Skill-to-LoRA 讓技能別再吃 Token
Skill-to-LoRA 把 SKILL.md 轉成 LoRA adapter,讓 agent 不必每次把長文件塞進 context,降低 token 成本。

Skill-to-LoRA 把 SKILL.md 轉成 LoRA adapter,讓 agent 執行技能時少塞一大段提示詞。
說真的,這題很實際。很多 agent 每跑一次,就得重讀同一份技能文件。結果不是模型變笨,是 token 先爆掉。這篇看的是 arXiv:2606.16769 提出的 LoRA 版本技能載入法。
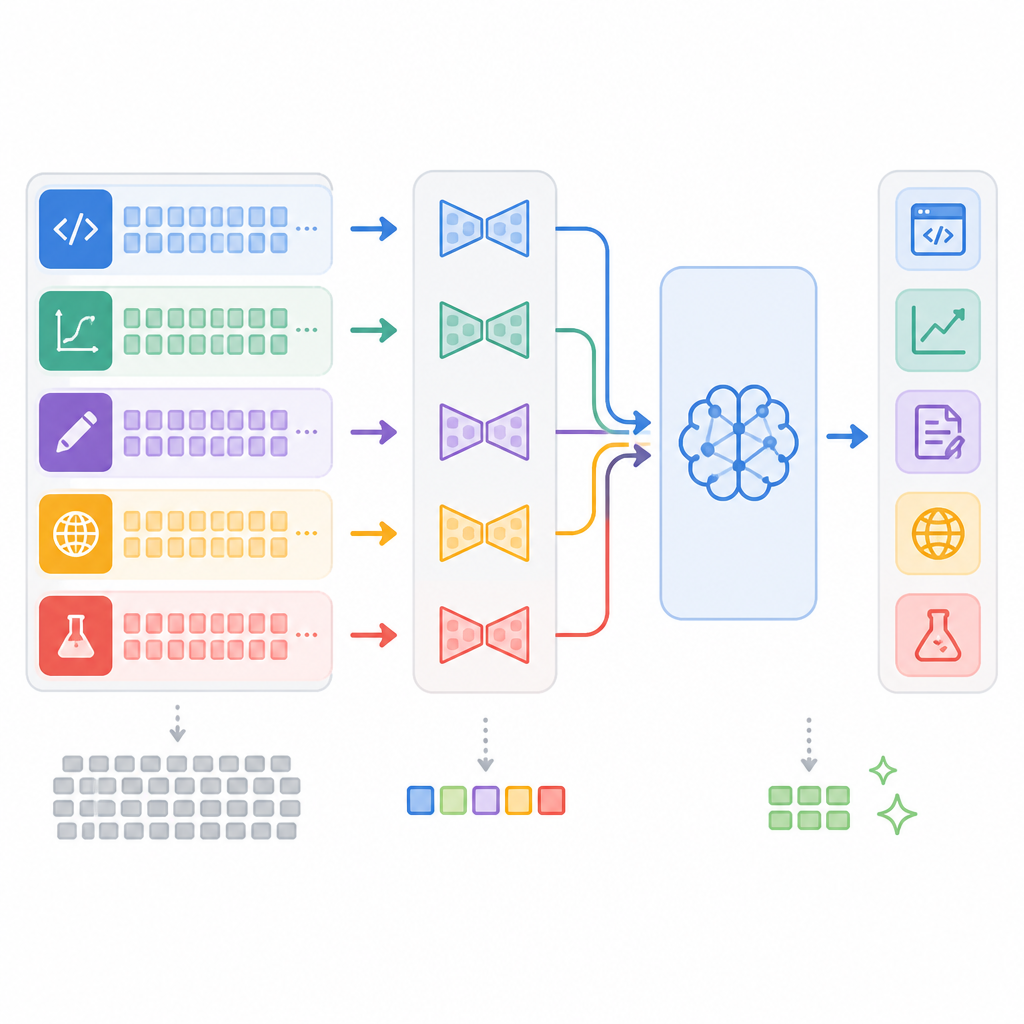
講白了,它想把 SKILL.md 從 runtime 文件,變成離線訓練出的 adapter。這樣 agent 需要技能時,不用把整份文件塞進 prompt。對長上下文很貴的 API 服務來說,這招很有感。
| 項目 | 數值 | 意義 |
|---|---|---|
| 論文 | arXiv:2606.16769 | 方法來源 |
| 方法名稱 | Skill-to-LoRA, S2L | 把文字技能轉成 adapter |
| 技能格式 | SKILL.md | 常見 agent 技能文件 |
| 基礎技術 | LoRA | 用低秩更新存技能行為 |
| 核心流程 | 離線合成示範資料 | 把 heavy lifting 移出請求路徑 |
它到底在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
很多 agent 架構都愛用 markdown 技能文件。好處很直觀,工程師看得懂,也好改。問題是,每次請求都把同一份說明重送一次,token 直接被吃掉。

這件事在小 demo 看不出來。可一旦技能文件變長,或者你同時掛了好幾個技能,context 就開始膨脹。模型真正要做的工作,反而被一堆說明文字擠壓。
Hugging Face PEFT 的 LoRA 很適合這種場景。它不是把整份技能文字背進 prompt,而是把行為壓進少量參數。S2L 的做法,就是先讀技能,再離線訓練 adapter。
- runtime 少吃一大段 prompt
- user input 有更多空間
- 技能和對話內容分開處理
- 適合穩定、重複的 agent 任務
離線訓練為什麼重要
S2L 的核心不是把文件壓縮而已。它是先用完整技能文件,合成示範資料,再拿這些資料訓練專屬 adapter。也就是說,模型學的是技能行為,不是每次都重新解析文字。
這個設計很像把說明書變成肌肉記憶。對 browser automation、code review、file editing 這種固定流程的技能,效果理論上會比純文字提示更穩。因為這些技能的模式本來就很重複。
你可能會想問,這跟直接寫 prompt 有什麼差。差在 runtime 成本。文字提示每次都要付 token,adapter 則是前面先花一次算力,之後載入就好。對大量請求的服務端,這筆帳差很多。
“LoRA is a low-rank decomposition that is learned alongside the original model weights and does not require inference latency.” — Edward J. Hu et al., LoRA: Low-Rank Adaptation of Large Language Models
這句話很關鍵。它點出 LoRA 的本質:把能力放進參數,不是放進長 prompt。S2L 只是把這個想法搬到 agent skills 上,方向很直白,也很工程化。
