HaWoR turns hand motion into MANO params
HaWoR’s hand reconstruction setup boils down to predicting MANO parameters, not raw meshes.

HaWoR turns hand motion reconstruction into MANO parameter prediction.
I've been around hand reconstruction pipelines long enough to know when something is pretending to be simpler than it is. You wire up a model, feed it video, and on paper it “reconstructs hands.” In practice, you’re juggling pose, shape, camera space, temporal drift, and the usual mess of occlusions. And then there’s the part that keeps annoying me: everyone acts like the output is the hard part, when the real trick is deciding what representation you trust in the first place.
That’s why the HaWoR write-up on Zhihu caught my attention. The post is short, but it points straight at the thing almost every modern hand method quietly depends on: MANO. Once you see that, a lot of the rest stops looking magical and starts looking like engineering choices around one shared hand model.
Stop thinking in meshes first
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
MANO(Model of Articulated and Non-rigid defOrmations,全称 “hand Model with Articulated and Non-rigid defOrmations”)是手部重建领域最广泛使用的参数化模型,几乎所有现代方法(包括 HaWoR、HaMeR 等)都以预测 MANO 参数作为输出。
What this actually means is: most hand reconstruction systems are not trying to predict a free-form hand mesh from scratch. They are trying to predict a compact set of MANO parameters, and then let the model turn those into a hand mesh for you.
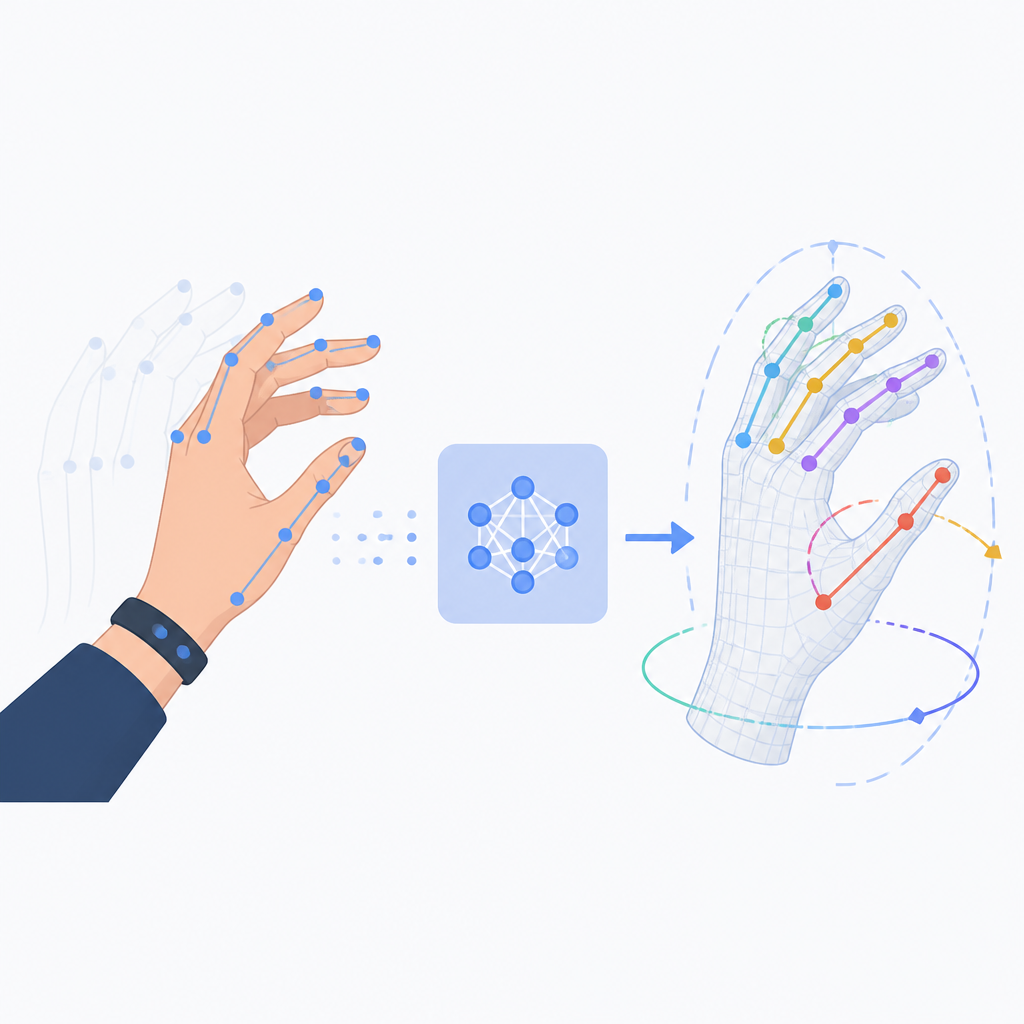
I ran into this exact shift when I first tried to compare different hand models. If you compare raw vertices directly, everything feels noisy and impossible to reason about. But once you compare pose parameters, shape coefficients, and camera transforms, the whole stack becomes much easier to debug. You stop asking “why is this mesh weird?” and start asking “which parameter is off?” That’s a much better question.
