Skill-to-LoRA cuts agent token overhead
Skill-to-LoRA turns SKILL.md files into LoRA adapters so agents can load skills without stuffing long docs into context.

Skill-to-LoRA turns SKILL.md skill files into LoRA adapters and cuts prompt overhead.
Agent frameworks often ship skills as SKILL.md files, which means every run pays the cost of re-reading the same instructions. The paper behind arXiv:2606.16769 proposes a cleaner path: distill the skill text into a skill-specific LoRA adapter and load that at inference time instead of stuffing the whole document into the prompt.
That matters because long skill docs are expensive in token budget, slow down context assembly, and can crowd out the actual task. The idea is simple enough to explain at a coffee shop: read the skill once, train an adapter offline, then swap the adapter in when the agent needs that skill.
| Item | Value | Why it matters |
|---|---|---|
| Paper | arXiv:2606.16769 | Identifies the method and source |
| Method | Skill-to-LoRA (S2L) | Replaces text injection with adapters |
| Skill format | SKILL.md | Common file format in agent stacks |
| Training mode | Offline synthesis from full skill docs | Moves heavy lifting out of the request path |
| Runtime mode | Dynamic adapter loading | Reduces prompt length during inference |
What S2L is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core complaint is familiar to anyone who has built agent workflows: the model does not need a 2,000-word instruction file every single time if the skill is stable. The paper argues that SKILL.md distribution is convenient for humans but wasteful for inference, because the model keeps paying for the same context on every call.

LoRA fits this problem well because it encodes task behavior in a compact set of low-rank updates rather than in repeated text. S2L takes the skill document, uses it to synthesize demonstration data, and trains a skill adapter that can be loaded only when needed.
That shifts the cost curve. Instead of spending tokens on instructions every time, you spend compute once during preparation and keep the runtime request smaller.
- Less prompt stuffing during inference
- More room in context for user input and task state
- Cleaner separation between skill knowledge and live conversation
- Potentially higher pass rate if the adapter captures the skill better than raw text
Why the offline step matters
The offline stage is where S2L does the heavy work. The full skill document is used to create skill-guided demonstrations, and those examples train a dedicated adapter. In practice, that means the model learns the behavior behind the instructions instead of re-parsing the instructions every time.
This is a meaningful design choice because agent skills are often repetitive. A browser automation skill, a code review skill, or a file-editing skill tends to carry stable patterns. If those patterns can be distilled into weights, the runtime path gets simpler.
"LoRA is a low-rank decomposition that is learned alongside the original model weights and does not require inference latency." — Edward J. Hu et al., LoRA: Low-Rank Adaptation of Large Language Models
That quote matters here because it explains the technical bet. S2L is banking on the fact that adapters can store useful behavior without adding much runtime friction. The paper is less about a new model architecture and more about moving skill delivery from text to parameters.
If you want a broader context for agent design, this sits in the same conversation as tool-use systems and structured prompting. We covered related agent patterns in our recent agent tooling roundup.
What the numbers imply for builders
The source summary does not publish a full benchmark table, but it does give two signals that matter: the idea targets token reduction, and it claims a higher pass rate. Those are the right metrics for this kind of system, because a skill system only wins if it is cheaper and at least as reliable as prompt injection.
