Why Distribution Fine Tuning beats SFT for LLM writing
Distribution Fine Tuning beats SFT because it matches human text distributions more closely.

Distribution Fine Tuning beats SFT because it matches human text distributions more closely.
Distribution Fine Tuning is the right answer to slop-filled LLM writing, and SFT alone is not enough to produce text that reads like human prose.
Rosmine’s case is simple: models trained with supervised fine-tuning still overuse phrases, drift into generic structure, and miss the texture of the training set even when they follow prompts well. The post backs that claim with three separate measures, including token distribution distance, embedding-level distance, and a judge model preference score. On the reported benchmark, DFT beats an SFT “super baseline” on the metrics that matter for writing quality, and it does so without requiring a giant jump in compute or model size. That is not a small improvement. It is evidence that the standard post-training stack is optimizing the wrong target.
First argument: SFT optimizes samples, not distributions
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
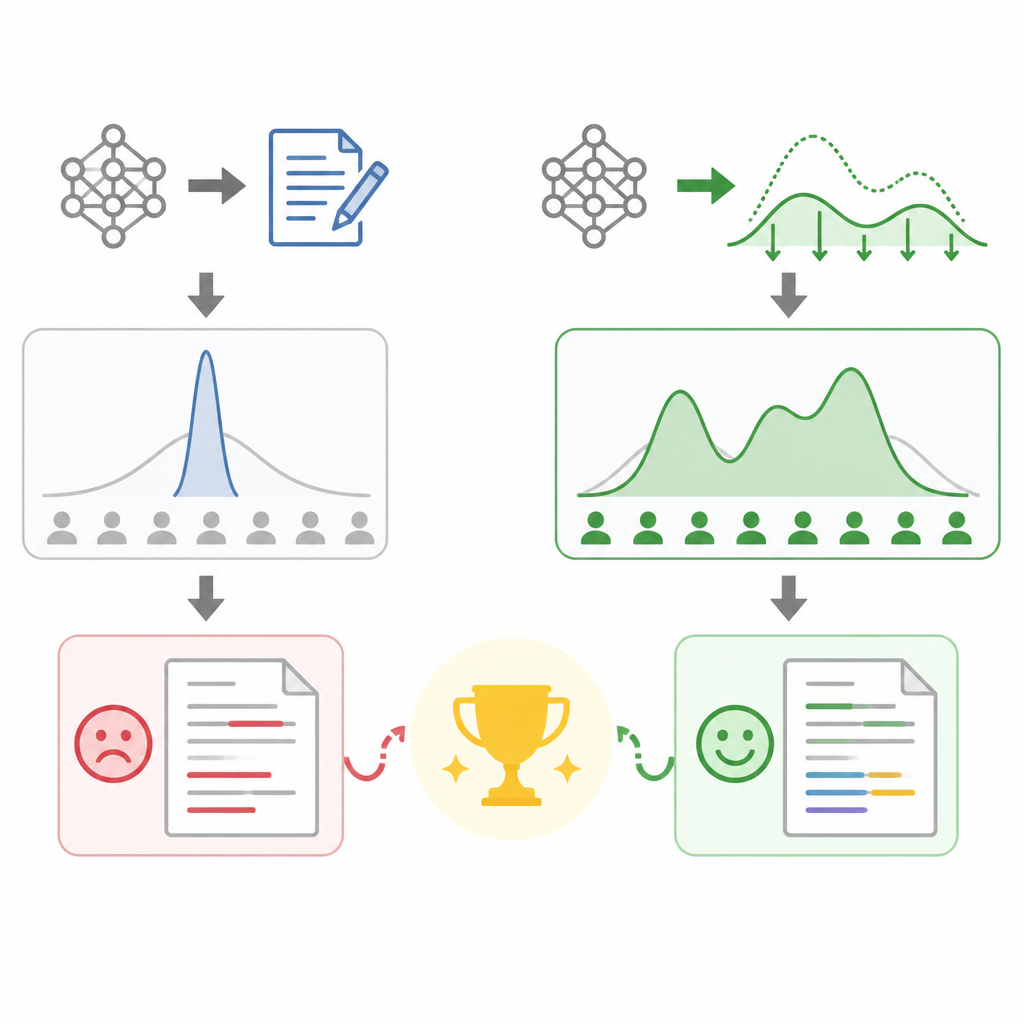
SFT teaches a model to imitate individual examples, but writing quality is a distributional property. If a model learns the right answer format while missing the frequency of details, sentence shapes, and phrase variety in the source data, it can still look polished and feel wrong. That is exactly what the Rosmine post measures with MMD and token L2 distance. The point is not that the model is unhelpful. The point is that it is statistically off. In writing, being statistically off shows up as repetition, generic transitions, and the same tired rhetorical flourishes.

