RiVER trains LLMs without ground-truth answers
RiVER shows LLMs can improve from score-based tasks without ground-truth answers by calibrating rewards from execution feedback.

RiVER shows LLMs can improve from score-based tasks without ground-truth answers by calibrating rewards from execution feedback.
- Research org: Unspecified in arXiv abstract
- Core data: 8.9% ALE rating rank gain
- Breakthrough: Calibrated reward shaping with instance-wise comparisons
Most reinforcement-learning pipelines for code models assume you already know the right answer. That works for tasks with clean unit tests or exact labels, but it breaks down when the best solution is unknown and the only signal you have is how well a candidate performs. This paper argues that you can still train useful LLMs in that setting, as long as you turn execution feedback into a reward signal carefully.
The practical angle matters: many real coding and algorithmic problems are not neatly labeled in advance, and many useful optimization tasks are scored rather than judged against a single ground-truth output. RiVER is designed for exactly that gap. It tries to make reinforcement learning usable in places where the model can be evaluated, but not simply compared against a known correct solution.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Reinforcement learning with verifiable rewards, or RLVR, has become attractive for training LLMs because it gives the model a clear signal: reward correct outputs, penalize wrong ones. The catch is that this setup usually depends on ground-truth answers. If there is no known solution, the standard recipe stops being useful.
The authors focus on score-based optimization tasks, where the system can execute a candidate solution and get a deterministic score back. That is a different kind of supervision from exact-answer tasks. Instead of asking, “Is this output correct?”, the training loop asks, “How well did this candidate perform?”
That sounds straightforward, but the paper says naive use of those scores causes trouble when you apply group-relative RL. Two failure modes show up: scale dominance and frequency dominance. Scale dominance happens when raw score magnitudes vary so much across test instances that they distort updates. Frequency dominance happens when weaker solutions are sampled often enough that they can overpower rarer but better candidates.
How RiVER works in plain English
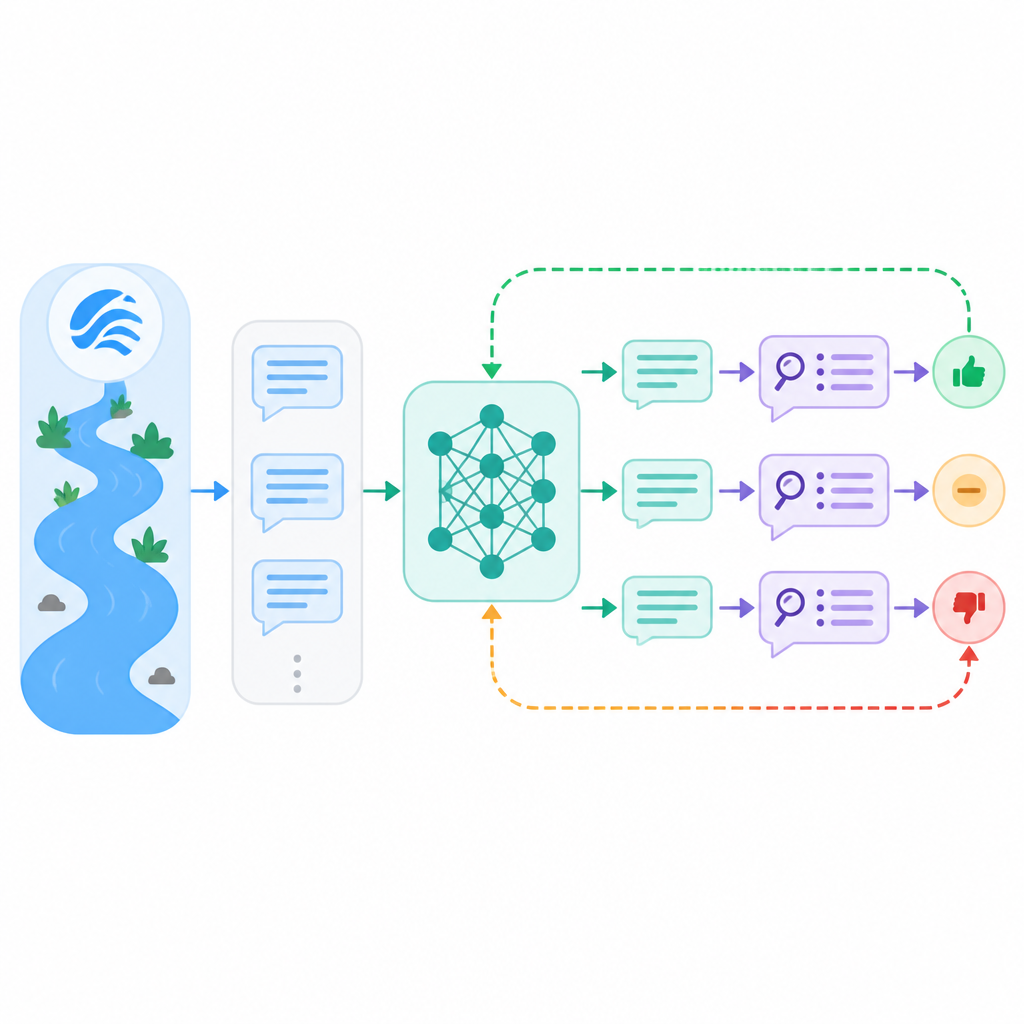
RiVER stands for Ranking-induced VERifiable framework. The core idea is to keep the reward signal grounded in execution feedback, but reshape it so the model learns from rankings instead of raw scores alone.
