AWS logging should be split between OpenSearch and S3
Centralized logging on AWS works best when OpenSearch handles live search and S3 handles retention.

Centralized logging on AWS works best when OpenSearch handles live search and S3 handles retention.
Centralized logging on AWS should be split across OpenSearch for hot queries and S3 for archive, not forced into one system.
That position is not theory. In the Anblicks architecture, Fluent Bit on EKS streams logs in parallel to Amazon OpenSearch for real-time troubleshooting and Amazon S3 for long-term retention, with Athena reserved for historical SQL queries. That design matches how incidents actually unfold: engineers need fast search during an outage, but they also need cheap retention for audits, forensics, and trend analysis after the fact. Trying to make one storage tier do both jobs turns logging into a cost problem before it becomes an observability problem.
The first argument: hot and cold logs have different jobs
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
OpenSearch is built for speed, not permanence. When a production issue lands, the value is in being able to search recent logs instantly, filter by service, and correlate events while the incident is still active. That is exactly why the article places OpenSearch on the real-time path and OpenSearch Dashboards on top of it. The point is simple: if a system is used for live debugging, it should be optimized for low-latency retrieval, not for storing every log line from the last two years.
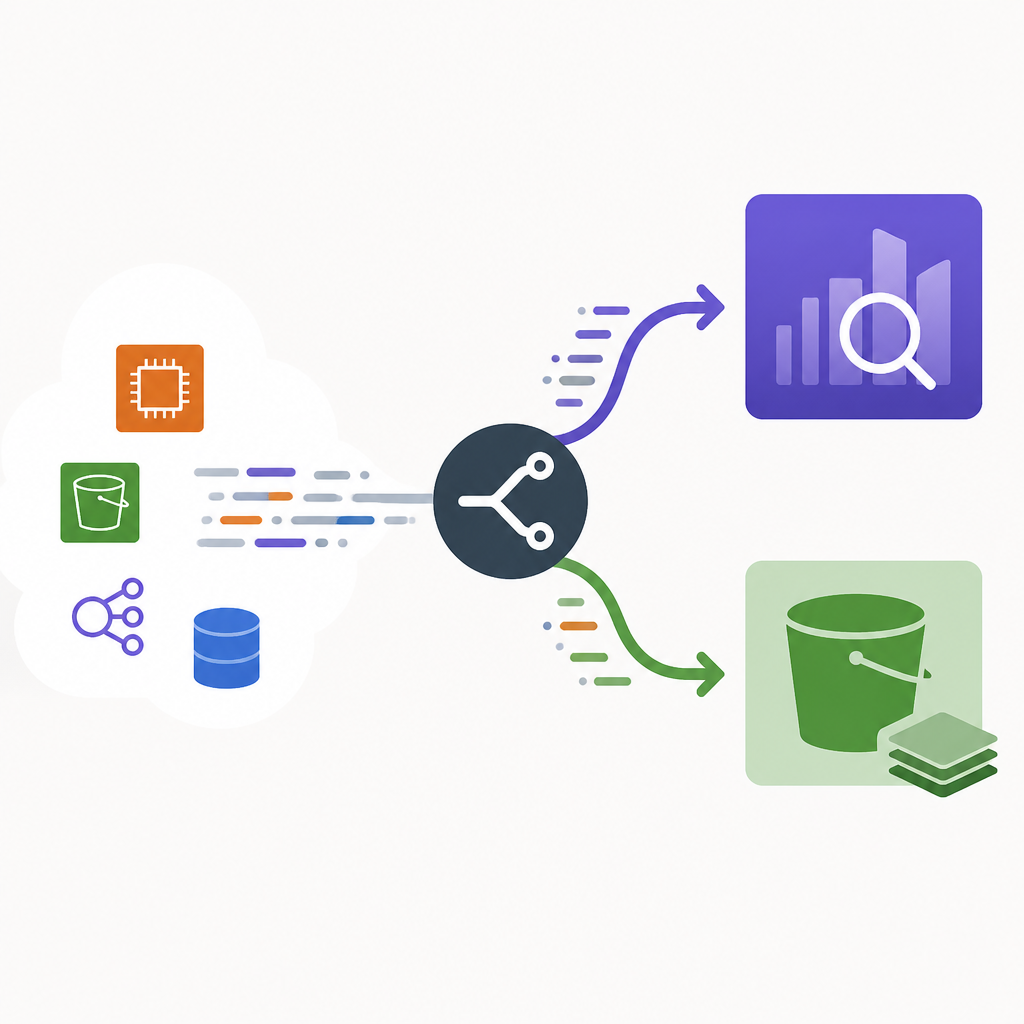
S3 is the opposite. It is cheap, durable, and designed for retention at scale. The article’s guidance to continuously archive logs to S3 is the right move because log volume grows faster than most teams expect. A logging platform that keeps all data indexed in OpenSearch pays for that growth through shard overhead, storage, and cluster management. A split architecture avoids that trap by keeping the expensive search index small and the historical archive inexpensive.
The second argument: Fluent Bit makes the split practical
The strongest part of this design is that Fluent Bit can fan out to both destinations without turning the collector into a bottleneck. The article describes Fluent Bit on EKS as a DaemonSet, which means every node runs a lightweight collector close to the workloads. That matters because centralized logging fails when the collector becomes heavy enough to compete with application traffic. Fluent Bit is small enough to be invisible and flexible enough to send the same stream to OpenSearch and S3 at once.
