.
- Research org: Unspecified in arXiv abstract
- Core data: 48,000 paired trajectories
- Breakthrough: Reconstructs scenes, synthesizes trajectories, then renders egocentric training pairs
Humanoid robots are hard to train for real-world tasks because they need more than just motion labels. They need synchronized first-person images, language instructions, and robot-compatible whole-body trajectories, all aligned for the same situation. This paper argues that the missing ingredient is not a better policy architecture alone, but a way to generate that full training tuple at scale.
For engineers working on embodied AI, this matters because data is the bottleneck. If you cannot collect enough paired perception-and-control data from real humanoids, your model has to learn from partial supervision or hand-built datasets that do not cover enough situations. VLK tries to close that gap by manufacturing the supervision in reconstructed indoor scenes instead of waiting for expensive human teleoperation at every step.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper focuses on perception-based humanoid loco-manipulation, which means a robot has to move through an environment and interact with objects while using egocentric observations and task instructions. That is a harder problem than pure locomotion or pure manipulation because the policy has to connect what the robot sees with how its whole body should move.
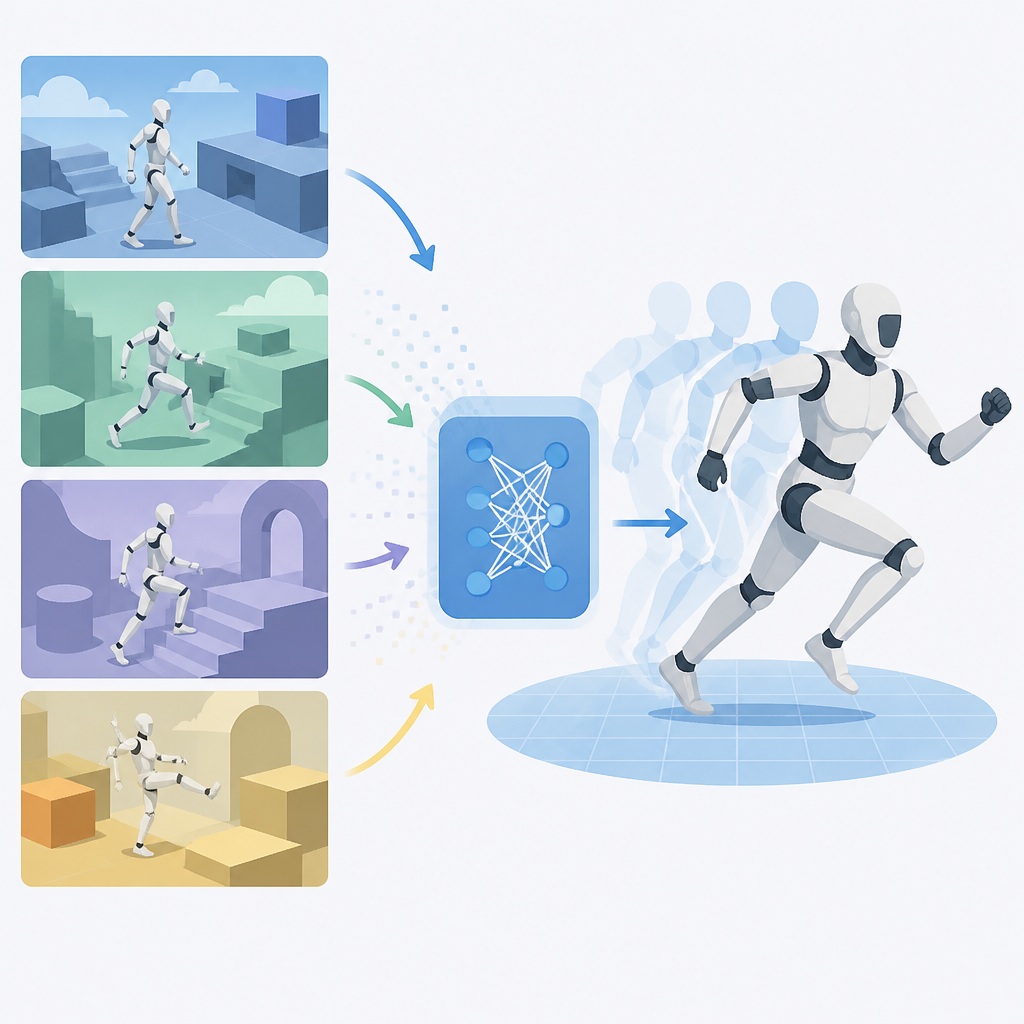
The authors point out a specific data problem: learning this mapping requires synchronized egocentric images, language commands, and robot-compatible kinematic trajectories, but no existing data source provides that complete tuple at scale. That is the gap VLK is designed to fill. In other words, the model does not just need motion demonstrations; it needs aligned multimodal supervision that looks like real robot experience.
