Solver choice changes which Nash equilibrium wins
Different zero-sum game solvers can converge to different Nash equilibria, and the choice is algorithm-dependent.

Different zero-sum game solvers can converge to different Nash equilibria, and the choice is algorithm-dependent.
- Research org: Unspecified in arXiv abstract
- Core data: 100% of converged games
- Breakthrough: Identifies solver-dependent selection on Nash polytopes
In other words: if a game has more than one Nash equilibrium, the solver you pick may not just find an equilibrium — it may consistently pick a specific one. That matters for anyone building game-solving systems, training agents, or analyzing strategic behavior, because “converged” does not necessarily mean “same outcome.”
The paper, Which Nash Equilibrium? Solver-Dependent Selection on Zero-Sum Nash Polytopes, looks at a case that is easy to gloss over in theory and annoying in practice: many two-player zero-sum games do not have a single Nash equilibrium, but a whole convex set of them. These equilibrium sets all share the same minimax value, yet they can encode different behavior. The paper asks a simple but important question: do standard solvers merely find some equilibrium, or do they systematically select different ones depending on the algorithm?
Why this problem matters
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
For developers, the word “equilibrium” can hide a lot of ambiguity. If a game has a unique solution, the solver’s job is straightforward. But when the Nash set is a polytope — a family of valid solutions — the algorithm has room to make a choice. That choice can affect the policy you deploy, the opponent you hedge against, and the downstream behavior you observe when the agent faces sub-optimal play.
The abstract frames this as a solver-selection problem rather than a seed-selection problem. That distinction is important. If outcome differences come from random initialization, then repeated runs may average out. If they come from the algorithm itself, then the solver is effectively part of the policy specification.
The paper studies this with a tabular, exactly solvable testbed of six games whose Nash sets are known analytically. That includes a two-dimensional Nash polytope and Kuhn poker, which gives the author ground truth instead of relying on approximate labels. The result is not just a numerical curiosity; it is a controlled way to see how optimization dynamics interact with equilibrium multiplicity.
What the method is doing
The core setup is deliberately simple: compare different standard solvers on games where the full Nash set is known. Because the games are tabular and exactly solvable, the author can check which equilibrium each method lands on, rather than inferring it indirectly.
The solvers split into two broad families. One group uses regularized last-iterate methods such as R-NaD and magnetic mirror descent. The other uses regret-averaging methods such as CFR, CFR+, and fictitious play. The paper then asks whether these methods converge to the same point inside the Nash polytope or whether they systematically prefer different regions of it.
One of the main technical claims is that the selected equilibrium is determined by the algorithm, not by the seed. That means the solver dynamics, not just randomness, drive the final choice. The paper also reports that the behavior differs only on asymmetric Nash sets, which is a useful clue: symmetry appears to reduce or eliminate the visible selection effect.
For the regularized methods, the paper reports a particularly sharp pattern. R-NaD and magnetic mirror descent select the maximum-entropy member of the Nash set, described as the information projection of their uniform reference onto the Nash set. On the two-dimensional polytope this happens exactly, and in Kuhn poker it reaches 99.7% of maximum entropy. Regret-averaging methods behave differently: CFR, CFR+, and fictitious play drift toward a lower-entropy face instead.
What the paper actually shows
The strongest evidence comes from a mix of analytic ground truth and empirical checks. The author verifies the selection pattern across the hand-constructed games and then checks it again on a randomized 180-game ensemble. In that ensemble, R-NaD attains the maximum-entropy member in 100% of converged games, while CFR+ sits strictly below it in 94% of cases. The paper reports a paired Wilcoxon p-value below 10^-27 for that comparison.
