LACUNA:檢驗 LLM 真的有沒有忘記
LACUNA 用已知參數位置,直接測 LLM unlearning 是否真的擦掉記憶,而不只是讓模型表面上不說。

LACUNA 用已知參數位置,直接測 LLM unlearning 是否真的擦掉記憶,而不只是讓模型表面上不說。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:1B 與 7B OLMo-based 模型
- 突破點:參數級定位測試
LACUNA 想解的問題很直接:大語言模型做了 unlearning 之後,是真的把資料從權重裡移掉,還是只是把輸出藏起來。這個差別很重要,因為如果知識還留在參數裡,模型就可能被重新逼出來,或在其他探測方式下再度冒出。
LACUNA: A Testbed for Evaluating Localization Precision for LLM Unlearning 不是在比誰的答案比較乾淨,而是在問更底層的事:解忘方法有沒有真的打到存放敏感資訊的那一小段權重。這篇摘要把焦點放在 evaluation blind spot,也就是現有基準多半只看行為,不看內部機制。
為什麼現有 unlearning 評估不夠
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這篇論文先指出一個常見落差。現在很多 unlearning 方法,都是靠輸出來判斷成效。模型只要不再吐出原本記住的內容,看起來就像成功了。但這只代表表面行為變了,不代表權重裡的資料真的不見了。

對開發者來說,這種評估方式很容易高估安全性。因為模型可以在某些 prompt 下裝作忘記,實際上卻仍保留相關記憶。摘要特別提到 resurfacing attacks,意思就是就算表面過關,資訊還是可能被重新喚回來。
所以 LACUNA 的定位不是一般 benchmark,而是 testbed。它要補的洞,是把「模型有沒有不說」和「模型有沒有真的改到對的參數」拆開來看。這是做 privacy、compliance、model governance 時很實際的需求。
LACUNA 的方法怎麼做
LACUNA 的關鍵,是它有 ground-truth parameter-level localization。白話講,就是作者先知道敏感資訊被放進哪一些參數,再來測 unlearning 方法有沒有真的去動那些位置。這讓評估不再只靠猜,而是可以直接對答案。
摘要寫得很清楚:他們把 synthetic individuals 的 PII,透過 masked continual pretraining 注入到 OLMo-based models 裡。實驗規模是 1B 和 7B 兩種模型。摘要沒有公開完整訓練配方,所以我們只能知道大方向,不能補細節。
這個設計的價值在於,它把「定位」變成可驗證的問題。以前很多方法只能從輸出推回去猜模型到底改了哪裡;LACUNA 則是先建立地圖,再看方法有沒有真的打在地圖上的目標點。對研究 unlearning 的人來說,這種 ground truth 很少見,也很重要。
換句話說,LACUNA 不只是測模型會不會忘,而是測方法有沒有精準命中記憶所在的參數。這讓它能直接量化 localization precision,而不是只看 output suppression。
這篇論文實際證明了什麼
