先學動作先驗,再對齊多模態
這篇論文證明,先用動作軌跡學出 motion prior,再做視覺語言對齊,能讓跨具身操作訓練更快、成功率更高。

這篇論文證明,先用動作軌跡學出 motion prior,再做視覺語言對齊,能讓跨具身操作訓練更快、成功率更高。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:13 個跨具身任務
- 突破點:先預訓練動作先驗
Vision-language-action 系統近年很紅。它們能吃進視覺與語言知識,再輸出機器人的動作。但問題也很明顯:感知與語意可以從大模型繼承,動作卻常常幾乎從零開始學。這篇論文就是在補這個洞。
作者的主張很直接。不要把「學會怎麼動」和「學會語意對齊」塞進同一個訓練流程。先讓動作模組建立自己的 motion prior,再把這個先驗帶進跨模態訓練。對跨具身操作來說,這個拆法特別重要,因為同一個任務意圖,得映射到不同機器人身體、不同動力學、不同控制空間。
這篇論文在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
傳統 VLA 模型通常是把 action module 接到 vision-language backbone 上,然後端到端一起訓練。聽起來簡單,但代價是動作模組得同時學兩件事:一是物理運動的時間結構,二是語言與視覺怎麼對上動作。對模型來說,這是很硬的最佳化問題。
摘要特別指出,這種困難在訓練初期最明顯,而且在 robot embodiment 改變時會更嚴重。白話一點說,模型不只要學「要做什麼」,還要學「這個身體應該怎麼動才算對」。如果沒有先驗,動作模組很容易把算力花在重學基本控制,而不是任務理解與跨平台泛化。
這也是跨具身操作最麻煩的地方。你不能只看語意對不對,還要看動作在不同機器上能不能落地。這篇論文把問題拆開,等於承認動作學習本身就是一個值得先預訓練的核心模組。
方法怎麼做,白話講清楚
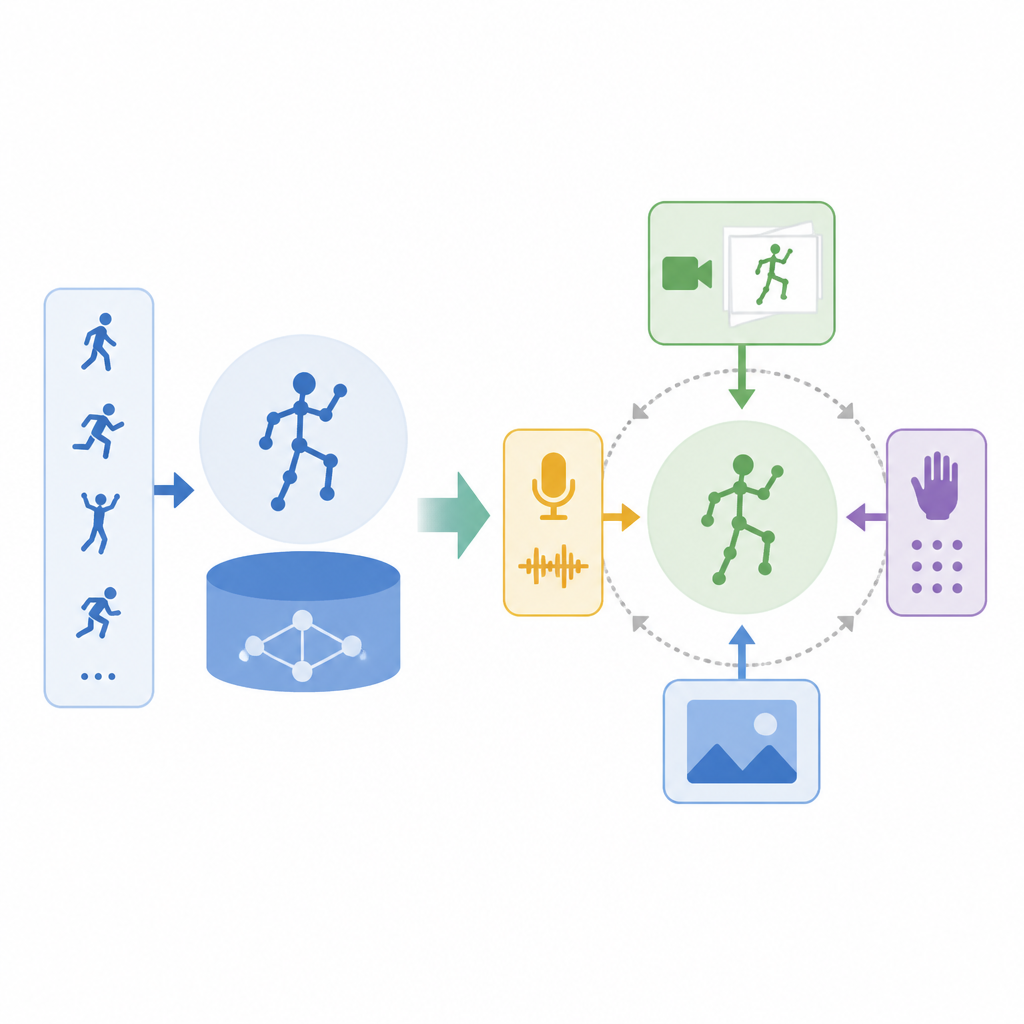
作者提出的是兩階段訓練框架。第一階段先學 motion structure,第二階段再把這個結構搬進 VLA 訓練。核心精神就是:先給 policy 一個動作先驗,再讓它學視覺、語言和動作的對齊。
第一階段用的是一個輕量的 flow-matching encoder-decoder action module。它只看 unconditioned action trajectories,也就是不吃視覺 token,也不吃語言 token。這代表它學的是純粹的時間序列運動結構,而不是任務語意。這一步很像先讓模型熟悉「怎麼動」,而不是先急著知道「為什麼動」。
第二階段則把第一階段學到的 prior 拿去做 VLA training。摘要提到兩個關鍵做法:decoder reuse 和 early-stage latent distillation。前者讓已經學好的動作結構可以直接被重用,後者則是在訓練早期把視覺語言特徵往動作 embedding space 對齊。這樣做的好處是,模型不是從零開始摸索動作空間,而是在一個已有的運動表示上做調整。
值得注意的是,這不是把 action module 凍結起來不動。摘要明確說,系統仍然保留 end-to-end policy refinement。也就是說,它不是硬切成兩段各做各的,而是先預熱動作模組,再讓整個 policy 繼續一起優化。
另外,訓練好的 encoder 不只拿來初始化。摘要還說,它可以把 state-action history 壓縮成單一 temporal context token,作為 history-aware modeling 的低成本表示。這點很實用,因為它暗示 motion prior 不只是參數初始化,也能變成可重用的時間上下文表示。
論文實際證明了什麼
這篇摘要提到作者做了 13 個跨具身任務的實驗,涵蓋模擬環境與真實世界平台。摘要沒有公開每個任務的數字、成功率表格或完整 benchmark 細節,所以目前不能逐項引用具體分數。
