One Transformer Layer Can Carry RL Gains
A layer-wise RL study finds that training one transformer layer can recover most post-training gains.

Training one transformer layer can recover most of the gains from full RL post-training.
- Research org: Unspecified in arXiv abstract
- Core data: Seven models
- Breakthrough: Measure “layer contribution” by isolating RL updates to one layer
For engineers working on LLM post-training, this paper points to a simple but important possibility: you may not need to update every parameter to get most of the benefit from reinforcement learning. The authors study where RL gains actually land inside a transformer and find that the effect is concentrated, not evenly spread.
The paper is Is One Layer Enough? Training A Single Transformer Layer Can Match Full-Parameter RL Training, and its core message is practical: if RL adaptation is mostly carried by a small slice of the network, then training strategy, compute budget, and debugging all change. That matters whether you are trying to reduce post-training cost or understand why a model improves on one task but not another.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most RL post-training setups for large language models update all parameters uniformly. That assumes every transformer layer contributes roughly equally to the gains you get from RL. The authors argue that this assumption has not been well understood, so they run a systematic layer-wise study to see where the improvement actually comes from.
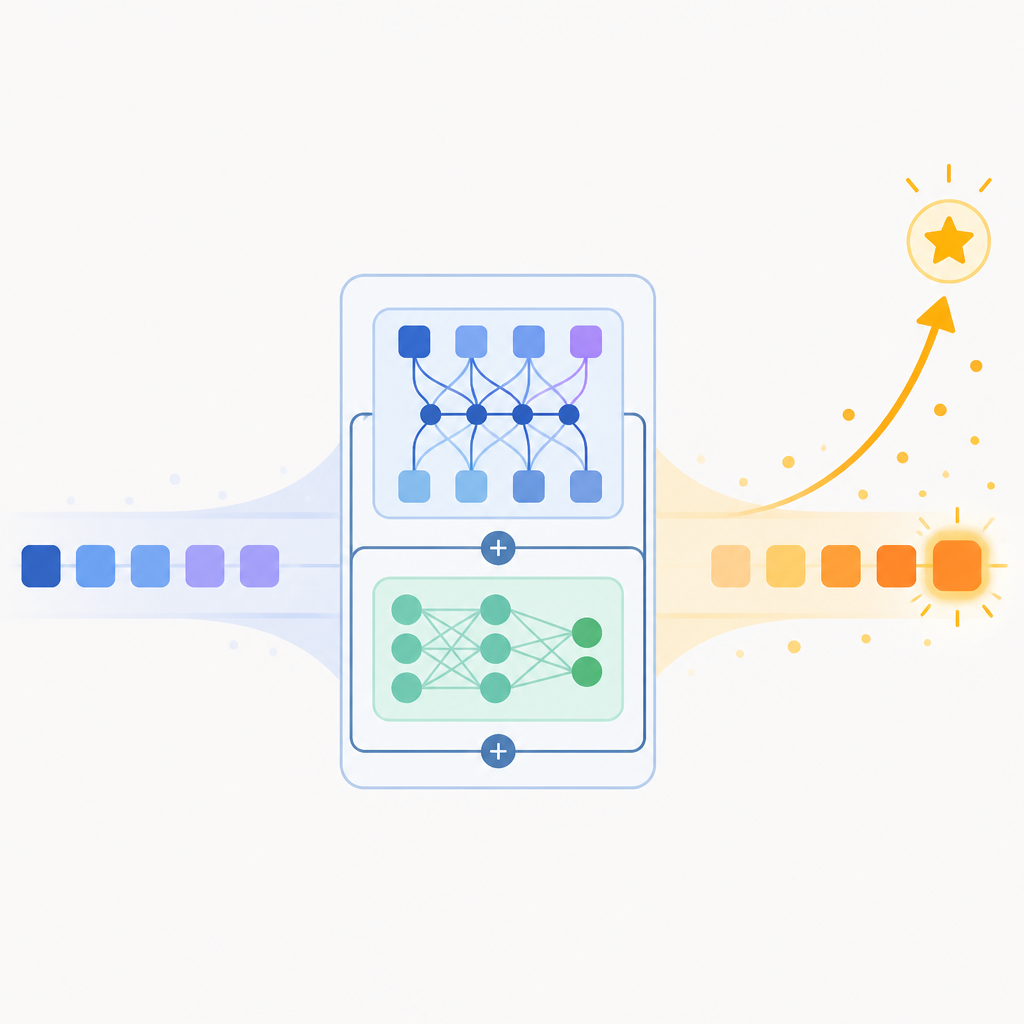
That question matters because RL post-training is expensive and often opaque. If only a few layers matter, then full-parameter training may be doing a lot of unnecessary work. If the useful signal is concentrated in a predictable part of the stack, that also gives researchers a cleaner way to study model behavior.