摘要的主結論很明確:目前的 state-of-the-art unlearning 方法,雖然在輸出層面看起來很強,但在參數層面其實很不精準,而且仍然會受到 resurfacing attacks 影響。
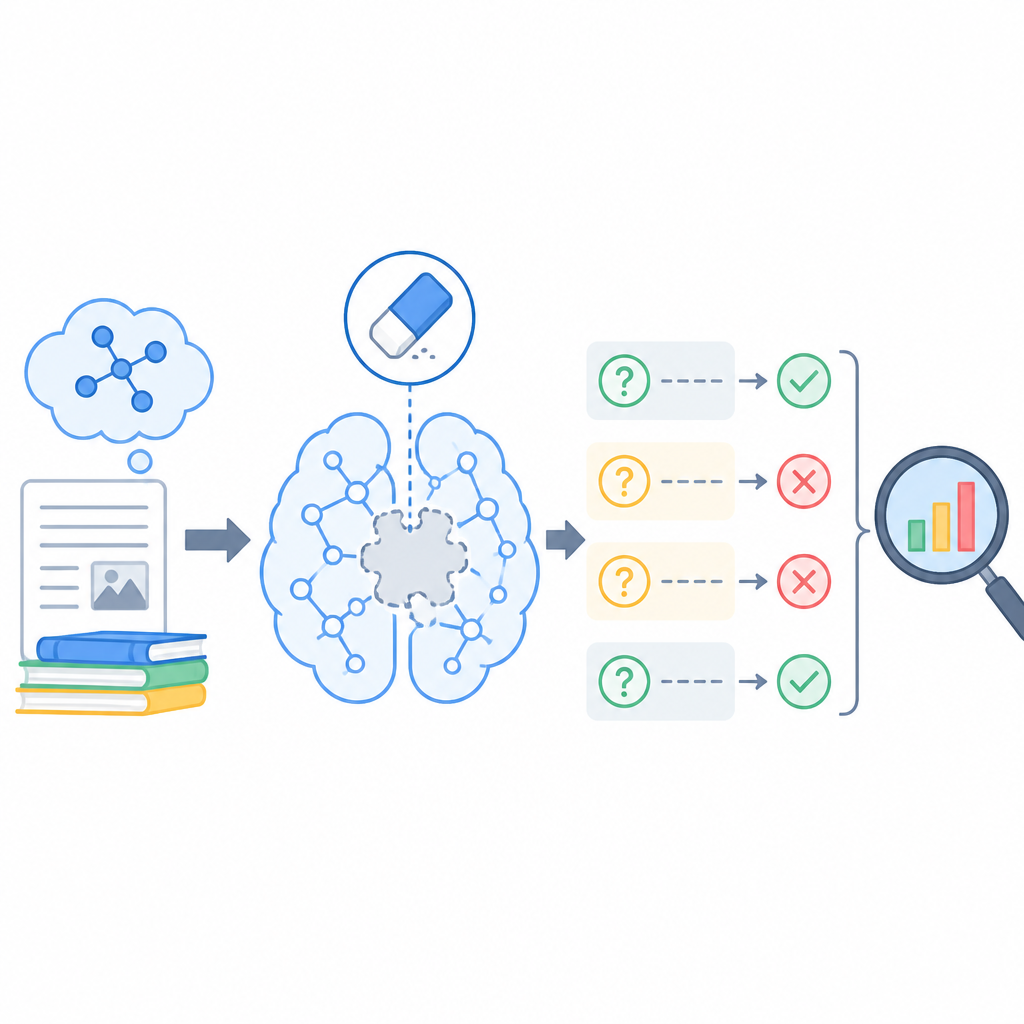
這句話的含意不小。它表示,你如果只看模型是否還會輸出敏感內容,很可能會誤判 unlearning 的效果。模型可能只是把表層反應壓住,真正記住資訊的權重還在,等到條件對了就會再冒出來。
摘要沒有提供完整 benchmark 數字、排行榜或各方法的分數,所以這篇沒有公開可直接引用的量化 leaderboard。它提供的是質性但很尖銳的結果:現有方法常常看起來成功,實際上卻沒有精準處理到該處理的參數。
不過這篇也不是只丟壞消息。摘要同時提到,當 localization 做得好時,即使是簡單的 gradient-based unlearning 方法,也能達到不錯的 erasure 效果,並且對 resurfacing attacks 具備韌性。這代表瓶頸可能不完全在更新規則本身,而是在有沒有先找到正確的參數。
對開發者代表什麼
如果你在做模型訓練、資料治理或隱私刪除,這篇的提醒很直接:不要只用輸出檢查來宣告 unlearning 成功。模型不說,不等於模型真的忘了。對產品團隊來說,這會直接影響你對風險的判斷。
實作上,這也意味著 unlearning pipeline 不能只追求更激烈的更新,還要先追求更準的定位。如果定位不準,你可能花了 retraining 或 fine-tuning 的成本,最後卻沒有拿到你以為的 privacy 或 compliance 效果。
從工程角度看,LACUNA 提供的是一個更接近機制層的評估方式。它讓研究者可以直接測「方法到底有沒有碰到該碰的權重」。這比單純看輸出更難,但也更誠實。
另一個實務啟示是,精準定位可能比更複雜的 unlearning 演算法還重要。摘要暗示,只要定位對了,簡單方法也可能夠用;如果定位錯了,再花俏的方法也可能只是表面功夫。這對想把 unlearning 做進 production 的團隊很關鍵。
限制與還沒回答的問題
這篇摘要也很清楚地畫出範圍。LACUNA 是在 controlled setting 下做的:它把 synthetic individuals 的 PII 注入到 predefined parameters,然後再測定位。這樣很適合研究,但不等於真實世界的訓練資料情境。
真實資料通常更亂。資料來源彼此重疊,記憶也可能分散在不同層、不同參數,未必像 testbed 那樣可以精準標記。摘要沒有說 LACUNA 已經解決這種複雜性,所以它比較像一個強力的研究工具,而不是最終答案。
另外,摘要只提到 1B 和 7B 的 OLMo-based models,沒有宣稱跨架構、跨訓練法、跨資料型態都通用。也就是說,這篇的貢獻是把評估問題做得更準,但還不能直接外推成所有模型都適用。
即便如此,LACUNA 的價值還是很明顯:它把 unlearning 的驗證門檻往內部機制推了一步。這對想認真處理敏感資料的團隊來說,是比單純看輸出更有用的測試方式。
如果你在意的是「資料到底有沒有被刪掉」,那這篇論文的答案是:只看模型說了什麼,還不夠。你還得看它有沒有真的改到存放記憶的參數。LACUNA 就是為了這件事而設計的。
- output-level 檢查可能會高估 unlearning 成效。
- LACUNA 用已知注入位置,直接量測參數級定位精度。
- 摘要指出,定位準比方法複雜更重要。