That dual delivery is what turns a good architecture into an operational one. Teams do not have to choose between immediate visibility and long-term retention, because the pipeline serves both. If a security team needs to investigate a login spike from last quarter, Athena can query the S3 archive. If an SRE needs to trace a 5xx burst right now, OpenSearch is already indexed and ready. The platform is not elegant because it is minimal. It is elegant because each layer does one job well.
The counter-argument
The best objection is that split logging adds moving parts. OpenSearch, S3, Athena, Glue, SNS, and Fluent Bit create a system that is more complex than a single managed observability product. A smaller team may prefer a vendor platform that bundles ingestion, search, retention, dashboards, and alerting into one bill and one control plane. That argument is serious, because operational simplicity has real value when the team is tiny or the incident load is low.
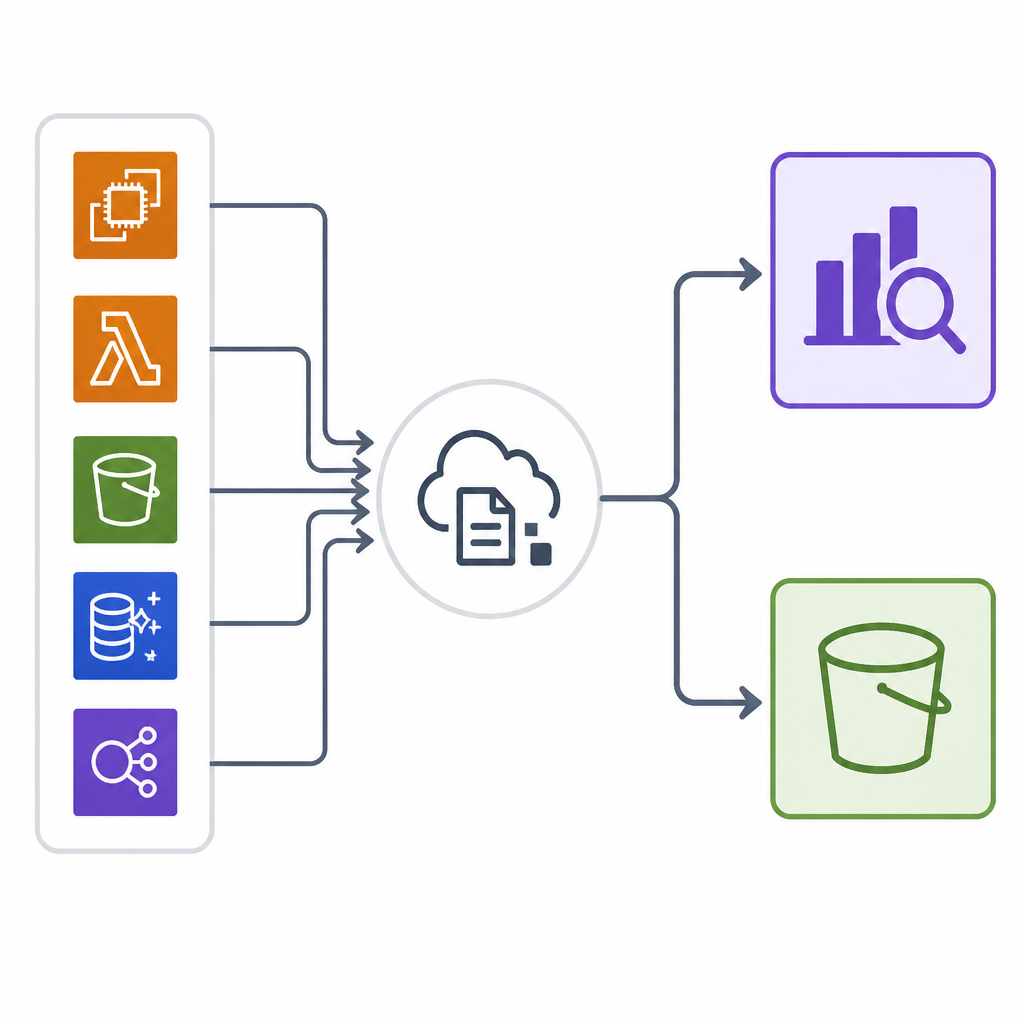
The objection also has a cost angle. Open-source plus AWS is not free just because the software is open-source. Someone still has to manage retention policies, index lifecycle, query patterns, compression, partitions, and alert rules. If the team lacks the discipline to tune those pieces, the architecture can become noisy and expensive in a different way.
But the counter-argument fails on the core question: what is the logging system for? If it is for durable operations at scale, then vendor convenience is not enough. The article’s architecture is better because it separates latency-sensitive search from low-cost retention and gives the team control over both. That is not extra complexity for its own sake. It is the minimum complexity required to keep logs useful after the first month of growth. The limit is real for very small teams, but for any organization running EKS, EC2, Lambda, and load balancers together, the split is the correct design.
What to do with this
If you are an engineer, design your pipeline around log age and query intent: keep recent, high-value logs in OpenSearch, archive everything else to S3, and use Athena for historical analysis. If you are a PM or founder, treat logging as infrastructure with a budget and retention policy, not as a dashboard feature. Build for the incident you need to solve now, and for the audit you will need six months later.
// Related Articles
- [IND]
Microsoft Build 2026: Securing code, agents, and models
- [IND]
Pentagon’s Agent Network speeds AI battle decisions
- [IND]
Codex is OpenAI’s coding agent for real work
- [IND]
VCs Should Fund AI Coding, But Only If Security Comes First
- [IND]
DCS market forecast turns plant control into growth
- [IND]
Kawa is a useful release, but sovereign AI still wins on control, not…