Fine-Tuning LLMs Locally: SFT, LoRA, DPO
LLM Configurator’s Guide 13 explains when to fine-tune, how SFT, LoRA, and DPO differ, and how to prepare and evaluate datasets.

LLM Configurator’s Guide 13 explains local LLM fine-tuning with SFT, LoRA, and DPO.
On June 15, 2026, LLM Configurator published Guide 13 on local fine-tuning for large language models. The guide walks through when tuning is worth the cost, how TRl-based DPO fits in, and how to run SFT and LoRA workflows with working code.
| 項目 | 數值 |
|---|---|
| Guide | 13 |
| Last updated | June 15, 2026 |
| Suggested holdout | 10% |
| Very small dataset threshold | < 50 examples |
| Typical epochs | 1–3 |
What changed
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The guide frames fine-tuning as a last-mile tool, not a default fix. It says to try prompting first, then RAG for knowledge-heavy tasks, and only then fine-tune when you need stable style, domain language, lower latency, or behavior that prompts cannot reliably produce.
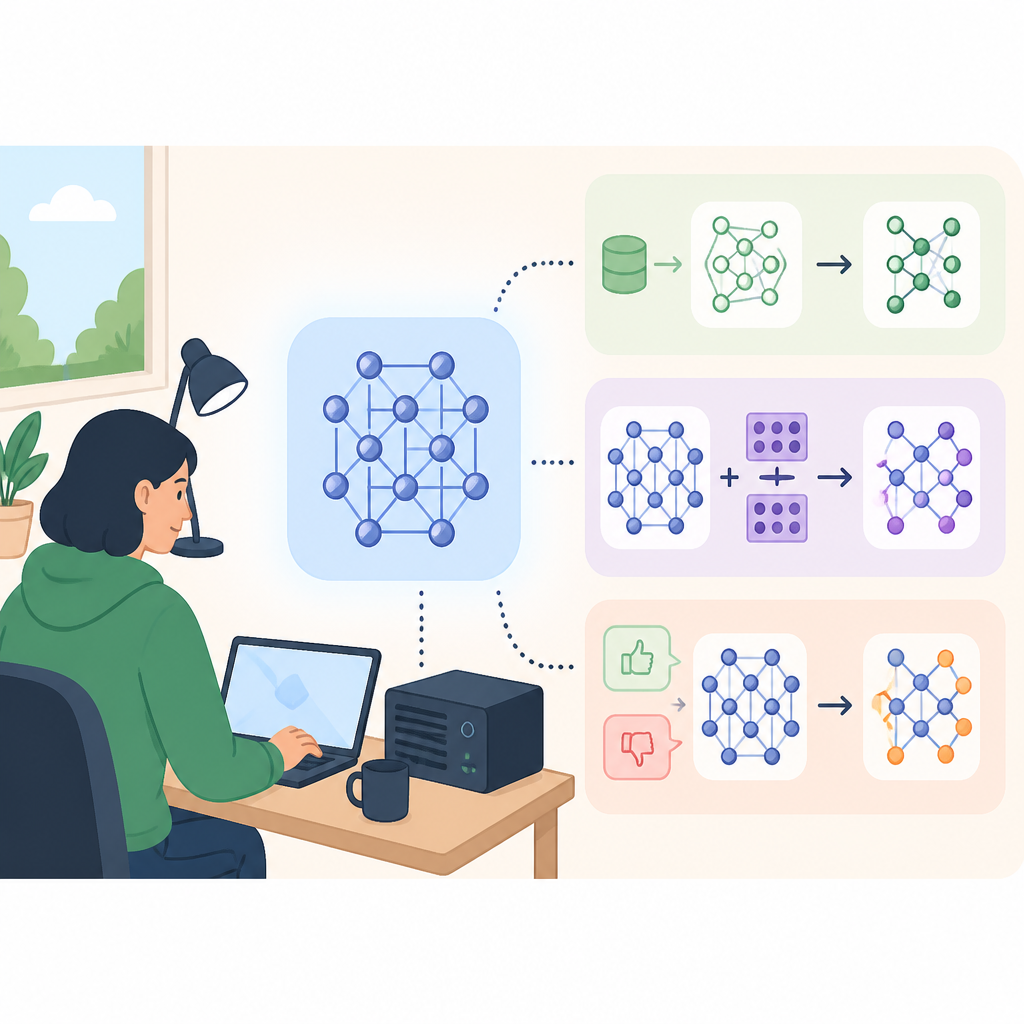
It also separates the main paths developers can use locally:
- SFT for supervised learning on instruction-response pairs.
- LoRA for lighter-weight adapter training.
- DPO for preference-based alignment.
- LLaMA-Factory as a GUI option for teams that do not want to live in notebooks and scripts.
For data prep, the guide pushes simple checks that prevent wasted runs: validate JSONL files, keep a 10% eval split, and choose a base model already close to the task. It warns that tiny datasets, wrong formats, and overtraining are the most common reasons a tune fails.
Why it matters
For developers, the practical value is speed: the guide narrows the decision tree before training starts. That can save GPU time, reduce bad runs, and keep teams from using fine-tuning to solve problems that prompting or retrieval can handle faster.
For the market, this kind of tutorial lowers the barrier to local model customization. Teams building support bots, extraction pipelines, or domain assistants can use the same playbook to get more consistent output without sending data to a hosted API.
The main takeaway is simple: fine-tuning is useful, but only after the cheaper options fail. The real question for most teams is not whether to tune, but whether the task needs new behavior or just better prompting and retrieval.
// Related Articles
- [TOOLS]
瑞萨全资收购Altium,PCB设计工具更新
- [TOOLS]
Rust forum week 25 turns ideas into shipping work
- [TOOLS]
Claude Code Rust trims TUI overhead to one binary
- [TOOLS]
Open source tools that make vibe coding safer
- [TOOLS]
Model triage turns coding tests into a cost win
- [TOOLS]
Vercel’s eve turns agents into directories