Kubernetes 把容器混亂變成營運
我拆 Kubernetes 為何贏在解決真實營運痛點,並附可直接複製的編排模板。

Kubernetes 不是把容器變簡單,而是把部署、擴縮、故障恢復和服務發現這些營運麻煩收進同一套流程。
我用容器平台一陣子了,老實說,Docker 當年把打包這件事做得很順,但一碰到真實流量,整個系統就開始露餡。節點掛了要人盯,流量一衝上來要人調,服務彼此找不到對方又要補 DNS、load balancer、重啟腳本,最後像在把 2009 年的補丁一層疊一層。
最煩的是,很多團隊把 orchestration 當成「之後再說」的東西。我也看過這種心態:先把 container 跑起來,營運問題等上線後再處理。結果「之後」真的來了,整個系統就開始像沒人收拾的工具箱。Kubernetes 會贏,不是因為它把 distributed system 變得不複雜,而是它老老實實去打那些最煩、最貴、最容易出事的地方。
這篇把我重新拉回現實的是 Linux Professional Institute 的文章,作者是 Andrew Oram。文裡沒有提供瀏覽數或書籤數,所以我不亂猜。它真正有價值的地方,是把 Google 的內部 container 工作、Docker 的時間點、還有 CNCF 的角色串起來,讓我看懂 Kubernetes 為什麼會坐到中心位。
Kubernetes 贏在只先處理最髒的那一半
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
“The developers of Kubernetes didn’t solve all the problems—they weren’t about to invent another CORBA, DCE, or OpenStack. But they set the stage for solutions that were quick to come.”
翻譯一下就是:Kubernetes 沒有裝作自己要當萬能平台。它先把控制平面的麻煩處理掉,像是排程、重啟、服務發現、更新、擴縮。這聽起來很克制,但我反而覺得這才是它厲害的地方。很多工具死在「什麼都想做」,最後每件事都做得半吊子。

我看過不少團隊想自己做內部平台,理由都很像:我們要一個更簡單的抽象層。結果半年後回頭看,等於自己重造一個比較醜、文件比較少、沒人維護的 Kubernetes。Kubernetes 會站住,不是因為它漂亮,而是因為它夠窄,窄到能解決問題;又夠寬,寬到可以變成預設協調層。
實操上,我會先問三件事:
- 這個工具到底把哪個人工作業從手動變自動?
- 節點消失時,它保得住什麼狀態?
- 有什麼事能在 1 分鐘內自動完成,不用人來點?
如果答不清楚,我就會很懷疑。因為真正有用的 orchestration,不是看起來很完整,而是能把 pager 上最常見的事消掉。
我之前遇過一個平台案子,大家一開始都很愛講「統一入口」「一致體驗」。聽起來很美,實際上就是把複雜度往後拖。Kubernetes 的做法比較粗暴:先把底層操作收斂,讓團隊至少不用每次都自己處理同樣的爛事。這種務實,我買單。
自動擴縮只有在流量開始耍脾氣時才有感
“Automatic scaling… add new nodes in the cloud as needed, and quickly release them when no longer needed.”
也就是說,系統不能等人看到圖表才反應。流量不是照你排班表走的,尖峰常常來得很沒禮貌。今天一個活動、明天一則社群爆文、後天一個 API 被別人誤用,容量規劃就直接翻車。
我以前也看過很多「已經容器化」的服務,但營運邏輯還是很土。App 是跑在 container 沒錯,可是 replica 數要手動改、load balancer 要等、pod ready 了沒人知道,最後還是工程師坐在那邊盯。這不叫 automation,這只是把手動流程包了一層比較好看的皮。
Kubernetes 讓 autoscaling 變成預設行為,而不是一個要額外寫很多腳本才有的功能。更重要的是,它把 desired state 明講出來。你想要 12 個 replicas,現在只有 9 個,那平台就該自己去補,不要等人來救火。
實作時,我會建議你先選對 scaling 指標:
- CPU 常見,但不一定是最準的
- queue depth 常常比 CPU 更接近真實壓力
- request latency、concurrent sessions 也很常比 CPU 好用
然後把 scale-up / scale-down 的條件寫清楚。很多團隊以為自己有 autoscaling,結果只是「看起來有」。如果擴容後還要人手動重接流量,那你只是把麻煩延後,沒有解決。
我也想提醒一句:autoscaling 不是叫你不要做 capacity planning。它是用來吸收波動,不是用來假裝你不需要知道 baseline load。這兩件事混在一起,最後通常就是 cloud bill 很醜,incident review 更醜。
故障自動重啟不是加分題,是基本盤
“Automatic restart and maintaining state… replace one when it fails.”
