InSight lets VLAs learn new skills on their own
InSight makes vision-language-action policies learn new manipulation skills without human demos of those target tasks.

InSight makes vision-language-action policies learn new manipulation skills without human demos of those target tasks.
- Research org: Unspecified in arXiv abstract
- Core data: No benchmark numbers in abstract
- Breakthrough: Steerable primitive-action VLAs plus a self-labeling data flywheel
Most VLA systems are only as capable as the demonstrations you feed them. If the training set never shows a drawer closing, a pour, or a twist, the policy has little reason to reliably invent those behaviors later.
That is the gap InSight: Self-Guided Skill Acquisition via Steerable VLAs is trying to close. The paper’s core idea is not just to make a robot imitate better, but to make the policy itself steerable at the level of primitive actions so it can collect its own missing experience.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Vision-language-action models are useful because they connect perception, language, and control in one policy. But they also inherit a hard limitation from supervised learning: they can only do what the demonstrations cover. That becomes a bottleneck when you want the robot to keep expanding its skill set after deployment or after the initial training run.

In practical terms, that means a VLA may know how to perform a narrow set of manipulation behaviors, but still fail when asked to do a related task that requires a new primitive. The paper frames this as a skill acquisition problem, not just a task execution problem.
For engineers, that distinction matters. If you are building a robot stack, you do not just want a model that can replay a fixed library of behaviors. You want a system that can identify what it is missing, gather the missing data, and fold that back into the policy without requiring a human to curate every new skill.
How InSight works in plain English
InSight has two main stages. First, it takes demonstration data and automatically breaks it into labeled primitive actions. The paper says this segmentation uses VLM plan decomposition together with end-effector poses, which lets the VLA become steerable at the primitive-action level.
That steerability is the key enabler. Instead of treating a demonstration as one opaque trajectory, InSight turns it into pieces like “move gripper to the bowl,” “lift upward,” and “pour the bottle.” Once those pieces are explicit, the model can be guided more directly toward a missing motion primitive.
The second stage is a VLM-guided data flywheel. When the system faces a novel task, it identifies which primitives are missing. It then autonomously attempts demonstrations of those missing primitives using VLM-proposed low-level control. If the attempt succeeds, the system automatically labels the data, stores it, and adds it to the VLA training set.
That creates a loop: identify a gap, try to fill it, keep the successful attempt, retrain, and expand the skill library. In other words, the model is not only using data; it is also helping generate the next round of data it needs.
What the paper actually shows
The abstract says the authors evaluate InSight in both simulation and real-world manipulation tasks. The listed tasks include block flipping, drawer closing, sweeping, twisting, and pouring. Importantly, these target skills are learned without any human demonstrations of those specific tasks.
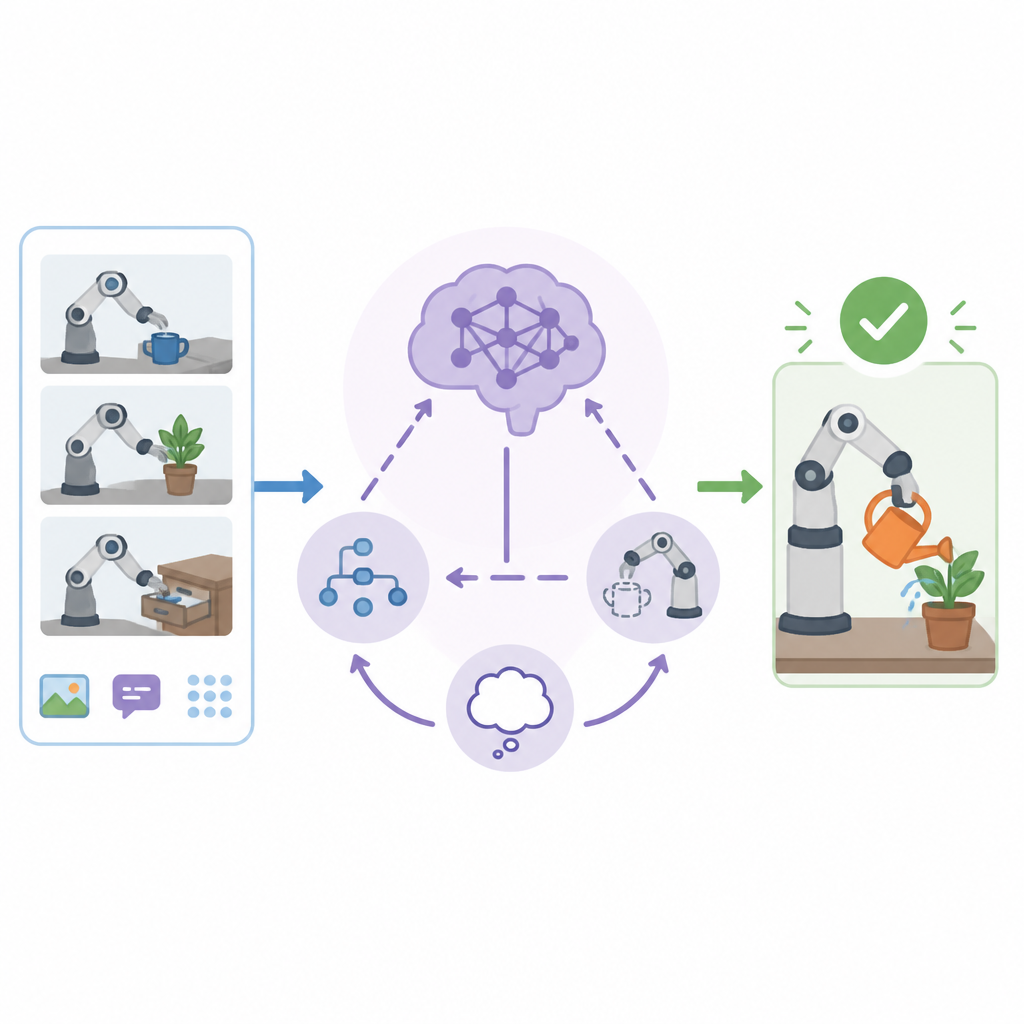
That is the strongest concrete claim in the abstract: the system can acquire and then compose new primitives to execute novel, long-horizon tasks without additional human demonstrations. The paper presents this as evidence that primitive steerability is a practical foundation for continual skill acquisition in VLA policies.
