Grok Build Adds /goal for Autonomous Coding
xAI’s Grok Build now has /goal, a mode that plans, executes, and verifies coding tasks on the developer’s machine.

xAI’s Grok Build now has /goal, a mode that plans, executes, and verifies coding tasks on the developer’s machine.
xAI shipped /goal in Grok Build on June 22, 2026, and the pitch is simple: give the agent one objective, then let it run until it can prove the job is done. That puts Grok Build into a tighter race with Claude Code and OpenAI Codex CLI, but with a more aggressive autonomy story.
What makes this launch worth paying attention to is the verification loop. A lot of coding agents can edit files and summarize what they changed. Fewer can keep working until they test the result, inspect the output, and fix their own mistakes before handing control back.
| Metric | Value | What it means |
|---|---|---|
| /goal launch date | June 22, 2026 | Autonomous mode is live now |
| SuperGrok | $30/month | Lowest entry tier for Grok Build |
| X Premium Plus | $40/month | Another access path to the CLI |
| SuperGrok Heavy | $300/month | High-usage tier |
| Grok Build 0.1 context window | 256,000 tokens | Large enough for long sessions |
| Earlier SWE-Bench Verified score | 70.8% | Benchmark baseline for xAI’s coder |
| Claude Code Opus 4.7 score | 87.6% | Competitive benchmark target |
What /goal actually changes
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Standard coding agents still work like a chat loop. You ask for a change, the model writes code, you review the result, and the next prompt comes from you. /goal changes that rhythm by turning one prompt into a bounded task with its own checklist, progress panel, and completion test.

That matters because developer time is often lost in the handoff between generation and verification. A model can produce code that compiles and still ship a broken feature. xAI is trying to move the verification step inside the agent itself, so the system keeps iterating until it can defend its own output.
The feature also keeps the human in the loop in a lighter way. Developers can check live status, pause the run, resume it, cancel it, or add new instructions while the agent works. The difference is that they no longer have to approve every step of the task.
- /goal status shows live progress
- /goal pause stops execution temporarily
- /goal resume continues the run
- /goal clear cancels the task
Verification is the real headline
xAI says /goal can verify work in three ways: by reviewing the code it produced, by inspecting web pages to confirm runtime behavior, or by running scripts directly. That is a smarter design than a simple “done” message, because it gives the agent a chance to catch failures before the developer does.
That approach tackles a common weakness in first-wave coding agents. They often look productive, but their confidence is higher than their accuracy. The new mode tries to reduce that gap by forcing a proof step before completion.
“Coding agents are becoming the procurement front where AI labs compete to own the developer workflow.” — Mitch Ashley, VP and practice lead for software lifecycle engineering at The Futurum Group
Ashley’s point is worth sitting with. The competition is no longer just about who can write the best snippet. It is about who can own the way teams plan, test, and ship software every day.
There is still an open question here: can a model verify work it was also responsible for generating? If the generator and verifier are too similar, the check can become shallow self-approval. xAI has not published enough detail to prove that /goal avoids that trap.
The two-model setup and why it matters
/goal uses both Grok Build 0.1 and Composer 2.5. xAI says one model handles planning and instruction-following while the other handles code generation and execution. On paper, that split sounds sensible: one model reasons about the task, the other does the mechanical work.
