Why LLMs Generalize on Maps but Fail on Scale
A synthetic shortest-path setup shows LLMs transfer across maps, but break when problems get longer because recursive reasoning gets unstable.

Can an LLM solve a new problem type in a way that actually generalizes, or is it just getting lucky on the shapes it has seen before? This paper tackles that question with a controlled shortest-path environment, which is a clean way to separate different kinds of generalization and see where models really break.
Generalization in LLM Problem Solving: The Case of the Shortest Path argues that a lot of the confusion around LLM problem solving comes from mixing together training data, training setup, and inference tricks. By stripping the task down to synthetic shortest-path planning, the authors isolate those factors and test two different axes of generalization: whether models can transfer to unseen maps, and whether they can scale to longer-horizon problems.
What problem this paper is trying to fix
The core issue is not whether an LLM can solve a benchmark once. It is whether the model has learned a reusable procedure that still works when the input changes in meaningful ways. In practice, that is hard to tell, because performance can be influenced by how much data the model saw, whether it was trained with supervised learning or reinforcement learning, and what inference-time strategy was used.
The paper focuses on a canonical sequential optimization task: shortest-path planning. That choice matters because it gives the researchers a synthetic environment where the structure of the problem is known, the inputs can be controlled, and the two main forms of generalization can be tested separately. For developers, that makes the results easier to interpret than a broad benchmark where many hidden variables move at once.
Instead of asking whether a model is “good at reasoning” in the abstract, the paper asks a more operational question: when does the model genuinely extend what it learned, and when does it fall apart as the problem gets longer or more complex?
How the method works in plain English
The setup uses synthetic maps and shortest-path tasks. Because the environment is controlled, the authors can vary the training distribution and then test models on two orthogonal axes:
- Spatial transfer: can the model handle unseen maps that differ from the ones in training?
- Length scaling: can the model solve longer-horizon problems than the ones it was trained on?
That distinction is important. A model might learn the general “shape” of shortest-path planning and still fail when the path gets longer. Or it might memorize patterns that work on familiar layouts but not on new ones. By separating these cases, the paper can tell whether a failure is about unfamiliar geography or about the model’s ability to maintain a reasoning process over more steps.
The authors also examine the learning pipeline itself. They look at how data coverage, reinforcement learning, and inference-time scaling each affect systematic problem-solving. That lets them ask not just “does the model work?” but “which stage of the pipeline sets the ceiling, and which stage only makes the model look better within that ceiling?”
What the paper actually shows
The headline result is a split outcome. The models show strong spatial transfer, meaning they can generalize to unseen maps reasonably well. But they consistently fail under length scaling. The paper attributes that failure to recursive instability, which suggests the model’s step-by-step reasoning becomes unreliable as the required horizon grows.