In the paper’s framing, the method uses calibrated reward shaping with instance-wise comparisons. That means the reward is adjusted relative to the specific problem instance, rather than treating every score as directly comparable across tasks. This is the key move for avoiding scale dominance.
RiVER also emphasizes top-ranked solvers while still keeping bounded feedback for other valid solutions. In other words, it does not flatten everything into a binary pass/fail signal, but it also does not let mediocre samples drown out stronger ones just because they appear more often. That is how it addresses frequency dominance.
The result is a training setup that can use continuous-valued supervision from deterministic execution feedback, even when there is no ground-truth solution to anchor the reward. For engineers, the interesting part is not just the reward function itself, but the fact that the paper treats reward calibration as the central problem, not an afterthought.
What the paper actually shows
The authors train on 12 AtCoder Heuristic Contest tasks and evaluate on Algorithm Engineering Benchmark, LiveCodeBench, and USACO. The abstract does not provide per-task breakdowns or full benchmark tables, so the paper’s headline claims are the main numbers we have here.
On ALE-Bench, RiVER improves Qwen3-8B and GLM-Z1-9B-0414 by 8.9% and 9.4% in ALE rating rank. That is the clearest reported benchmark result in the abstract, and it suggests the method is doing more than just fitting the training environment.
More importantly, the paper says the gains transfer beyond the score-based training tasks. Even though training uses only tasks without ground-truth solutions, RiVER also improves the backbones on exact-solution benchmarks. The abstract reports absolute average improvements of 2.4% on LiveCodeBench and 3.5% on USACO.
The contrast with baselines is a big part of the story. Baselines trained with raw execution scores improve ALE rating, but they fail to transfer to exact-solution benchmarks. That implies the calibration step is doing real work: without it, the model may learn to game the score environment without becoming broadly better at coding.
Why developers should care
If you build or tune code models, this paper points to a useful design principle: the training signal does not have to come from perfect labels. It can come from execution feedback, as long as the reward is shaped so the model can learn stable preferences from noisy or uneven score distributions.
That matters for domains where ground truth is expensive, incomplete, or simply unavailable. Algorithmic tuning, heuristic search, and other score-driven tasks often fit that profile. RiVER suggests those environments can still be productive RL training grounds for general coding ability.
There is also a cautionary takeaway. Raw scores are not automatically a good reward signal, even if they are deterministic. The paper’s two named pathologies show why: if you do not calibrate across instances and candidate frequencies, the policy updates can be skewed in ways that help the training metric but not the underlying model.
Limits and open questions
The abstract is strong on the method and headline results, but it leaves several details open. It does not give benchmark tables, training compute, sample efficiency, or ablation results in the text provided here. It also does not tell us how sensitive RiVER is to reward calibration choices or how broadly the method generalizes beyond the listed tasks.
Another open question is operational complexity. Instance-wise comparisons and ranking-based shaping sound sensible, but they may add implementation overhead compared with simpler score-based RL. The abstract does not say how expensive that is, so practitioners would need the full paper to judge deployment cost.
Still, the main contribution is clear: the paper argues that RL for LLMs does not need ground-truth answers to be useful. If you can execute candidate solutions and score them reliably, RiVER shows there is a path to turn that signal into broader coding gains without relying on exact labels.
Bottom line
RiVER is a reminder that the bottleneck in RL for LLMs is not only whether rewards are available, but whether they are shaped well enough to teach the right behavior. For developers working on code models, that opens up a larger class of training environments than exact-answer benchmarks alone.
- Score-based tasks can train LLMs even when no ground-truth solution exists.
- Reward calibration matters because raw execution scores can mislead policy updates.
- RiVER transfers from heuristic tasks to exact-solution benchmarks, not just the training set.
// Related Articles
- [RSCH]
Mistral OCR 4 brings structure to document AI
- [RSCH]
Autoregressive Boltzmann Generators ditch flows
- [RSCH]
DanceOPD distills image-editing skills into one model
- [RSCH]
Microsoft funds AI research on team collaboration
- [RSCH]
3 AI papers on code, music, and diagnosis
- [RSCH]
New NLP papers map agent memory and tool use