DeepSpec should be treated as a data-regeneration pipeline, not a tra…
DeepSpec is best understood as a conversation regeneration pipeline for training stronger models.

DeepSpec is a conversation regeneration pipeline for training stronger models.
DeepSpec should be treated as a data-regeneration pipeline, not a training trick. In the Qwen3 + Eagle3 workflow, the core move is blunt and practical: keep the system and user turns, discard the original assistant turn, and regenerate that assistant answer with the target model through an OpenAI-compatible server. That is not a minor implementation detail. It changes the training signal at the source, because the model is no longer learning from a mixed-quality transcript, but from responses produced by the model family you actually want to improve.
First argument: DeepSpec works because it fixes the label, not the loss
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The strongest part of the method is that it attacks data quality upstream. If a conversation contains a weak, stale, or mismatched assistant response, training on it teaches the model to imitate the wrong behavior. DeepSpec replaces that answer with one generated by the target model, so the supervision target aligns with the model’s own distribution. That is a cleaner form of distillation than trying to rescue noisy labels with a better optimizer.
The example code makes the mechanism explicit: system messages are preserved, assistant messages are dropped, and user messages are replayed into the target model via client.chat.completions.create. This means the regenerated dataset is not a random augmentation set. It is a controlled rewrite of the assistant side of each dialogue. The practical result is that the dataset becomes more internally consistent, which matters more than clever training knobs when the original corpus is heterogeneous.
Second argument: The OpenAI-compatible serving layer is the real enabler
DeepSpec is compelling because it uses a simple serving abstraction instead of a bespoke generation stack. The code calls an OpenAI-style client with a local base_url, which means the regeneration step can run against SGLang or any compatible inference backend. That lowers the operational cost of the pipeline: you can swap engines, scale throughput, and keep the training code unchanged.
This matters because regeneration is only useful if it is cheap enough to do at scale. A pipeline that requires custom RPC glue, custom decoding code, and manual prompt orchestration breaks under dataset volume. By contrast, the OpenAI-compatible interface turns regeneration into a standard batch job. For teams already running model serving infrastructure, that is the difference between an experimental idea and a repeatable data factory.
The counter-argument
The best objection is that DeepSpec risks collapsing diversity. If every assistant turn is regenerated by the same target model, the dataset can become self-referential. The model may learn to sound more like itself, but not necessarily to become more correct, more robust, or more useful. Critics will also point out that regeneration can amplify existing biases in the target model and erase valuable signal from the original assistant outputs.
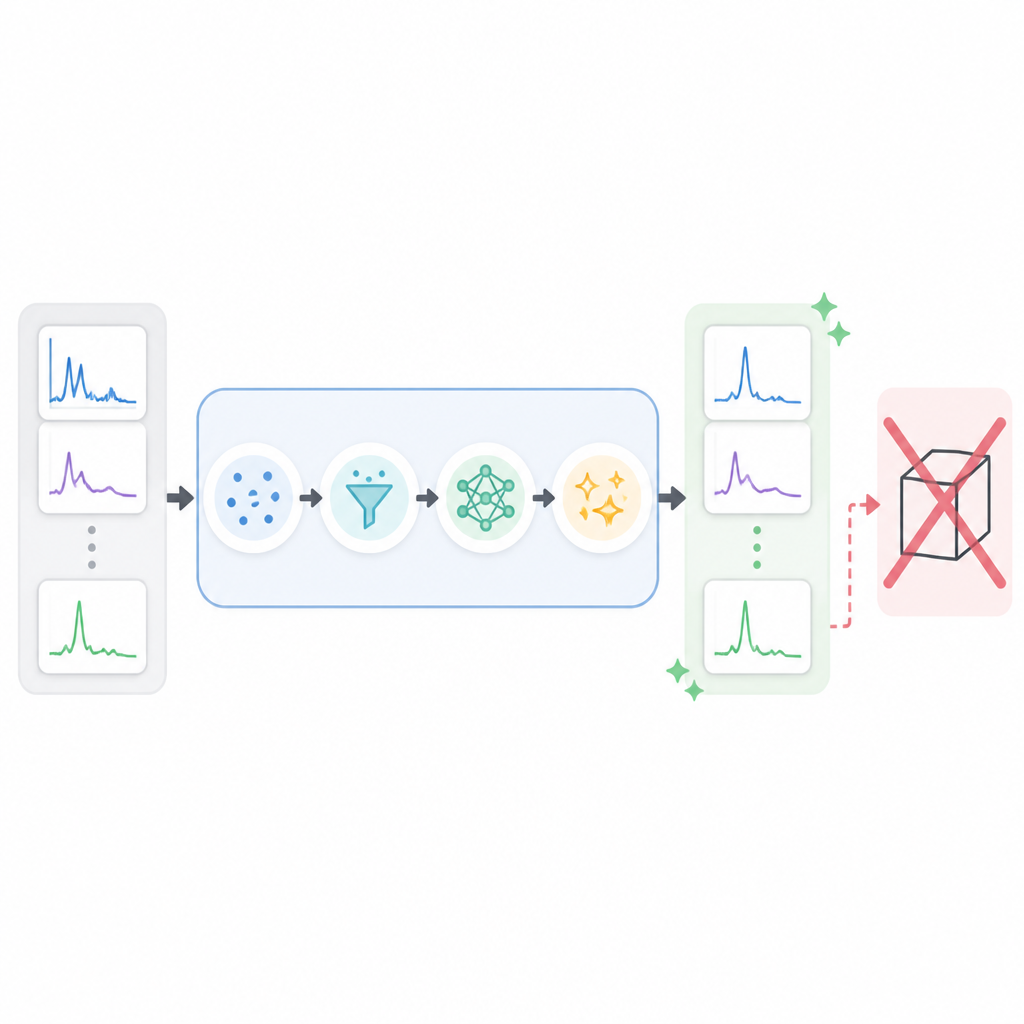
That critique is real. DeepSpec is not a replacement for careful data curation, human evaluation, or task-specific benchmarks. It is a filtering and alignment step, not a guarantee of truth. But that limitation does not weaken the case for the method; it defines its proper use. When the base corpus is noisy or inconsistent, regenerating assistant turns with a stronger target model is a rational way to raise the floor before any fine-tuning begins. The key is to treat the regenerated data as a better training substrate, not as an oracle.
What to do with this
If you are an engineer or ML lead, use DeepSpec when your training set has good user prompts but unreliable assistant answers. Build the pipeline around a stable chat API, preserve system and user turns, regenerate assistant turns in batches, and compare the resulting dataset against the original with held-out evals. If the regenerated corpus improves consistency, refusals, and instruction following without flattening performance on harder tasks, keep it. If it only makes the model more polished but less accurate, stop and rework the source data.
// Related Articles
- [RSCH]
Program-as-Weights turns prompts into reusable tools
- [RSCH]
LACUNA tests whether LLM unlearning really erases
- [RSCH]
Persistent-state AI agents open a new attack surface
- [RSCH]
Language critiques improve imitation learning
- [RSCH]
One Transformer Layer Can Carry RL Gains
- [RSCH]
BINEVAL uses binary questions to score LLM outputs