MANO is basically the shared language here. If you want the canonical reference, the original project page is still the cleanest place to start: MANO. For a broader implementation context, I also keep an eye on SMPL-X, which wraps a family of body models including MANO.
How to apply it: when you’re reading a paper or implementing a hand pipeline, write down the exact outputs. If the model predicts MANO pose, shape, and camera, treat everything else as derived. Don’t build your debugging workflow around mesh vertices unless you have to. It’s the fastest way to make a simple problem feel impossible.
- Pose tells you how the fingers are articulated.
- Shape tells you the person-specific hand geometry.
- Camera or global transform tells you where the hand sits in the image or world.
MANO is the contract everyone quietly signs
There’s a reason this model keeps showing up in papers like HaMeR and in the HaWoR discussion. It gives everyone the same output schema. That means one model can focus on image understanding, another can focus on temporal smoothing, and a third can focus on fitting or refinement, but they all speak the same downstream format.
That matters more than people admit. I’ve seen teams spend weeks arguing about architecture when the real issue was output compatibility. One model emitted a dense mesh, another emitted joint positions, and a third emitted MANO parameters. Then they wondered why evaluation and post-processing were a pain. Of course it was a pain. They had three different contracts and pretended they were interchangeable.
What this actually means is that MANO is less like a feature and more like an interface. If your system uses MANO, you get a lot for free: a prior over plausible hand shapes, a consistent topology, and a standard way to compare results. You also inherit its limits. If your target motion falls outside what MANO can represent well, you’re not just “slightly off,” you’re boxed in by the model.
How to apply it: if you’re building a hand system, decide early whether MANO is your final output or just an internal representation. If it’s internal, document the conversion step. If it’s final, make your evaluation and visualization tooling read MANO directly. That saves a ridiculous amount of glue code later.
- Use MANO when you want comparability across papers and datasets.
- Avoid hiding MANO behind too many custom wrappers.
- Keep a direct path from parameters to rendered hands for sanity checks.
Why HaWoR can focus on motion instead of geometry trivia
HaWoR’s name tells you where the interesting part is: world-space hand motion reconstruction. In plain English, that means the system cares about how the hand moves in 3D space, not just what the hand looks like as a static shape. Once you accept MANO as the output target, the job becomes about recovering motion fields, trajectories, and pose changes in a consistent coordinate system.
