LLMs plus knowledge graphs for ML explainability
A manufacturing XAI method uses a knowledge graph plus an LLM to turn ML results into clearer, more user-friendly explanations.

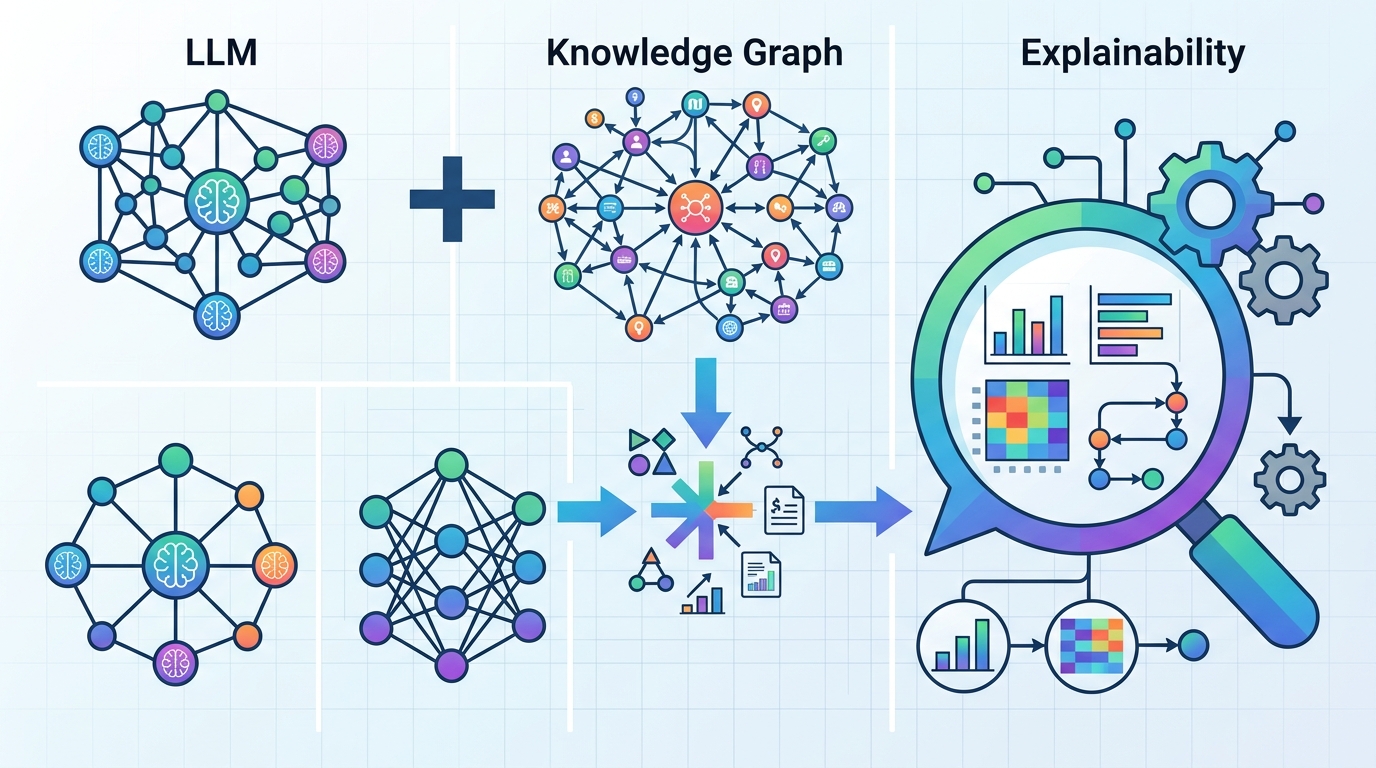
Machine learning models can be useful in manufacturing, but their outputs are often hard to explain to the people who need to act on them. This paper proposes a practical way to make those explanations easier to understand: store domain knowledge, ML results, and their explanations in a knowledge graph, then use a large language model to turn selected graph facts into user-friendly answers.
The core idea is not to replace the model or invent explanations from scratch. Instead, the system retrieves relevant triplets from the knowledge graph and feeds them to an LLM, so the generated explanation stays tied to structured domain information. For developers building XAI systems, that matters because it points to a workflow that is more controlled than free-form prompting and more flexible than static rule-based explanations.
What problem this paper is trying to fix
Explainable AI is still a hard problem when machine learning is used in real operational settings. In manufacturing, users need to understand why a model produced a result, not just what the result was. If the explanation is too technical, too generic, or disconnected from the domain, it is unlikely to help decision-making.
The paper frames this as a transparency and usability problem. Standard ML outputs are often not enough for operators or other stakeholders who need to interpret them in context. That is especially true when the question is not only “what happened?” but also “why did the model say that?” and “what should I do next?”
Instead of treating explainability as a purely model-internal task, the authors connect ML outputs to domain knowledge. Their approach is built around the idea that explanations become more useful when they are grounded in a structured representation of manufacturing knowledge rather than generated in isolation.
How the method works in plain English
The proposed method uses a knowledge graph as the central store for domain-specific data, ML results, and the explanations associated with those results. That creates a structured link between what the model predicted and the knowledge needed to interpret it.
When a user asks for an explanation, the system does not send the entire graph to the language model. Instead, it uses a selective retrieval step to extract only the relevant triplets from the knowledge graph. Those triplets are then processed by an LLM, which generates a more readable explanation for the user.
This selective retrieval design is important. It suggests a way to keep the LLM focused on the right evidence, rather than relying on a broad prompt that might be noisy or incomplete. In other words, the knowledge graph acts as a filter and a source of grounding, while the LLM handles the final language generation.
From an implementation perspective, this is a hybrid architecture: structured retrieval first, natural-language explanation second. That pattern is familiar to engineers working on retrieval-augmented systems, but here it is applied specifically to explainability in manufacturing ML workflows.
What the paper actually shows
The authors evaluated the method in a manufacturing environment using the XAI Question Bank. They did not stop at standard questions. They also introduced more complex, tailored questions designed to highlight where this approach is strongest.
According to the abstract, they evaluated 33 questions in total. The responses were analyzed with quantitative metrics such as accuracy and consistency, and qualitative metrics such as clarity and usefulness. The abstract does not provide the actual benchmark values, so those numbers are not available from the source material here.
