Cloudflare 新爬蟲規則把控制權交回出版商
4 個重點看懂 Cloudflare 新爬蟲政策:2026/9/15 起預設封鎖訓練與代理使用,並把付費模式改成內容出現在 AI 回答時才計費。

Cloudflare 正在改變爬蟲預設值,讓出版商更容易阻擋 AI 訓練與代理使用。
這份更新不是單純的封鎖名單,而是把出版商的控制權往前推了一步。看完下面 5 項,你可以判斷自己的網站要不要維持預設、提早調整設定,或直接採用新的付費授權模式。
| 項目 | 規格 A | 規格 B | 規格 C |
|---|---|---|---|
| 預設爬蟲政策 | 搜尋可用 | 訓練與代理使用預設封鎖 | 2026/9/15 起生效 |
| 免費帳號 | 沿用相同預設 | 可在期限前退出 | 同樣受新規影響 |
| Pay Per Use | 出版商可收費 | 內容出現在聊天回答時計費 | 取代 Pay Per Crawl |
| 混合用途爬蟲 | 若用途不清楚可被擋 | 特別針對含廣告頁面 | 要求站方可選擇 |
1. 預設先擋住混合用途爬蟲
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Cloudflare 這次的核心改動,是把原本可選的控制改成更防守型的預設。它鎖定的是那種一邊做搜尋索引,一邊又把內容拿去做 AI 訓練或代理行為的爬蟲。
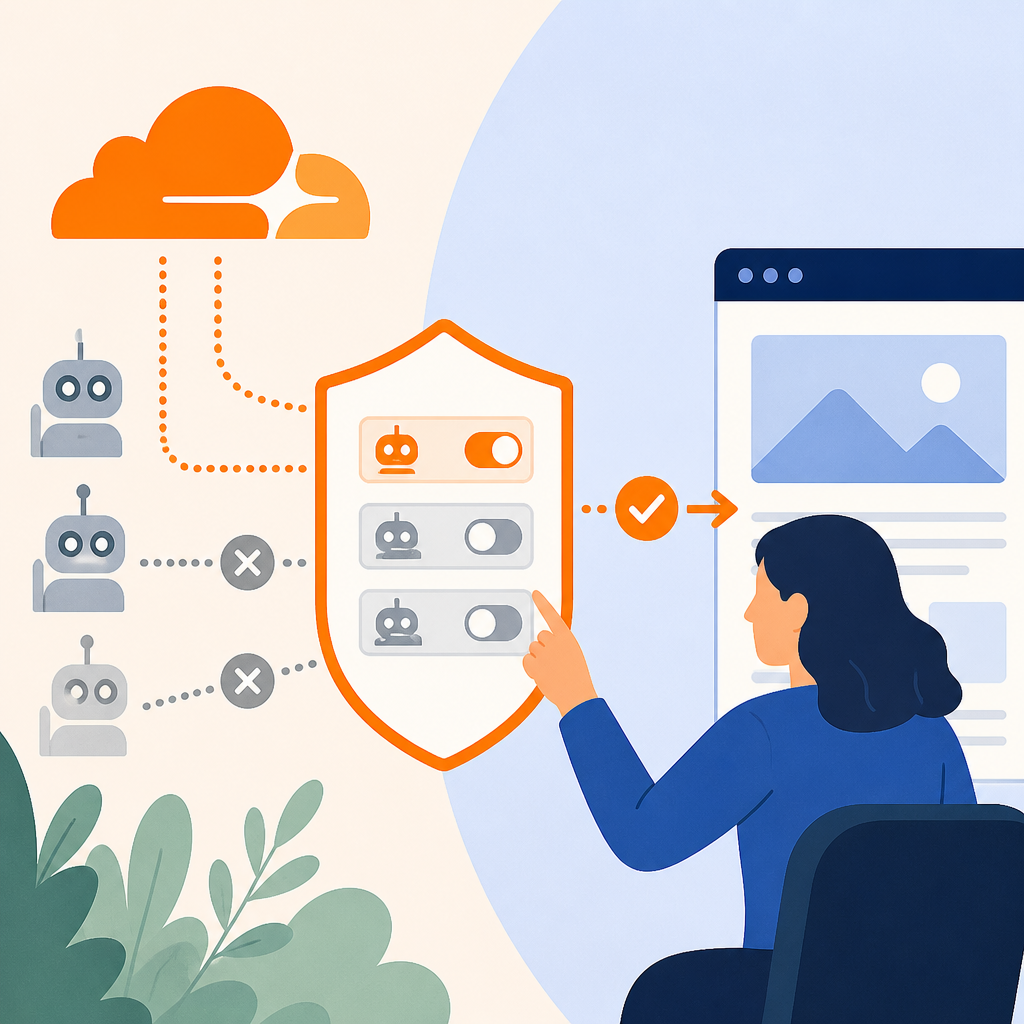
對出版商來說,最直接的差別是:搜尋仍可保留,但在有廣告的頁面上,訓練與代理使用會先被擋下來。這讓站方不用先逐一處理每個爬蟲,再決定要不要放行。
- 搜尋索引仍可允許
- AI 訓練預設封鎖
- 代理使用預設封鎖
- 用途不清楚的混合爬蟲可直接阻擋
2. 2026 年 9 月 15 日是切換點
這次不是模糊的「未來某天」;Cloudflare 已經給出明確日期:2026 年 9 月 15 日。新預設會先套用到新客戶,也會套用到既有帳號新增的網站。
免費帳號同樣會被納入,除非使用者在期限前退出。這代表網站管理者不能只把它當成背景新聞,而是要把設定檢查排進維運流程。
- 適用於新 Cloudflare 客戶
- 適用於既有帳號新增網站
- 免費帳號也包含在內
- 關鍵日期:2026/9/15