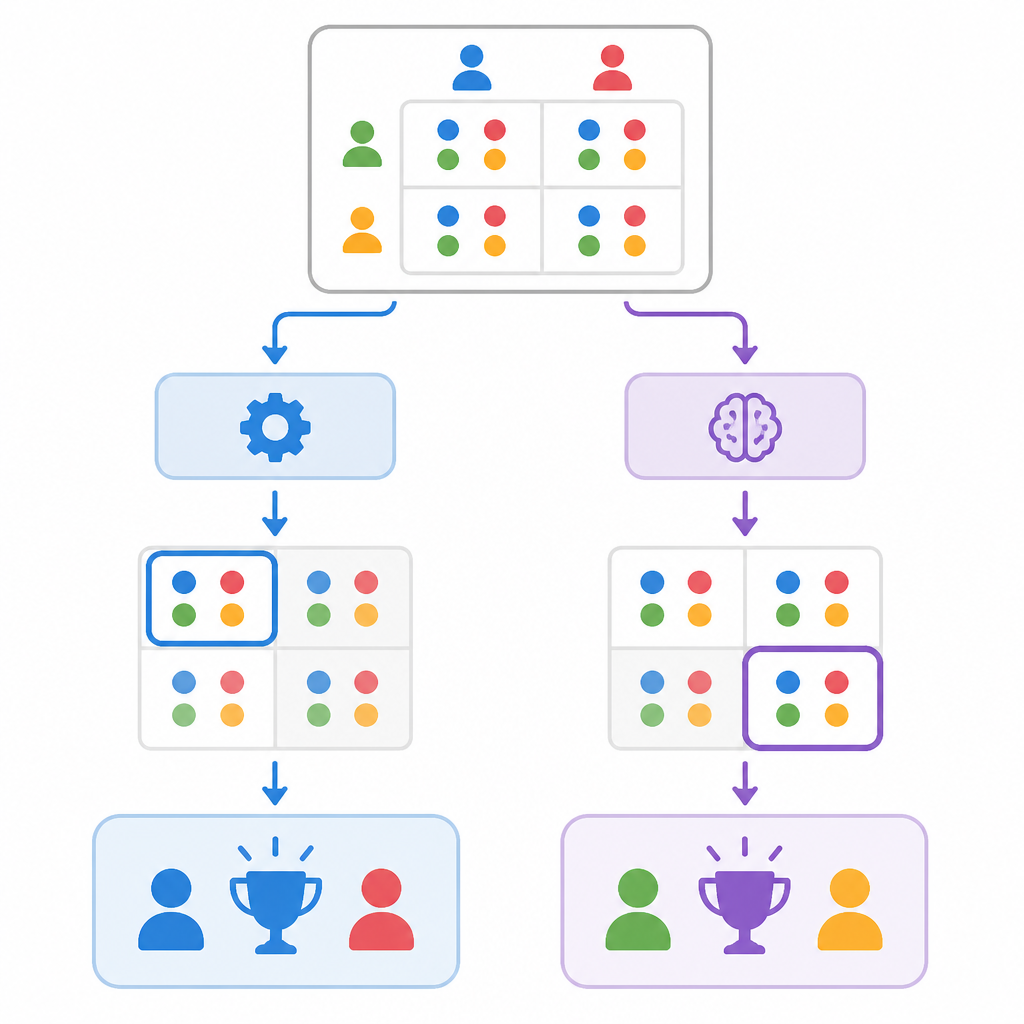
That said, the abstract is careful about one point: the maximum-entropy / I-projection characterization is presented as a strongly data-supported conjecture, not a fully proved theorem. So the paper is not claiming a general mathematical proof for every zero-sum game. It is saying the pattern is consistent with the tested cases and the analytic ground truth available in this setup.
The downstream effect is also concrete. In Kuhn poker, the maximum-entropy member is a strictly better hedge against sub-optimal opponents. On the matrix games, the selected members differ, but neither dominates the others. That means the practical value of one equilibrium over another depends on the game structure: sequential games and hidden-information settings can amplify the difference, while simpler matrix games may just shift behavior without creating a clean winner.
Negative results that matter
The paper includes two corrections to common intuitions. First, removing CFR’s positive-orthant projection, written as max(R,0), does not eliminate boundary drift. So if you were hoping that this projection was the reason CFR-like methods hug the edge of the Nash set, the paper says that explanation is incomplete.
Second, R-NaD’s selection is anchor-following, not initialization-independent. That is a meaningful implementation detail. It suggests that what looks like a stable maximum-entropy tendency may still depend on the method’s reference or anchor behavior, so “regularized” does not automatically mean “free of path dependence.”
These are the kinds of details that matter when you are building or evaluating a solver. A method can be theoretically sound, converge reliably, and still encode a preference among valid equilibria. If your application cares which equilibrium you get — for example, in training self-play agents or analyzing strategic robustness — then solver choice is part of the model design, not just an optimization convenience.
What developers should take away
The practical lesson is to stop treating equilibrium solvers as interchangeable when the Nash set is not unique. If your game has a polytope of equilibria, the algorithm may systematically steer you toward a particular face or point inside that polytope. That can change the policy you deploy, the opponent model you implicitly assume, and the hedge you end up with against imperfect play.
For engineers, this suggests a few habits. Check whether the game you are solving has multiple equilibria. If it does, compare solver families rather than only tuning hyperparameters. And if the downstream task depends on conservative hedging or behavioral diversity, pay attention to whether your method is drifting toward a maximum-entropy solution or collapsing toward a lower-entropy face.
The paper does not give a universal prescription for which solver is best. It does, however, give a strong warning: in zero-sum games with equilibrium multiplicity, “the equilibrium” may really mean “the equilibrium your algorithm prefers.”
Bottom line
This paper shows that equilibrium selection in zero-sum games can be solver-dependent, not seed-dependent, and that different solver families systematically land in different parts of the Nash set. For developers, that turns solver choice into a strategic decision, especially when the game has hidden information or multiple valid equilibria.
- Multiple Nash equilibria can hide solver-specific behavior.
- Regularized last-iterate methods and regret-averaging methods do not pick the same equilibrium region.
- When the Nash set is asymmetric, the selected equilibrium can affect downstream performance.
// Related Articles
- [RSCH]
Google DeepMind turns science into tools
- [RSCH]
Measuring when LLM behavior actually переносится
- [RSCH]
Prompt injection is now an AI security problem
- [RSCH]
Proper positive-only learning gets a full characterization
- [RSCH]
DexCompose Reuses Dexterous Policies Across Tasks
- [RSCH]
HaWoR turns hand motion into MANO params