That said, the paper claims the method can successfully produce explanations in a real-world manufacturing setting. The contribution is presented as both theoretical and practical: on the theory side, it shows a way for LLMs to dynamically access a knowledge graph to improve explainability; on the practical side, it offers evidence that the resulting explanations can support better decision-making in manufacturing processes.
One useful detail is the emphasis on question design. By adding more complex, tailored questions beyond the standard bank, the authors seem to be testing not just whether the system can answer simple explainability prompts, but whether it can handle the kinds of domain-specific questions that actually come up in production settings.
Why developers should care
If you build ML systems for industrial or operational environments, this paper points to a concrete architecture for explainability that is easier to reason about than ad hoc prompt engineering. A knowledge graph gives you a structured place to store domain facts and model outcomes. An LLM then translates that structure into language that non-technical users can understand.
That separation of responsibilities is valuable. It means you can update domain knowledge without rewriting the explanation layer, and you can keep the generated responses tied to explicit graph entries instead of hoping a model will infer the right context. For teams that need auditable, user-facing explanations, that is a meaningful design direction.
There is also a product-side implication: explanations can be tailored to the task and the audience. The paper’s selective retrieval method suggests a way to surface only the most relevant facts for a given question, which is often what makes explanations feel useful instead of overwhelming.
- Knowledge graph stores domain data, ML results, and explanations together.
- Selective retrieval pulls only relevant triplets for each question.
- LLM turns retrieved facts into user-friendly explanations.
- Evaluation used 33 questions in a manufacturing environment.
- Metrics mentioned: accuracy, consistency, clarity, usefulness.
Limitations and open questions
The abstract is promising, but it leaves several practical questions unanswered. It does not include the actual metric scores, so we cannot judge how strong the method was relative to alternatives. It also does not describe a baseline comparison in the source material provided here.
Another open question is how the selective retrieval performs as the knowledge graph grows. In real manufacturing systems, domain knowledge can become large, messy, and highly dynamic. The abstract does not say how retrieval quality changes with scale, or how much manual effort is needed to maintain the graph and the explanation mappings.
There is also the broader issue of trust. Even if the LLM is grounded in retrieved triplets, the final explanation is still generated text. The paper suggests that this improves interpretability, but the abstract does not show whether users consistently prefer these explanations over other XAI methods, or how much they improve actual operational decisions.
Still, the direction is clear: combine structured knowledge with language generation instead of asking a model to explain itself in a vacuum. For engineering teams working on explainable ML in manufacturing, that is a practical pattern worth watching, especially if the goal is to make model outputs understandable to people who are not ML specialists.
In short, this paper is less about a flashy new model and more about an architecture for making ML explanations usable. That makes it relevant to anyone trying to ship explainable AI into a real workflow, where clarity, context, and controlled generation matter as much as raw model performance.
Related Articles

Autoencoders for stochastic dynamics get geometric regularization
Apr 20

ASMR-Bench Tests Sabotage Detection in ML Code
Apr 20

OpenAI pushes GPT-5.4-Cyber into security work
Apr 19

Stanford’s 2026 AI Index, explained with charts
Apr 17

How to Trust LLM Judges, Per Input
Apr 17

Why LLMs Generalize on Maps but Fail on Scale
Apr 17