如果你想看更廣的 agent 工具路線,可以對照 DSPy 這類系統。它們都在想同一件事:別把所有東西都塞進 prompt。
數字上代表什麼
原始素材沒有完整 benchmark 表,但它已經透露兩個重點。第一,目標是減少 token overhead。第二,方法想提高 pass rate。這兩個指標很務實,因為 agent 系統最後就是看成本和成功率。
如果只看文字技能,優點是可讀、可審、可直接放 Git。缺點也很現實,就是每次執行都要重複付費。對 API 服務來說,這種重複成本很煩,尤其是高頻任務。
如果改成 adapter,runtime 會更乾淨,但你得多一條訓練管線。也就是說,你要管資料生成、adapter 訓練、驗證、版本控管。這不是玩票專案會想碰的東西。
- 文字技能:好讀、好改,但吃 context
- Adapter 技能:不好直接看,但 runtime 較省
- 文字方案:適合快速迭代
- Adapter 方案:適合穩定技能和大量請求
這裡最值得注意的,是它把技能管理從「每次請求都帶文件」改成「需要時載入能力」。對有十幾個、幾十個技能的團隊,這差別不是小修小補,是成本結構改寫。
但我也得吐槽一下。Adapter 不是萬靈丹。技能一變,還是得重訓或重做資料。若你的流程每週都在改,markdown 文件反而更靈活。工程上沒有白吃的午餐。
這在 agent 堆疊裡的位置
S2L 放在整個 agent stack 裡看,很像一種分層思路。穩定的程序技能,放進 weights。常改的政策、規則、偏好,留在文字層。這樣比較不會每次改一點點,就牽動整個模型流程。
這也跟 function calling、planning/execution 分離的方向一致。大家都在做同一件事:把長 prompt 拆掉。因為 prompt 不是資料庫,也不是版本控制系統。硬塞只會越來越醜。
實務上,我會把它看成 hybrid 架構的候選方案。哪些技能夠穩,就轉成 adapter。哪些內容常改,就留在 SKILL.md。這樣比較像正常工程,而不是把模型當萬用膠水。
如果你在做產品,這種切法很有用。客服流程、資料清理、固定格式輸出,可能都適合 adapter。法規說明、產品政策、臨時活動規則,還是留在文件最安全。
背景脈絡其實很清楚
這幾年 agent 熱起來後,大家都撞到同一堵牆:context 太貴。模型越能吃長上下文,工程師越容易手癢,把所有規則都塞進去。結果就是成本上升,還不一定更準。
LoRA 之前多用在微調模型。現在把它拿來存技能,邏輯很順。因為 skill 本來就介於知識和流程之間。它不是純知識,也不是單次任務,而是一種可重複的行為模板。
我覺得這篇最有價值的地方,不在於它多炫,而在於它很務實。它沒有想改變整個 LLM 世界,只是問了一個很工程的問題:同一份技能文件,真的要每次都重送嗎?答案多半是不用。
接下來值得看的,不是概念,而是落地。哪些技能轉 adapter 之後真的省 token,哪些技能會因為資料不足而掉準確率。這會決定 S2L 是研究題,還是 production 團隊真的會拿來用的工具。
我會怎麼看這件事
如果你的 agent 只有一兩個技能,先別急著上 adapter。直接用 SKILL.md 比較快,也比較好 debug。工程上,能少一層就少一層,這很正常。
但如果你已經有一堆固定流程,而且每次都在燒 token,那 S2L 這條路就值得試。它不是把模型變神,而是把重複成本搬走。這種優化很樸素,但很有效。
我的預測很簡單。接下來會有更多團隊把「技能文件」和「模型參數」分開管理。你如果正在做 agent,不妨先盤點一下:哪些技能每週都在改,哪些技能半年都不動。答案通常會很明顯。