翻成白話就是:Kubernetes 把 failure 當常態,不是例外。這件事聽起來很理所當然,但很多系統設計還是活在「故障很少發生」的幻想裡。事實是,node 會死、process 會 crash、network 會抖、image 會壞,而且通常都挑你最忙的時候來。
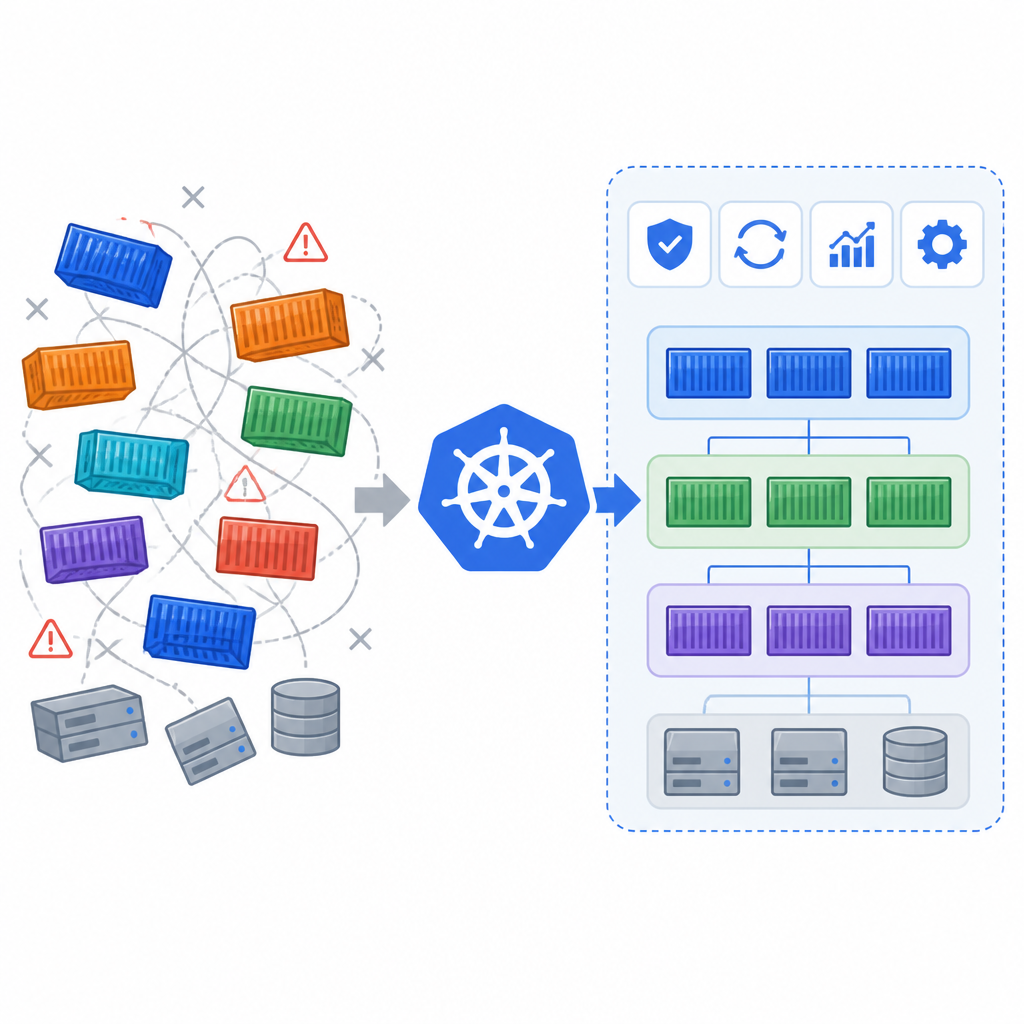
文章裡有一句我很認同:cluster 應該先恢復 desired state,然後人再去查 root cause。這才是正確順序。不要反過來,等你完全搞懂才恢復服務。真實營運不是考試,不需要先交出完整答案才能開始救人。
我看過太多團隊卡在這裡。大家都有 monitoring,也知道 node 掛了,可是 replacement 要手動做、順序要對、設定要對、還要等某個老 script 的 owner 點頭。這就是 ops tax,而且很貴。Kubernetes 的價值之一,就是把這筆稅盡量打掉。
實操上,我會這樣做:
- 每個 workload 都要有明確 desired state
- health checks 不要只寫好看,要真的測過
- restart policy 要跟你的故障模型對齊
- 在 staging 故意 kill pod、drain node、斷 dependency
順便提醒,restart 不等於 recovery。把壞 process 重啟,不代表它依賴的外部狀態也能跟著恢復。這就把我帶到下一個常被忽略、但其實很要命的部分:storage。
Persistent volume 讓容器不再像一次性紙杯
“Persistent Volumes fill that need fairly elegantly, and are tightly bound into Kubernetes.”
