Databricks is right: model serving should adapt, not be tuned by hand
Databricks is right: production AI serving should adapt to each model instead of being hand-tuned.

Databricks argues production AI serving should adapt to each model instead of being hand-tuned.
I agree with Databricks: the future of model serving is adaptive infrastructure, not teams endlessly tuning replicas, concurrency, and autoscaling knobs by hand.
Databricks says the quiet part out loud in its own numbers. Its Custom Model Serving platform claims it can handle everything from a 2 MB scikit-learn classifier on one CPU core to a fine-tuned 70B LLM on eight GPUs, while hitting 300K+ QPS with under 10ms p99 latency overhead and up to 90% lower infrastructure cost for customers leaving self-managed stacks. That is not a marginal improvement. It is the difference between serving as a product capability and serving as an internal engineering burden.
Hand-tuned serving does not scale with model diversity
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The central problem is that custom models do not behave like one another. A ranker, an embedding model, a fraud detector, and an LLM all want different shapes of compute, batching, and concurrency. Databricks describes this plainly: a CPU-heavy xgboost model may only serve one request per core, while an agent can handle hundreds of requests per core, and a fine-tuned 13B LLM benefits from batching. A static serving template cannot fit all of those at once.

This is why the old playbook fails. Traditional platforms push the complexity back onto the customer through replica counts, per-replica concurrency, and autoscaling thresholds. That is not abstraction, it is deferred labor. Every new model or traffic shift forces re-profiling, and the cost shows up as delayed launches, brittle production habits, and a dedicated serving team whose only job is to keep the lights on.
Adaptive autoscaling is the only sane answer at production load
Databricks’ own architecture points to the right design: use both request-based and resource-based signals together. Request-based autoscaling reacts quickly to bursts, while CPU or GPU utilization reveals whether replicas are actually saturated. Each signal alone is incomplete. Traffic spikes can arrive before utilization catches up, and utilization can look healthy right up until p99 latency breaks.
That matters because production traffic is not polite. A fraud endpoint can jump 10x in seconds at the start of a sale, then flatten out. A regional feature can spike for an hour and then go idle overnight. A serving layer that learns a model’s limit at runtime and adjusts concurrency and replica count automatically is not a luxury. It is the only way to hold latency, scale, and cost in balance without asking engineers to babysit every endpoint.
The real win is organizational, not just technical