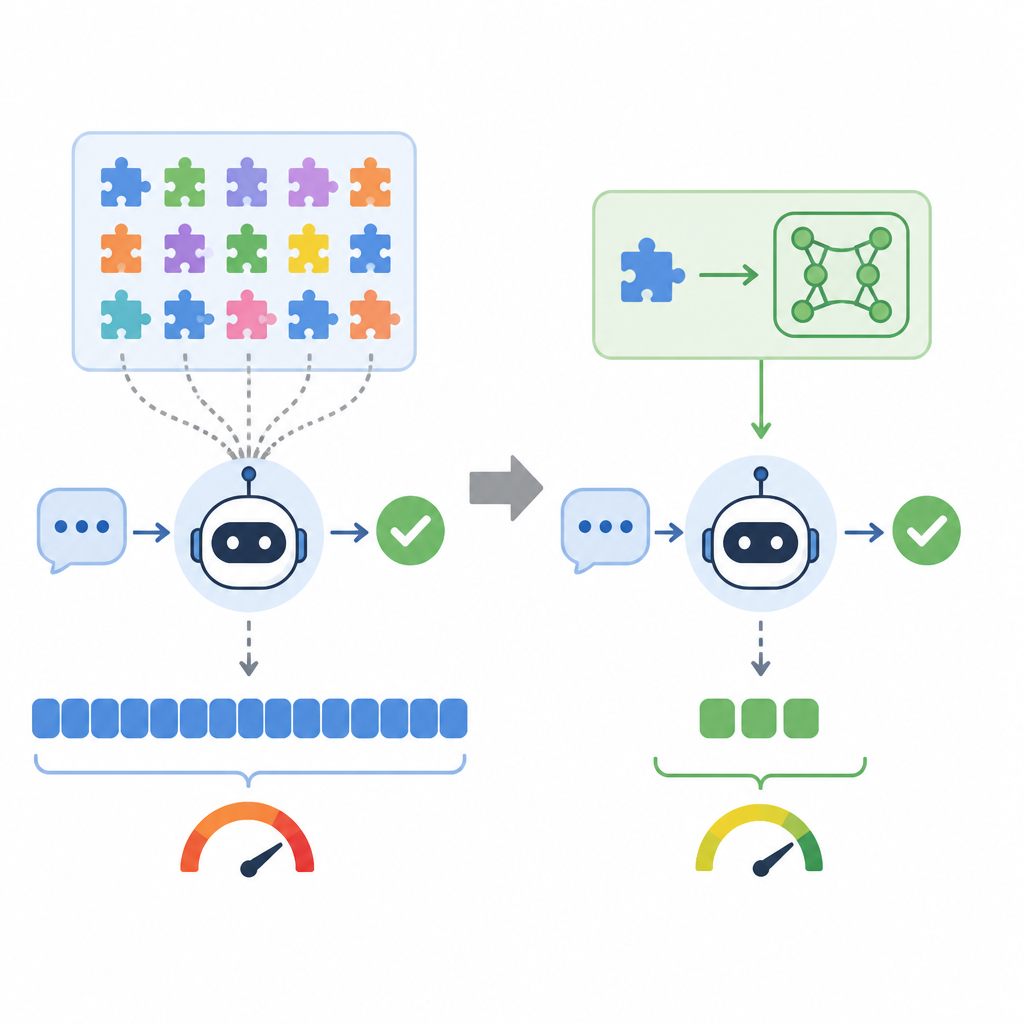
For builders, the comparison is straightforward. A text-based skill file is easy to inspect and edit, while an adapter-based skill is harder to read but cheaper to run. The tradeoff is between transparency and runtime efficiency.
- Prompt injection keeps skills human-readable but grows context length with every call
- Adapter loading keeps the prompt shorter but requires a training pipeline
- Text skills are easy to version in Git, while adapters need model artifact management
- Adapters can be swapped dynamically, which is useful when an agent needs many specialized behaviors
That last point is where S2L gets interesting for production teams. If you have dozens of skills, each with its own document, the prompt tax adds up fast. A library of adapters could be easier to load on demand than a wall of instructions appended to every request.
The catch is operational complexity. You now need a process for generating examples, training adapters, validating them, and matching the right adapter to the right task. That is a better fit for teams already running model infrastructure than for hobby projects that just want a quick agent demo.
Where this fits in the agent stack
S2L is part of a broader move to make agents less dependent on giant prompts and more dependent on reusable artifacts. The same pressure shows up in DSPy, in function-calling workflows, and in systems that separate planning from execution. The common thread is that prompt text is a brittle place to store everything.
There is also a nice practical angle here for teams shipping products. If a skill is stable enough to be distilled, it may belong in weights rather than in a markdown file. If a skill changes every week, the markdown file still wins because it is easier to edit and audit.
That split suggests a hybrid architecture: keep fast-changing policy in text, and move stable procedural skills into adapters. For agent builders, that may be the most realistic way to reduce token waste without turning every update into a model retraining job.
The paper’s idea is small, but the implication is large enough to matter: agent systems may start treating skill docs as training material, not runtime baggage. If S2L holds up in broader tests, the next question is practical, not theoretical: which skills belong in text, and which ones are worth turning into adapters?
// Related Articles
- [RSCH]
TurboQuant does not hurt search quality at equal byte budgets
- [RSCH]
Deterministic multicalibration finally hits optimal sample use
- [RSCH]
UNIEGO unifies egocentric video with proxy teachers
- [RSCH]
DiffusionGemma’s transparency problem, measured
- [RSCH]
Nitro’s split kernel turns isolation into math
- [RSCH]
Blackwell wins because agentic AI needs full-stack infrastructure