意思很直接:Kubernetes 承認一件很煩但很真實的事,container 可以是短命的,application 常常不是。你的 app 可以重啟,客戶資料不行;session state 不行,uploads 不行,index 不行,queue 也不行。很多早期 container 思維最愛假裝所有東西都可以 stateless,結果最後還是偷偷用 bind mount、sidecar、外部腳本補洞。
我以前幫忙拆過一個系統,團隊把 reschedule 當成純實作細節。結果 node 一掛,app 是起來了,資料不是不見,就是半套。這種狀況最煩,因為表面上看起來服務還活著,實際上資料鏈已經歪掉。Persistent volume 的好處,就是把資料路徑說清楚,讓你知道 state 到底在哪裡。
實作上,我會這樣切:
- 如果 service 需要 state,先寫出 state 的落點
- 資料要嘛放 PV,要嘛放外部 DB,要嘛放明確可恢復的 managed storage
- 每次版本升級都要講清楚 migration 怎麼保資料
如果你真的能把 service 做成 stateless,那就做。因為 stateless 比較好搬、比較好換、比較好擴。但不要為了追求 stateless 而假裝沒有資料。那不是架構,那是自欺欺人。
我自己的檢查法很土,但很有效:
- pod 消失時,哪些資料一定要還在?
- node 消失時,哪些 mount 要自動回來?
- 版本更新時,怎麼保證 migration 不把資料搞爛?
這三題答不清楚,storage 設計通常還在手寫階段。
Google 的壓力其實比熱血故事更能解釋 Kubernetes
“Google based Kubernetes on internal projects, investing so much in it that management resisted making it open source.”
翻譯一下就是:Kubernetes 不是從社群玩具長出來的,它是從超大規模的真實壓力裡長出來的。文裡提到一個重點,我覺得很關鍵:客戶付了很多 CPU 的錢,卻因為跑在 VM 上而用得很差。這種經濟痛點,會逼工程團隊很快做出答案。
我不太喜歡把這段歷史講成溫馨的 open source 故事,因為那樣太扁平。Google 釋出 Kubernetes,不是單純因為大方,而是因為一個可信的 orchestration layer,能把更多 workload 拉進它的 cloud 生態。這不是陰謀論,這就是商業策略。
實務上我會建議你看工具時先問:它是被什麼壓力逼出來的?是成本?是 scale?是維運?還是只是 demo 好看?真正被現實磨過的工具,通常 defaults 比較像樣,邊角也比較少幻想。
這也解釋了為什麼 Kubernetes 很快就能被 cloud vendor、platform vendor 接住。它不是又一個抽象層而已,它是大家都能站上去的共同協調層,不用把整個 stack 交給單一廠商。
CNCF 的價值不是漂亮,是讓人敢押注
“Within a year—in July 2015—Google partnered with another leviathan of open source computing, the Linux Foundation, to start the vendor-neutral Cloud Native Computing Foundation (CNCF).”
意思是,Kubernetes 需要的不只是 code,還需要信任。很多團隊不會把基礎設施押在一個看起來像單一公司私產的專案上。CNCF 的作用,就是把這件事變得比較像公共基礎,而不是某家廠商的私人玩具。
我在企業導入時很常看到這種信任問題。工程師喜歡是一回事,採購和平台負責人會問另一回事:如果原廠改方向怎麼辦?如果 roadmap 跑掉怎麼辦?如果 support 只剩一半怎麼辦?CNCF 讓 Kubernetes 的答案比較站得住腳,因為它看起來不再只是 Google 的東西。
實操上,我會這樣評估平台:
- 誰在治理它?