The numbers make that gap hard to dismiss. In the post’s table, a 14B DFT model reaches MMD 0.018 and JMQ 0.80, while the 14B SFT super baseline sits at MMD 0.037 and JMQ 0.49. That is a huge change in judge preference and a clear reduction in distribution mismatch. The author also reports that DFT improves creativity by 164%, coherence by 28%, clarity by 16%, and meaningful detail by 146% versus the SFT baseline. Whatever one thinks of the exact metric design, the direction is consistent: matching the training distribution matters more than simply scaling up instruction following.
Second argument: “slop signs” are a training problem, not a style problem
People often talk about slop as if it were just an aesthetic complaint about model tone. It is not. It is a symptom of a training pipeline that rewards the wrong behaviors. The article points to overused tokens and phrases such as em dashes, “it’s not X, it’s Y,” and generic abstractions as artifacts of post-training, especially RLHF-driven reward hacking. That framing is persuasive because it connects surface-level writing failures to the mechanics of optimization. If the model keeps learning that safe, high-agreement phrasing wins, it will keep producing safe, high-agreement phrasing. No amount of prompt polishing fixes that root cause.
The sample outputs reinforce the point. At one temperature, the SFT model repeats the same subject over and over. At another, it veers into incoherent transitions and even non-English characters. DFT is presented as the fix because it pushes outputs back toward the training distribution rather than toward a generic “helpful” style. That matters for anyone building customer-facing systems. A chatbot that is technically compliant but stylistically brittle still fails in practice. Users notice when every paragraph sounds like a template, and they notice even more when the model’s confidence masks shallow content.
The counter-argument
The strongest objection is that DFT may simply be overfitting the appearance of human writing. A model can score well on judge preference, token frequency, and embedding similarity while still being less useful, less truthful, or less adaptable than a plain SFT model. There is also a real methodological concern: if the evaluation relies on a specific judge model, a specific dataset slice, and a specific notion of “human-like,” then the gains may not transfer cleanly across domains. For code, legal drafting, support replies, and creative fiction, the right distribution is not the same.
That objection is valid, but it does not rescue SFT. It only defines the boundary of the claim. The right conclusion is not that DFT solves every output problem. The right conclusion is that current post-training stacks are leaving writing quality on the table because they optimize for helpfulness and preference without enough pressure to preserve the actual distribution of good text. Rosmine’s results are strong enough to show that distribution matching is a missing layer. Even if DFT needs domain-specific tuning and broader validation, the burden has shifted. Anyone defending SFT as sufficient now has to explain why a method that better matches human text should not be preferred for writing tasks.
What to do with this
If you are an engineer, stop treating writing quality as a prompt-engineering issue and start measuring it as a distribution problem. Build evals that track repetition, content richness, and human-vs-model preference together, then test post-training methods against a fixed baseline instead of cherry-picking sampler settings. If you are a PM or founder, do not ship a “smart” writing product that merely sounds compliant. Demand outputs that vary naturally, carry details, and survive side-by-side comparison with human text. The practical lesson is blunt: if your model writes like a template, the fix is in training, not in wording.
// Related Articles
- [RSCH]
CRDTs keep replicas in sync without locks
- [RSCH]
Post-Deterministic Systems for Autonomous Infra
- [RSCH]
Causal methods for measuring task learnability
- [RSCH]
RL Training That Hands Off Control Gradually
- [RSCH]
OmniGameArena benchmarks VLM game agents better
- [RSCH]
TurboQuant cuts KV cache memory 6x in Google tests