How the method works in plain English
The paper introduces a quantity called layer contribution. In simple terms, it measures how much of the improvement from full RL training you can recover by training one layer in isolation. Instead of asking, “Did the whole model get better?”, the authors ask, “Which layer is actually doing the heavy lifting?”
They test this idea across seven models from two model families, Qwen3 and Qwen2.5. They also cover three RL algorithms: GRPO, GiGPO, and Dr. GRPO. The task mix includes mathematical reasoning, code generation, and agentic decision-making, so this is not a single-task curiosity.
The method is straightforward but revealing: train layers separately, compare each layer’s isolated gain to the full RL gain, and rank layers by how much they contribute. The paper then checks whether those rankings stay stable across datasets, tasks, model families, and RL algorithms.
What the paper actually shows
The main finding is surprising in its simplicity: training a single transformer layer can recover most of the gains from full-parameter RL training, and in some cases even surpass it. The paper does not give benchmark numbers in the abstract, so it is not possible to quote exact scores here. But the qualitative claim is strong: RL gains are highly concentrated.
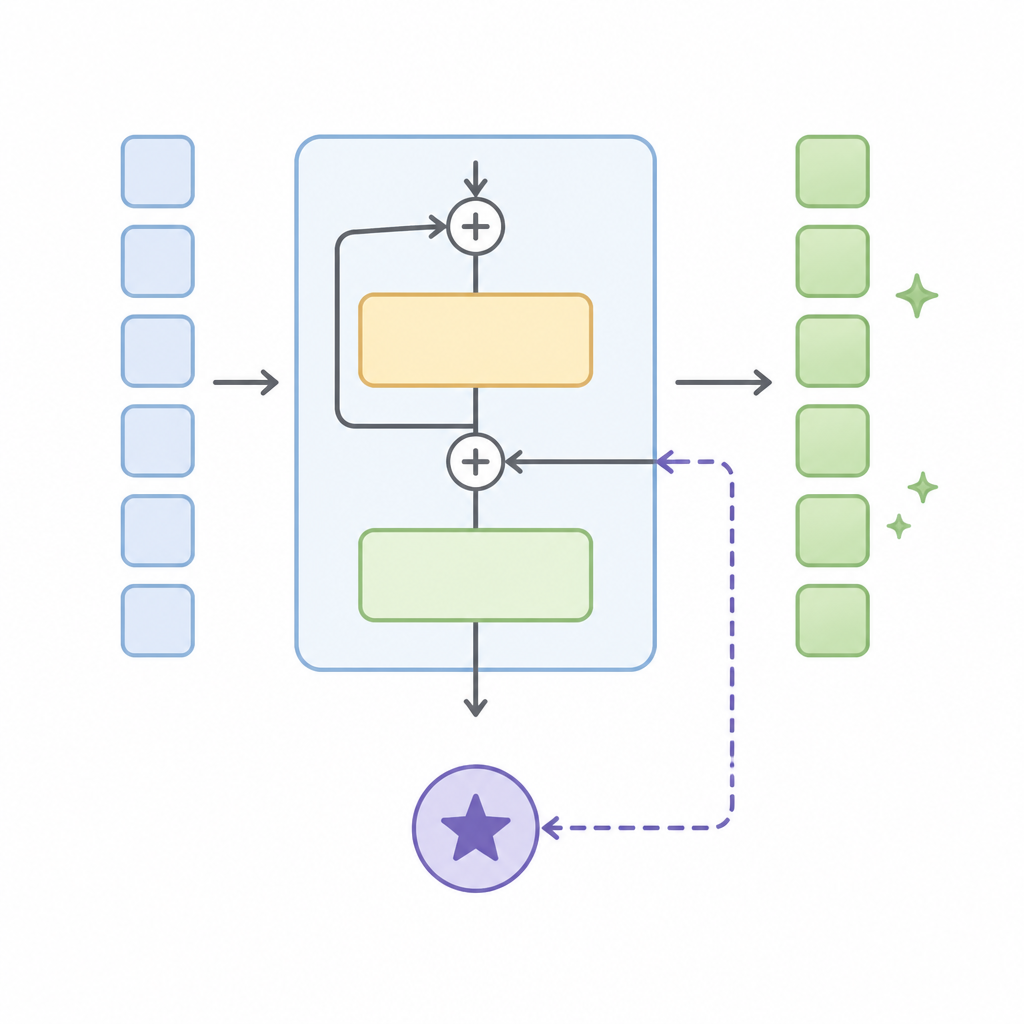
That concentration does not look random. The authors report a stable structural pattern in which high-contribution layers tend to sit in the middle of the transformer stack, while layers near the input and output ends contribute much less. In other words, the model’s RL adaptation appears to cluster around the middle rather than being evenly distributed from bottom to top.
They also say the resulting layer rankings remain strongly correlated across datasets, tasks, model families, and RL algorithms. That is important because it suggests the pattern is not just an artifact of one benchmark or one training recipe. The same broad structure shows up repeatedly across the experiments they ran.
Why developers should care
If this result holds up beyond the paper’s setup, it could reshape how teams think about RL post-training. A smaller trainable subset could mean lower compute cost, simpler experimentation, and faster iteration when tuning models for reasoning, coding, or agentic behavior.