- 誰在持續貢獻?
- 如果要換掉它,退出成本有多高?
治理不是附錄,它會直接影響 roadmap、support、和組織願不願意長期押注。這也是為什麼 Kubernetes 周邊會長出一整串 ecosystem。當一個平台變成大家都假設它存在,其他工具自然會圍著它長。
你覺得 Kubernetes 很吵,是因為它真的進到真實世界了
“And even without Red Hat and CNCF pouring resources into Kubernetes, the community would create all the tools that ease the pain of Kubernetes’s notoriously complex management.”
白話就是:Kubernetes 會長出一堆工具,不是因為它失敗,而是因為它太中心了。當一個平台真的被大量採用,複雜度就會浮上來,接著大家開始補 dashboard、operator、policy engine、ingress controller、各種 helper。名字還常常都愛用 K,這點我真的看得很膩。
我也不想替 Kubernetes 洗白。它確實不簡單。但我更討厭那種把它說成「可以消滅 ops」的說法。沒有這種事。Kubernetes 只是把工作上移到 policy、platform design、cluster discipline。你還是要管,只是不用每次都手動搬石頭。
實操建議很簡單:別期待它變簡單,期待它變成中心。然後你要做的是加 guardrails:
- 統一 deployment 標準
- 資源 requests / limits 先定好
- observability 從第一天就要有
- add-ons 不要讓每隊自己亂裝
如果放任太自由,cluster 很快就會變成垃圾抽屜。這不是 Kubernetes 的錯,是人性。
可抄的模板
# Kubernetes adoption checklist for a real service in production
## 1) Decide what state belongs outside the pod
- Stateless app containers: yes / no
- Persistent data location: database / PV / object storage / managed service
- Session state location: cookie / cache / shared store
## 2) Write the desired state clearly
- Replicas: __
- CPU request / limit: __ / __
- Memory request / limit: __ / __
- Pod disruption tolerance: __
## 3) Add health and recovery rules
- Liveness probe: __
- Readiness probe: __
- Startup probe: __
- Restart policy: Always / OnFailure / Never
## 4) Make scaling explicit
- Scale metric: CPU / memory / queue depth / latency / custom metric
- Scale-up threshold: __
- Scale-down threshold: __
- Minimum replicas: __
- Maximum replicas: __
## 5) Preserve data correctly
- PersistentVolumeClaim name: __
- Storage class: __
- Backup method: __
- Restore test frequency: __
## 6) Keep service discovery boring
- Service name: __
- Port mapping: __
- Internal DNS name: __
- External ingress or load balancer: __
## 7) Roll out changes safely
- Deployment strategy: RollingUpdate / BlueGreen / Canary
- Max unavailable: __
- Max surge: __
- Rollback trigger: __
## 8) Add observability before traffic
- Logs: __
- Metrics: __
- Alerts: __
- Dashboard owner: __
## 9) Enforce platform rules
- Namespace policy: __
- Resource quotas: __
- Image source policy: __
- Secret handling: __
## 10) Test failure on purpose
- Kill a pod: yes / no
- Drain a node: yes / no
- Break a dependency: yes / no
- Verify recovery time: __
## Minimal deployment skeleton
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
replicas: 3
selector:
matchLabels:
app: app
template:
metadata:
labels:
app: app
spec:
containers:
- name: app
image: your-registry/your-image:tag
ports:
- containerPort: 8080
resources:
requests:
cpu: "250m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
httpGet:
path: /livez
port: 8080
initialDelaySeconds: 15
periodSeconds: 20這段我就是照著實務需求整理出來的版本:先把 state、scale、recovery、storage、rollout、observability、policy 寫死,別再用「我們之後再補」這種話騙自己。你可以直接拿去改成你家的 manifest review checklist。
原始拆解來源是 Andrew Oram 在 LPI 的文章,我上面寫的 operational 解讀與模板是我自己整理的衍生版本。若你要追原始脈絡,可以再往 CNCF、Kubernetes 官方文件 和 Google 的歷史背景往下挖。