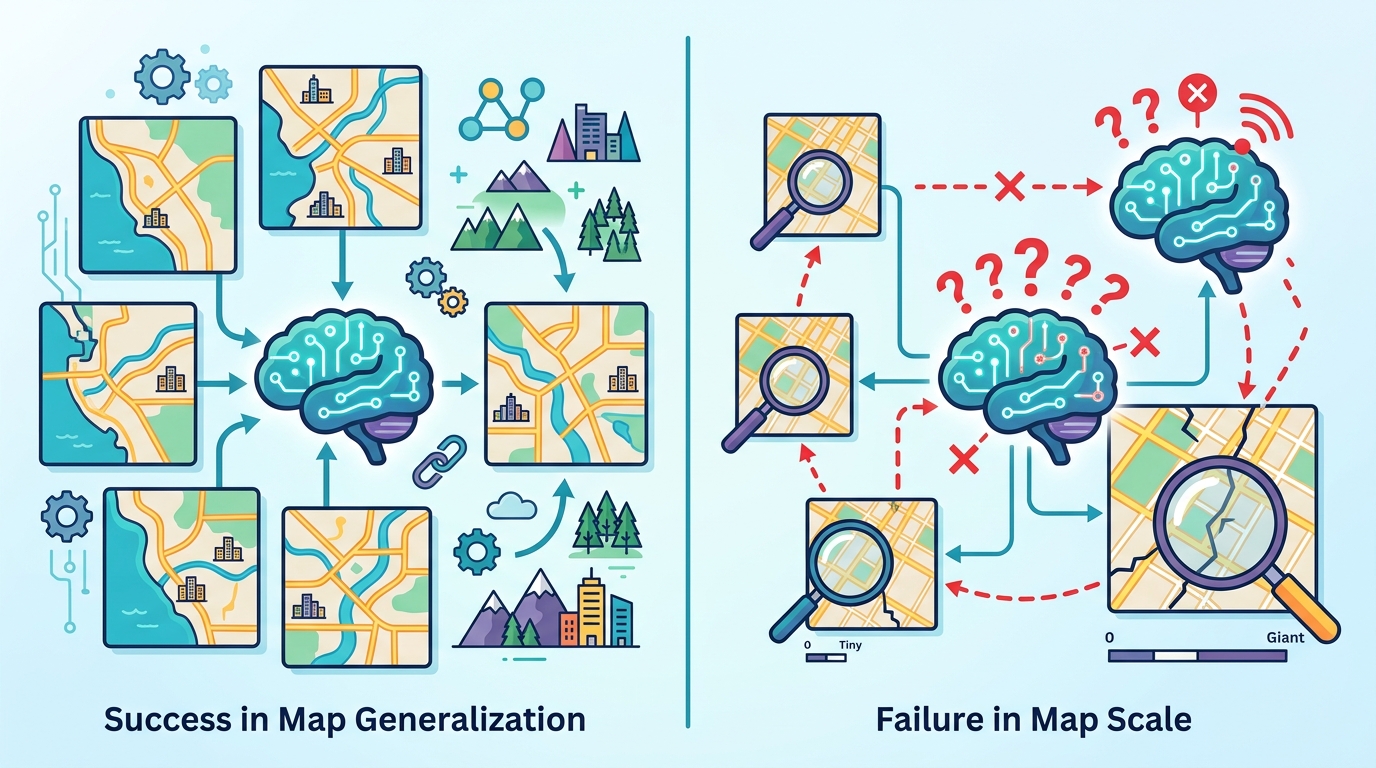
This is a useful distinction because it shows that generalization is not one thing. A model can transfer across input variations while still being brittle when the task demands longer chains of intermediate reasoning. In other words, success on new layouts does not imply success on harder versions of the same task.
The paper also reports a clear division of labor across training and inference choices. Data coverage sets capability limits. Reinforcement learning improves training stability, but it does not expand those limits. Inference-time scaling can improve performance, but it cannot rescue the failure mode tied to length scaling. The abstract does not provide benchmark numbers, so the paper’s claims here are qualitative rather than numeric in the source material provided.
For engineers, that is the key practical takeaway: better training and smarter decoding can help, but they do not automatically create a model that can reliably extend its reasoning depth beyond what its internal process can support.
Why developers should care
If you are building systems that depend on LLMs for planning, routing, search, or other multi-step decision tasks, this paper is a reminder that “works on similar inputs” is not the same as “scales to harder instances.” A model may look robust in one dimension and still be fragile in another.
The shortest-path setup is synthetic, but the lesson generalizes in a practical sense: you need to know whether your failure is caused by distribution shift, insufficient coverage, or a reasoning process that degrades as the task length increases. Those are different engineering problems, and they likely need different fixes.
The paper also suggests that reinforcement learning should not be treated as a universal upgrade. In this study, it stabilizes training without expanding the model’s fundamental problem-solving ceiling. That matters if you are deciding how to spend compute: more optimization can make training smoother, but it may not buy you the kind of generalization you actually need.
Limits and open questions
The paper is intentionally controlled, which is a strength, but it is also a limitation. A synthetic shortest-path environment is not the same as real-world software workflows, agentic planning, or open-ended reasoning. The result tells us something precise about one class of composable sequential optimization problems, not everything an LLM might do.
Another limitation is that the abstract does not give benchmark numbers, model names, or detailed experimental settings in the material provided here. So while the direction of the findings is clear, the exact magnitude of the effect is not available from the source notes alone.
Still, the paper raises a useful engineering question: if a model can transfer spatially but fails under longer horizons, what is the right intervention? Better data coverage? Different training objectives? More robust recursive algorithms? The paper does not claim to solve that problem, but it gives a cleaner way to diagnose it.
For teams evaluating LLMs in production, the main lesson is simple: test generalization along multiple axes, not just against held-out examples that look like training data. A model that survives one kind of shift may still fail badly when the task gets longer, even if the underlying logic is the same.