3. Pay Per Use 取代 Pay Per Crawl
Cloudflare 也在重做它的收費模型。舊版 Pay Per Crawl 是在 2025 年推出,概念是讓 AI 爬蟲先付費,才可以抓取內容。

新版改名為 Pay Per Use,計費點也往後移:不是內容被抓取時付費,而是當網站內容真的出現在聊天機器人的回答裡才計費。這把焦點從「能不能碰」改成「有沒有實際再利用」。
舊模式:按抓取付費
新模式:內容出現在 AI 回答時才付費4. 目前先從兩個合作方開始
Cloudflare 目前點名的合作方只有兩家:Ceramic.AI 和 You.com。名單不長,但方向很清楚,這不是單純的封鎖工具,而是要做出可交易的授權機制。
這種起步方式也透露出現實限制:要讓更多 AI 公司接受這套規則,前提是出版商願意開放,而 AI 公司也願意把使用條件講清楚。短期內,它比較像是制度雛形,不是完整市場。
- 已公布合作方:Ceramic.AI
- 已公布合作方:You.com
- 目標:讓 AI 使用更透明
- 目標:建立出版商內容的商業條件
5. Google 其實是最難迴避的對象
雖然 Cloudflare 沒有直接點名,但這套規則很明顯也在對準 Google。公告提到,最大搜尋引擎掌握的資訊量約是領先 AI 公司的一倍,因為網站很難在保持可搜尋的同時,不把資料一起送進 AI 系統。
問題在於,Googlebot 不只做搜尋索引,也會支援 Gemini 訓練與 AI Overviews、AI Mode 等功能。Google 雖然提供 Google-Extended 讓網站可選擇不參與模型訓練,但出版商仍缺少一個清楚的分流方式,能同時保留 AI 搜尋又不被拿去訓練。
- Googlebot 同時影響搜尋與 AI 功能
- Google-Extended 是獨立的 opt-in 爬蟲
- 出版商仍缺少完整的搜尋與 AI 分離方案
- Cloudflare 想把這兩件事拆開
哪種適合你
如果你經營的是有廣告的網站,而且想先把 AI 抓取的預設門檻拉高,Cloudflare 這套新規最適合。它給的是更強的起始設定,外加一個可以談條件的收費選項。
如果你是 AI 公司,訊號也很直接:混合用途爬蟲會越來越難說服出版商接受。接下來更吃香的做法,是把搜尋、訓練、代理使用分開,並且讓這個分工對站方一眼可見。