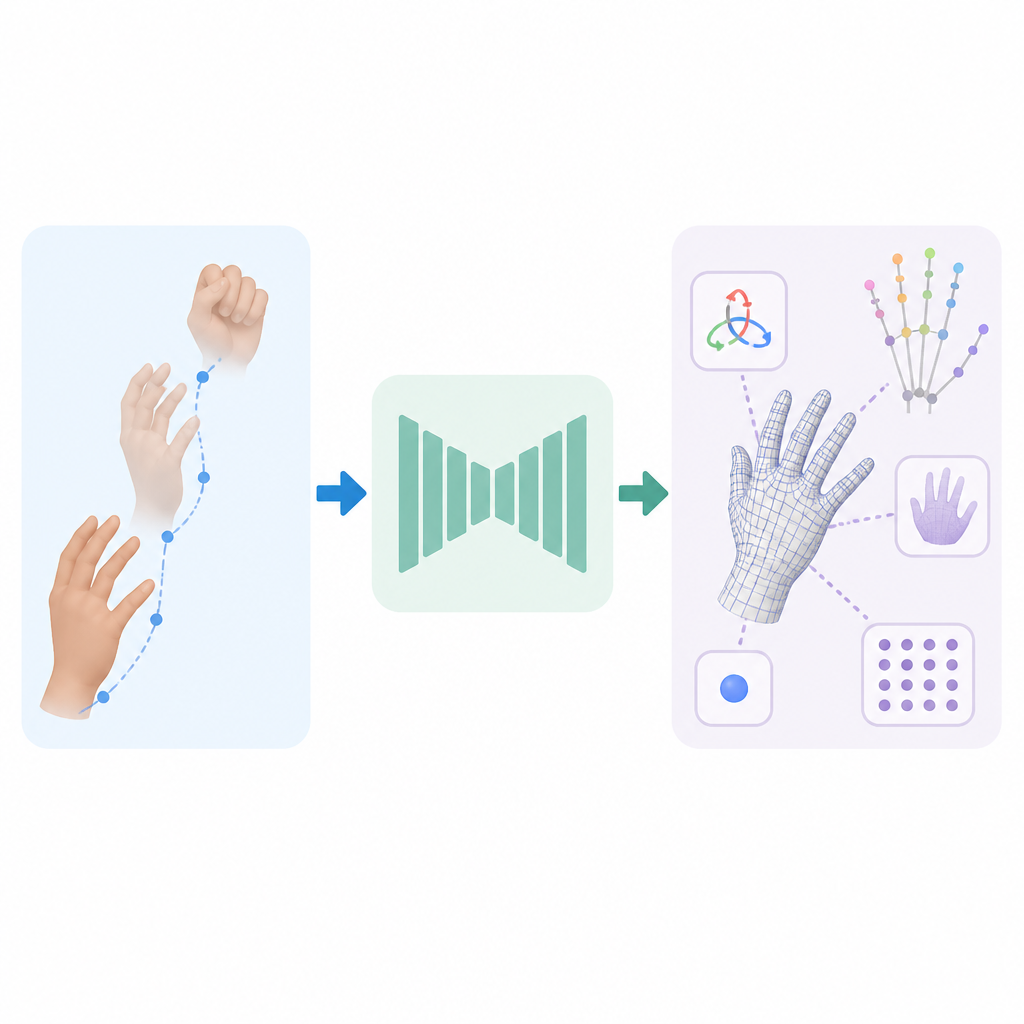
That is a much more sensible framing than trying to infer every surface detail directly from pixels. I’ve been burned by the opposite approach before. It looks elegant in a demo, then collapses when the hand leaves the center of the frame, gets partially occluded, or rotates into a view the model barely saw during training. Motion-first thinking gives you a better handle on those failure modes.
What this actually means is that world-space reconstruction is about stability over time. If the hand moves from left to right across frames, the model should track that motion in a physically coherent way, not just output a fresh guess each frame and hope the viewer won’t notice the jitter. MANO helps because it keeps the shape space constrained while the motion estimation does the heavy lifting.
How to apply it: if you’re implementing a temporal hand pipeline, separate the “where is the hand?” problem from the “what shape is the hand?” problem. Use the world-space or camera-space prediction to anchor motion, then use MANO to generate the mesh. That split makes it much easier to diagnose drift, scale errors, and frame-to-frame instability.
For practical reference, I’d also compare this kind of setup with the broader hand pose ecosystem around hand tracking toolkits and reconstruction codebases, because the same representation tradeoffs keep coming back.
The real value is not the hand model, it’s the prior
People love to talk about “better predictions,” but the hidden win here is the prior. MANO constrains the solution space. That’s the whole point. Instead of letting the network invent impossible finger bends or grotesque surface warping, you force it to stay inside a learned hand manifold.
I’ve seen this save models from embarrassing outputs more times than I can count. Without a prior, a network can fit training data and still produce nonsense under slight distribution shift. With a prior, you at least get something anatomically plausible most of the time. Not perfect. Just less absurd. And in this field, that already feels like a win.
What this actually means is that MANO is doing regularization work. It is not just a data format. It biases the model toward hands that look like hands. That bias is valuable, but it comes with a catch: you can’t expect the model to represent every weird glove, object interaction, or extreme finger articulation equally well.
How to apply it: when you evaluate a MANO-based model, don’t just look at vertex error. Check whether the hand is plausible under occlusion, whether finger ordering stays stable, and whether temporal motion remains smooth. A low numeric error can still look awful if the prior is being abused.