This is a practical issue for anyone building humanoid systems. If the training set lacks either the visual context, the instruction, or the motion trace, the policy has to infer the missing piece indirectly. That makes sim-to-real transfer harder, especially for tasks where the robot must navigate and then manipulate an object in the same episode.
How the method works in plain English
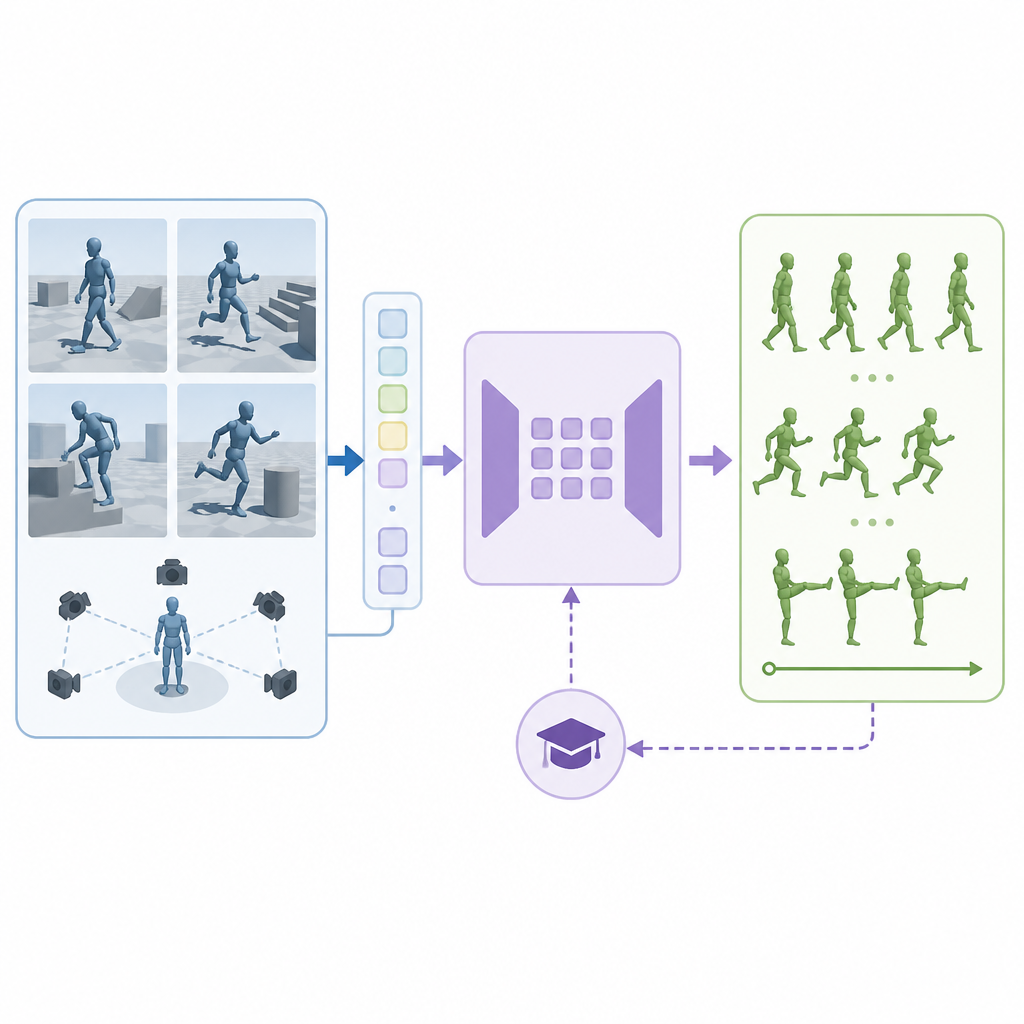
VLK stands for vision-language-kinematics, and the pipeline is built to generate all three signals synthetically. The process starts by reconstructing indoor environments with 3D Gaussian Splatting, which gives the system a metric-scale scene representation. That reconstructed scene is then used as a source of privileged information for generating navigation and object-interaction trajectories.