但摘要給出的方向性結果很清楚:跟沒有 action prior 的 VLA 訓練相比,這套方法收斂更快、成功率更高,而且在資料稀缺的真實世界任務上表現更好。這三個訊號對機器人開發者都很直接。收斂更快,代表訓練時間更少、算力浪費更低;成功率更高,代表 motion prior 不是裝飾品,而是真的有幫助;真實世界資料少時表現更好,則表示這個方法對昂貴的機器人資料特別有價值。
摘要還提到,Stage 1 的 action data 規模越大,學到的 action prior 就越能泛化,而這個更好的 prior 也會直接拉升下游 VLA 表現。這是一個很重要的 scaling 訊號。它表示額外的動作軌跡不只是「多一些訓練資料」,而是可以沉澱成可重用的 motion foundation,之後再服務跨模態學習。
如果只看結論,這篇論文不是在證明某個單一技巧神奇有效,而是在證明一個訓練順序很重要:先學動作,再學對齊。對跨具身操作來說,這個順序可能比把所有東西一起端到端硬磨,更符合實際系統的學習方式。
對開發者有什麼影響
如果你在做 robot policy,這篇論文最值得帶走的觀念是:action stack 應該有自己的 pretraining strategy。很多團隊已經習慣讓 vision-language backbone 先吃大量資料,卻常把動作模組當成附屬零件。這篇工作反過來提醒你,控制動力學本身也值得先學。
對工程實作來說,這種拆法很像先學底層 dynamics,再學高層接口。這裡的接口,就是視覺語言特徵與 action embedding space 的對齊。好處是保留 end-to-end refinement,沒有把系統鎖死成完全靜態的兩段式管線。也就是說,你可以先讓動作模組有底,再讓整體 policy 持續修正。
history compression 這個設計也有實務價值。把 state-action history 壓成一個 temporal context token,對記憶體和延遲敏感的系統會很有吸引力。摘要沒有提供 runtime 數字,所以不能說它省多少成本,但至少作者把它描述成 negligible cost,代表這個表示法是為了讓 temporal modeling 更輕量。
對跨具身場景來說,這種方法的吸引力還在於可轉移性。不同機器人之間,動作空間和控制方式常常差很多。若先在 unconditioned trajectories 上學出一個 motion prior,再拿去做跨模態對齊,理論上就能減少模型從零摸索控制結構的負擔。這正是跨平台泛化最缺的那一塊。
這篇摘要也有什麼限制
這份摘要的限制也很明顯。它講方法講得清楚,但 benchmark 細節很少。沒有逐任務數字、沒有完整 ablation、也沒有明確的成功率表格,所以目前只能判斷方向是正向,還不能精準量化每個設計帶來多少增益。
摘要也沒有說明具體用了哪些 robot embodiments、控制空間差異有多大、Stage 1 的 trajectories 來源是什麼。這些資訊對要把方法搬到新平台的人很重要。沒有這些細節,最安全的解讀就是:先把 action module 的 motion structure 預訓練起來,似乎有助於資料稀缺與跨具身泛化,但落地時仍要看自己的機器人和資料分布。
另一個未解問題是 scaling 的邊界。摘要只說 Stage 1 的 action data 越多,下游 VLA 越好,但沒有給出曲線,也沒有說明什麼時候會出現邊際效益下降。對實務團隊來說,這代表這個方向值得試,但仍需要在自己的控制空間、自己的資料量和自己的任務上做驗證。
總結
這篇論文的核心訊息很清楚:在跨具身操作裡,動作模組不該只是 VLA backbone 的附屬品,而應該先學出自己的 motion prior。先學運動結構,再做視覺語言對齊,能讓訓練更快、成功率更高,也更能吃下真實世界的資料稀缺問題。
對台灣的機器人與具身 AI 團隊來說,這篇工作的啟發很務實。如果你的系統卡在動作學不穩、跨平台泛化差,問題可能不只在感知或語言,而是在 action module 從零開始學控制。這篇論文提供了一個明確方向:先把動作學好,再讓多模態去對齊它。