It also gives practitioners a new diagnostic lens. Instead of treating the transformer as a black box, you can ask which layers are responsible for a given RL improvement. That could help with debugging training instability, comparing algorithms, or designing more targeted adaptation methods.
There is also a software-engineering angle. If only a subset of layers matters, then selective fine-tuning, parameter-efficient training, or layer-specific scheduling may be worth exploring more aggressively. The paper does not claim those methods are solved here, but it gives a concrete signal that the usual “update everything” default may be overkill in some RL settings.
What this paper does not prove
The abstract is clear about the broad pattern, but it does not provide benchmark tables, exact recovery percentages, or compute savings. So while the qualitative result is compelling, the magnitude of the effect is not quantified in the source text available here.
It is also worth being careful about scope. The study covers seven models, two Qwen families, three RL algorithms, and several task domains, which is a solid spread, but it is still a specific slice of the LLM ecosystem. The paper shows a stable pattern within that slice; it does not claim that every transformer, every training recipe, or every downstream use case will behave the same way.
Still, the engineering takeaway is hard to ignore: RL gains may be much more localized inside the network than most training pipelines assume. If you are building or optimizing post-training workflows, that is exactly the kind of result worth testing in your own stack.
Bottom line
This paper argues that RL adaptation in transformers is concentrated in a small number of layers, often just one, with the middle of the stack doing most of the work. For anyone shipping or tuning LLMs, that is a strong hint that full-parameter RL may not always be necessary to get useful post-training gains.
- RL gains are not spread evenly across transformer layers.
- Middle layers tend to carry the strongest contribution.
- The paper suggests a path toward cheaper, more targeted RL post-training.
// Related Articles
- [RSCH]
Language critiques improve imitation learning
- [RSCH]
BINEVAL uses binary questions to score LLM outputs
- [RSCH]
RLMF teaches LLMs to express uncertainty better
- [RSCH]
QVal tests dense supervision before training
- [RSCH]
Self-Explanation Training Still Tracks Model Behavior
- [RSCH]
WorldEvolver lets LLM agents revise foresight