Useful links for this part: the original MANO page at mano.is.tue.mpg.de, the SMPL-X repository, and the HaMeR paper for a modern example of MANO-based hand reconstruction.
Why the output space matters more than the architecture
Here’s the part I wish more people said plainly: architecture debates are often secondary to representation choice. You can stack transformers, CNNs, temporal modules, and attention blocks all day. If the output space is wrong, the whole thing still feels wrong.
That’s why the HaWoR summary is useful even though it’s short. It reminds you that the dominant hand reconstruction path is not “predict pixels, then hope.” It is “predict MANO parameters, then decode.” That one choice makes training, evaluation, and downstream use much more predictable.
What this actually means is that your model’s job is to estimate a compact latent description of the hand, not to memorize surface detail. That changes how you design losses, how you sample training data, and how you think about failure cases. You can add bells and whistles later. If the representation is wrong, the bells just ring louder when the system fails.
I ran into this in a prototype where the model looked great on centered hands and fell apart on side views. The issue wasn’t just the backbone. It was that we were treating a geometry problem like an image regression problem. Once we switched the target to a structured hand model, the debugging story got much cleaner.
How to apply it: before you touch the architecture, write down the output representation on a whiteboard. Ask three questions: can it express the motion I care about, can I evaluate it cleanly, and can I render it back into something humans can inspect? If the answer to any of those is no, fix the representation first.
What I’d actually copy into a hand pipeline
If I were building a new hand reconstruction system today, I would not start by inventing a custom mesh head. I’d start with MANO, define the motion target clearly, and keep the world-space transform explicit. That gives me a sane baseline and stops me from wasting time on representation bugs disguised as model bugs.
What this actually means is that the pipeline should be boring in the right places. The network can be fancy. The output contract should not be. The model predicts MANO parameters, the renderer turns them into meshes, and the evaluation code checks motion consistency and plausibility. That separation is what keeps the project from turning into a pile of ad hoc post-processing scripts.
How to apply it: use a single config that names the pose dimension, shape dimension, and camera/world transform. Keep a renderer in the loop. Save intermediate MANO parameters every time you run validation. If something looks off, you want to inspect the numbers, not just stare at a video and guess.
And yes, I still think the field leans too hard on pretty demos. A hand reconstruction system that can’t explain its own output representation is one bad frame away from becoming a guessing game.
The template you can copy
# Hand reconstruction pipeline using MANO as the output contract
## Goal
Reconstruct hand motion in world space while keeping the final output in MANO parameters.
## Representation
- Pose: MANO pose parameters
- Shape: MANO shape coefficients
- Transform: camera or world-space hand transform
- Mesh: decoded from MANO only for visualization and evaluation
## Design rules
1. Predict structured parameters, not raw vertices.
2. Keep world-space motion explicit.
3. Render every validation run back into a mesh.
4. Debug pose, shape, and transform separately.
5. Treat MANO as the interface between the network and the rest of the pipeline.
## Practical checklist
- [ ] Load the official MANO model
- [ ] Confirm pose dimensions match your implementation
- [ ] Confirm shape coefficients are stable across frames
- [ ] Verify world-space motion does not drift
- [ ] Compare rendered meshes frame by frame
- [ ] Check plausibility under occlusion and side views
## Minimal pseudo-config
model:
output_representation: mano
pose_dim: <set_from_mano>
shape_dim: <set_from_mano>
space: world
training:
supervise_pose: true
supervise_shape: true
supervise_transform: true
render_validation_meshes: true
## Debug workflow
1. Inspect MANO parameters first.
2. Render the mesh second.
3. Check temporal consistency third.
4. Only then tune the backbone.
## Copy note
This template is a practical reconstruction scaffold based on the HaWoR Zhihu post and the MANO model it references.The original trigger here was the Zhihu post on HaWoR: World-Space Hand Motion Reconstruction. I used that as a springboard to break down the MANO-centered workflow; the template above is my own practical rewrite, not a verbatim copy of the source.
// Related Articles
- [RSCH]
Google DeepMind turns science into tools
- [RSCH]
Measuring when LLM behavior actually переносится
- [RSCH]
Prompt injection is now an AI security problem
- [RSCH]
Solver choice changes which Nash equilibrium wins
- [RSCH]
Proper positive-only learning gets a full characterization
- [RSCH]
DexCompose Reuses Dexterous Policies Across Tasks