Once the trajectories exist, the system renders paired egocentric observations afterward. That detail matters: instead of capturing images first and trying to infer motion later, the paper generates the motion plan using scene knowledge and then creates the matching first-person views. The result is a dataset where the image, instruction, and kinematic trajectory are aligned by construction.
The paper says this pipeline produces 48,000 paired trajectories with no human intervention. Those trajectories are used to train a VLK policy that predicts short-horizon whole-body kinematic trajectories. A whole-body tracker then converts those predicted trajectories into actions for the physical humanoid.
That separation between prediction and execution is a useful design choice. The policy can focus on producing a structured motion target, while the tracker handles the lower-level control needed to turn that target into robot actions. For developers, this is a familiar pattern: keep the learned model on the semantic or geometric planning side, and let a dedicated controller handle execution.
What the paper actually shows
The abstract does include one concrete scale number: 48,000 paired trajectories. It does not provide benchmark tables or percentage gains in the abstract, so there are no numerical comparisons here to quote beyond dataset size and the physical evaluation target.
What the authors do claim is that the trained system works on a real humanoid. They evaluate on the physical Unitree G1 performing navigation and single-object transport. The key result is qualitative but important: synthesized interactions in reconstructed scenes provide effective supervision for sim-to-real perception-based humanoid loco-manipulation.
That is a narrower claim than “solves humanoid manipulation,” and that restraint is useful. The paper is not saying the robot can do everything, and the abstract does not claim broad open-world generalization. It demonstrates that synthetic supervision from reconstructed scenes can be enough to train a policy that transfers to at least these physical tasks.
Because the abstract does not list benchmark numbers, success should be interpreted carefully. We know the system was evaluated on a real Unitree G1, and we know the tasks were navigation and single-object transport. We do not know from the abstract how it compares numerically to baselines, how many trials were run, or how robust it is across environments and object types.
Why developers should care
If you build robot policies, the big takeaway is that high-quality multimodal data may be synthesizable from reconstructed environments instead of collected manually. That opens a path to training humanoid systems on much larger datasets than teleoperation alone can provide, especially when the task requires aligned vision, language, and motion supervision.
The method also suggests a workflow that is easier to scale than traditional data collection. Reconstruct a scene, generate trajectories using privileged geometry, render matching egocentric views, and train a policy on the resulting tuples. For teams working on embodied AI, that is a concrete recipe for turning static scene reconstructions into training data for action policies.
There are still obvious limitations. The abstract only mentions indoor environments, navigation, and single-object transport, so the method’s coverage is limited in what it explicitly reports. It also relies on reconstructed scenes and privileged scene information, which means the synthetic data pipeline depends on having a usable reconstruction in the first place.
Another open question is how far this scales beyond the demonstrated setting. The paper shows that the approach can supervise a humanoid policy for real-world tasks, but the abstract does not tell us how well it handles clutter, long-horizon task chains, or more diverse object interactions. Those are the kinds of details practitioners should look for in the full paper before treating VLK as a general-purpose recipe.
What to look for in the full paper
If you are evaluating this for your own stack, the most important missing details are the ones the abstract does not supply: baseline comparisons, failure cases, and how sensitive the pipeline is to scene reconstruction quality. Those determine whether synthetic supervision is a niche trick or a reusable training strategy.
It would also be useful to know how the short-horizon kinematic predictions are structured, how the whole-body tracker is designed, and whether the policy depends heavily on the specific reconstruction method. The abstract makes the high-level idea clear, but the engineering value will depend on how much of the pipeline can be swapped out without losing performance.
Still, the core message is straightforward: if you can reconstruct scenes well enough, you may be able to generate the aligned data humanoid loco-manipulation needs. That is a meaningful step for anyone trying to move humanoid learning away from scarce human demonstrations and toward scalable synthetic supervision.
// Related Articles
- [RSCH]
WorldEvolver lets LLM agents revise foresight
- [RSCH]
LeVo 2 tackles full-length song generation
- [RSCH]
Claude Sonnet 4.6 narrows the SRE gap
- [RSCH]
GLM 5.2 beats Claude in Semgrep’s IDOR test
- [RSCH]
OPD lets you distill skills without brute-force RL
- [RSCH]
Google DeepMind turns science into tools