Databricks frames this as removing the “ML Stack Tax,” and that phrase is accurate. The tax is not just wasted compute. It is the accumulation of meetings, dashboards, tuning rituals, and incident response that surrounds every model after it ships. When serving is manual, the organization starts to optimize for survivability instead of deployment velocity.
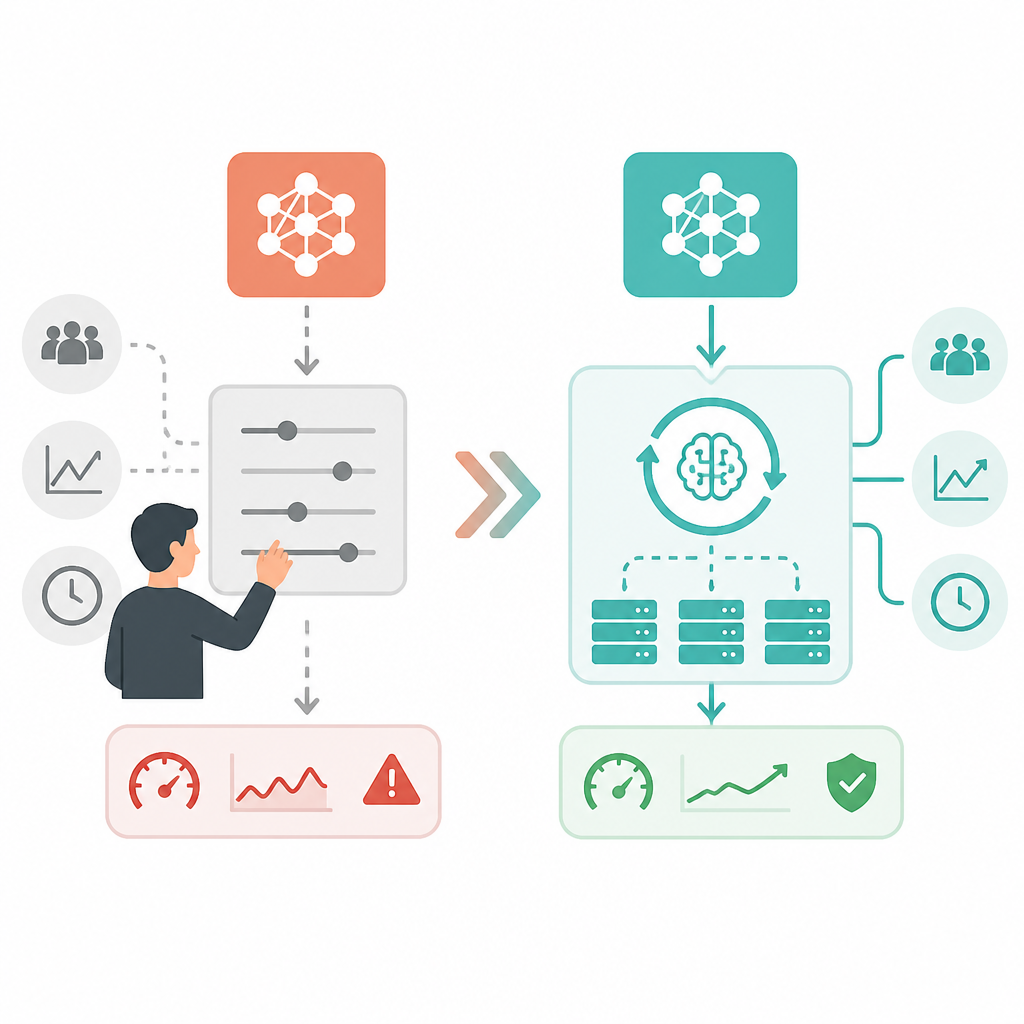
The strongest evidence is the workflow Databricks wants to eliminate: models proven in dev sitting for weeks before reaching production because infrastructure needs another round of tuning. That delay is a business cost, not an ops detail. If the serving platform can match the runtime to the model, adapt to traffic automatically, and expose telemetry by default, then the team can spend its time on better models and better product decisions instead of keeping a fragile serving stack alive.
The counter-argument
The best case for manual control is simple: generic automation can hide important tradeoffs. Some teams run highly sensitive workloads where latency, memory pressure, or cost ceilings demand explicit control. A black-box autoscaler can make the system feel less predictable, especially when a platform serves both tiny classical models and large GPU-bound models. In that world, operators want knobs because knobs feel like accountability.
There is also a legitimate concern that a vendor-managed layer can become a new dependency. If the platform’s runtime selection or scaling policy is wrong, customers may lose the ability to optimize for their own edge cases. For teams with deep infrastructure expertise, that loss of control can look expensive.
That objection is real, but it does not defeat the argument. It just defines the boundary: the platform must be opinionated on the default path and transparent about the signals it uses. Databricks’ case is stronger because it does not promise magic. It says the system learns each model’s limits at runtime, uses both traffic and resource signals, and keeps the request path short and isolated. That is a better contract than asking every customer to rediscover the same tuning lessons in production.
What to do with this
If you are an engineer, stop treating serving as a one-off deployment task and start treating it as a product surface with explicit latency, cost, and observability goals. If you are a PM or founder, optimize for platforms that remove tuning work from the critical path, because every hour spent adjusting serving knobs is an hour not spent shipping model value. Choose systems that adapt by default, expose their decisions clearly, and let your team focus on model quality instead of infrastructure triage.
// Related Articles
- [IND]
What the SALP liquidation reveals about AI trades
- [IND]
Claude’s security test became a real breach
- [IND]
X posts let execs shape the AI story
- [IND]
Jensen Huang’s AGI definition lowers the bar
- [IND]
Claude’s 2026 limit changes are a capacity story, not a product story
- [IND]
SSI's $5 Billion Backing Proves AI Safety Is a Product Strategy