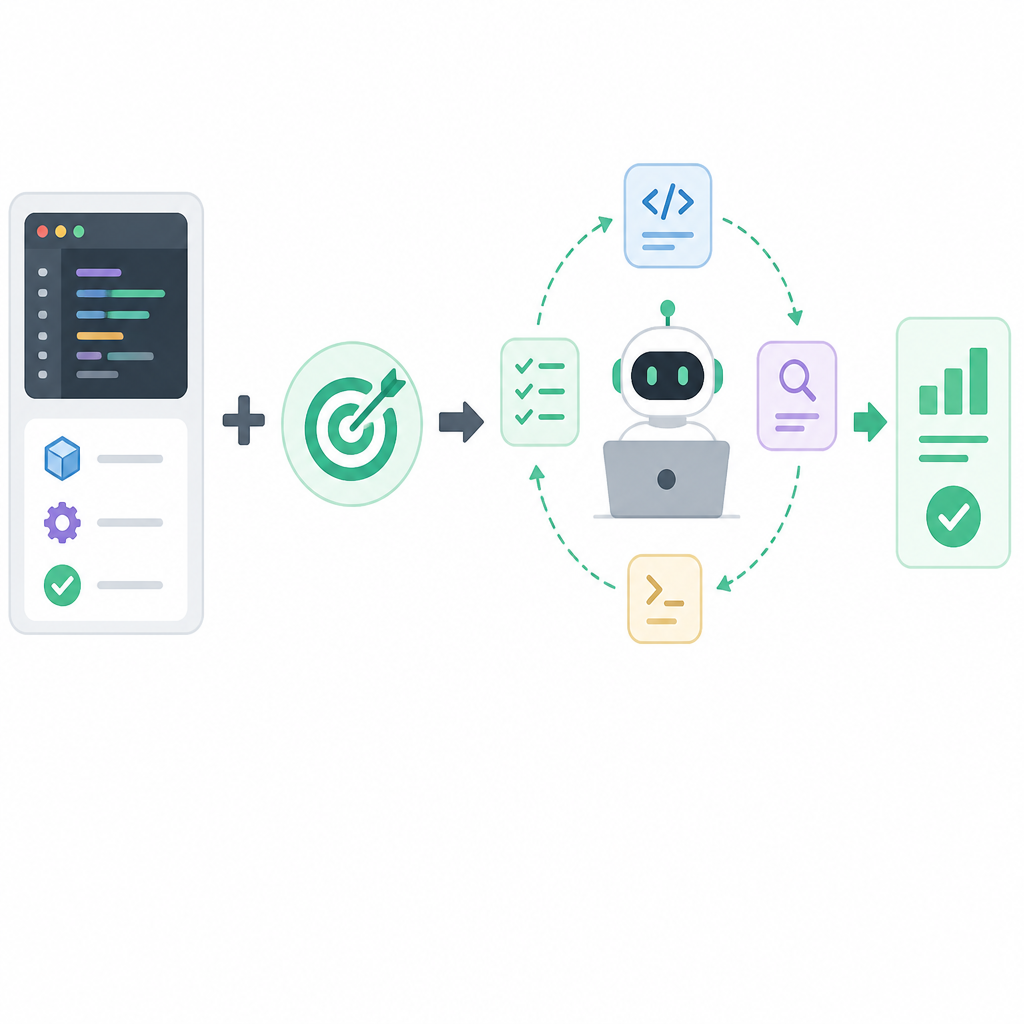
The catch is independence. If both models share similar training signals and failure modes, the verifier may miss the same bugs the generator misses. That is why production testing matters more than the architecture diagram. Developers will find out quickly whether the second pass catches real mistakes or just echoes the first pass with cleaner wording.
There is one practical detail that gives Grok Build a real security argument: all code runs on the developer’s local machine. Nothing in the codebase is sent to xAI’s servers during a session. For teams in finance, healthcare, or government, that local-first approach can matter as much as raw model quality.
- xAI docs describe the CLI workflow and access tiers
- Codex CLI is one of the main alternatives
- Claude Code still leads on benchmark reputation
- Gemini Code Assist is another enterprise option
How Grok Build compares with the competition
The benchmark numbers are the part xAI cannot ignore. The earlier grok-code-fast-1 model scored 70.8% on SWE-Bench Verified. Claude Code on Opus 4.7 scores 87.6% on the same benchmark. xAI has not published a fresh score for the current production grok-build-0.1 model.
That gap is large enough that no one should pretend Grok Build has already caught up on raw coding skill. What xAI is arguing instead is that long-running autonomous execution changes the question. If the agent keeps testing and fixing until the output works, the final result may matter more than a single benchmark pass.
That is a fair argument, but it needs proof in real projects. Benchmarks still matter because they predict how often an agent gets stuck, hallucinates a fix, or misses edge cases. A stronger workflow can hide some weakness, but it cannot erase it.
- Grok Build: 70.8% SWE-Bench Verified on the earlier coder model
- Claude Code: 87.6% on SWE-Bench Verified
- Context window: 256,000 tokens for Grok Build 0.1
- Access cost: $30, $40, or $300 per month depending on tier
One more competitive wrinkle: xAI is also planning Arena Mode, which would run multiple agents in parallel and pick the best output. If that ships, Grok Build could compensate for weaker single-run performance by choosing among several attempts instead of trusting one answer.
What developers should watch next
The most interesting test is not whether /goal sounds impressive in a demo. It is whether it reduces the number of times a developer has to reopen a task because the agent said “done” too early. That is the kind of failure mode teams feel immediately.
Grok Build is now moving fast enough that the product story is changing every few weeks: beta launch, Composer 2.5, plugin marketplace, and now autonomous execution. The pace suggests xAI wants Grok Build to become a daily coding tool, not just a novelty CLI.
My read is simple: /goal is a meaningful product step, but it is not a verdict on xAI’s coding quality. The next few weeks of real-world use will tell us whether the verification loop is genuine or just a nicer wrapper around the same old agent mistakes. If you are evaluating coding agents for a team, the right question is whether the tool can finish a task without making you become the test runner.
For OraCore readers, this is the feature to watch: if /goal can reliably close the loop on local code changes, xAI may have found a workflow advantage even before it closes the benchmark gap.
// Related Articles
- [AGENT]
Set Up AI Agent Workflows in 5 Practical Steps
- [AGENT]
Anthropic’s Claude Tag Research turns Slack into search
- [AGENT]
This benchmark proves harness quality beats model hype in coding
- [AGENT]
GLM-5 Is Right to Kill Vibe Coding and Push Agent Engineering
- [AGENT]
Loop Engineering: Claude Code背后的新工作法
- [AGENT]
Fable 5 ban exposed a model-routing race