What the abstract does not give is a benchmark table, success rate, sample efficiency number, or latency figure. So while the direction of the result is clear, the source material here does not let us compare InSight numerically against another method.
For a research note, that absence matters. It means the paper’s value proposition is architectural and workflow-oriented rather than a single headline metric in the abstract. The contribution is the mechanism: segmentation into primitives, autonomous gap detection, and self-expanding training data.
Why developers should care
If you are building robotics systems, the most expensive part is often not the model architecture itself. It is the data loop: collecting demonstrations, labeling them, deciding what is missing, and repeating that every time the robot encounters a new behavior.
InSight points toward a more autonomous pipeline. A policy that can expose primitive actions, identify missing capabilities, and bootstrap its own training data could reduce how often humans need to intervene. That is especially relevant for manipulation domains where long-horizon tasks are naturally composed of smaller skills.
There is also a systems-design angle here. Primitive-level steerability gives you a cleaner interface for debugging and extending a policy than a monolithic end-to-end trajectory model. If a task fails, you can reason about which primitive is missing instead of treating the whole policy as a black box.
What is still unresolved
The abstract leaves several practical questions open. It does not specify the size of the datasets, the scale of the robot setup, the amount of human oversight still required in the loop, or how robust the automatic labeling is when the VLM decomposition is imperfect.
It also does not say how broadly the approach transfers beyond the listed manipulation tasks. The paper demonstrates block flipping, drawer closing, sweeping, twisting, and pouring, but the abstract does not claim general coverage of all robot skills or all environments.
Another open question is failure handling. A self-guided system that attempts missing primitives needs a way to avoid reinforcing bad data or storing noisy demonstrations. The abstract says successful demonstrations are automatically labeled, stored, and integrated, but it does not describe the filtering criteria in detail.
The bottom line
InSight is a proposal for making VLAs more like living systems than fixed policies: they can be decomposed into primitives, steered at a lower level, and extended through a self-guided data loop. The paper’s main contribution is not a benchmark number in the abstract, but a training recipe for continual skill acquisition.
For developers, the big takeaway is simple: if you can make a robot policy aware of its own missing primitives, you can start building systems that grow their capabilities with less human demo labor. That is a meaningful step toward robot stacks that improve after deployment instead of freezing at the end of training.
- InSight turns demonstrations into primitive actions for steerable control.
- It uses a VLM-guided flywheel to discover, try, and store missing skills.
- The abstract reports real-world and simulation tests, but no benchmark numbers.
// Related Articles
- [RSCH]
FLUX3D fixes 3DGS detail loss from images
- [RSCH]
Stochastic Subgradient Last Iterate Gets Tight Bounds
- [RSCH]
Anthropic is right to sound the alarm on recursive self-improvement
- [RSCH]
OpenAI’s bug hunt rattled Chrome, Safari, Firefox
- [RSCH]
LLM Fine-Tuning for Production in 2026
- [RSCH]
LifeSciBench lets you test biotech models