LOCUS把美國地方法規變機器可讀
LOCUS 建出美國地方法規語料庫,把分散的市郡條例整理成可供法律 AI 搜尋與分析的資料層。

LOCUS 建出美國地方法規語料庫,把分散的市郡條例整理成可供法律 AI 搜尋與分析的資料層。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:涵蓋 9,239 個城市與郡
- 突破點:OCR 語料加郡級整合層
法律 AI 常卡在一個很現實的問題:它看得到的法,不一定是實際上管得到你的法。聯邦法、州法比較容易被整理成可搜尋文本,但真正影響日常營運、土地使用、噪音、動物管制、營業許可與公共衛生的,常常是市郡層級的地方法規。這篇論文要補的,就是這一層。
LOCUS 的核心想法很直接:把分散在不同平台、不同格式、不同地區的 local ordinances 整理成機器可讀的語料庫,讓研究者和模型開發者可以真正做 bulk analysis,而不是只能一條一條人工翻。
這篇論文在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
摘要指出,現有法律語料庫大多忽略了地方法規這一層。原因不是這些法不存在,而是它們太碎、太分散,而且通常放在給人類瀏覽用的平台上,不是給資料擷取和 NLP 管線用的。
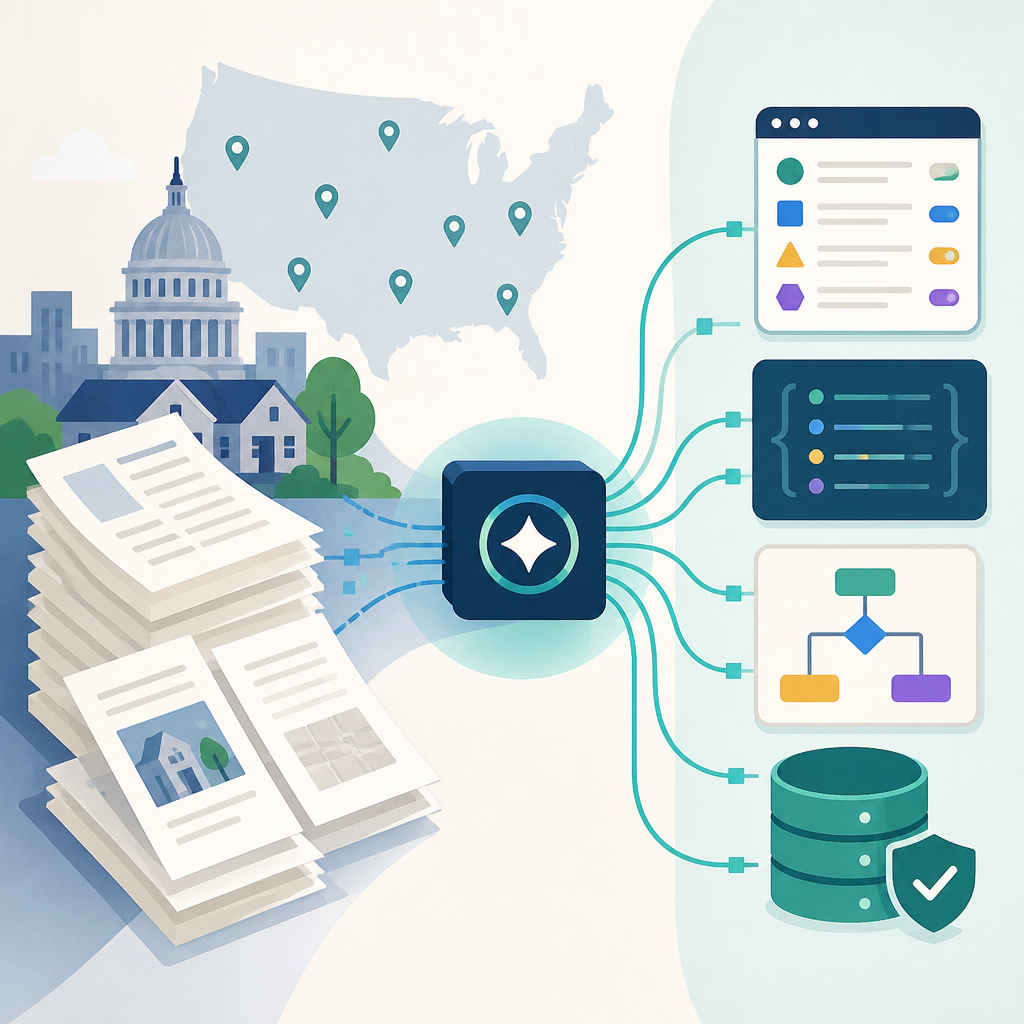
對開發者來說,這個痛點很熟悉。你可以把聯邦法做成檢索系統,但如果系統碰不到市郡條例,它在很多真實場景裡就會失真。像是開店、建築審查、分區限制、噪音規範,這些問題往往不是高層級法條能完整回答的。
LOCUS 想做的,不只是收集文件,而是把原本 operationally inaccessible 的資料,變成能被索引、訓練、比較和分析的資源。這也是它被定位成 corpus 加 access layer 的原因。
LOCUS 怎麼做
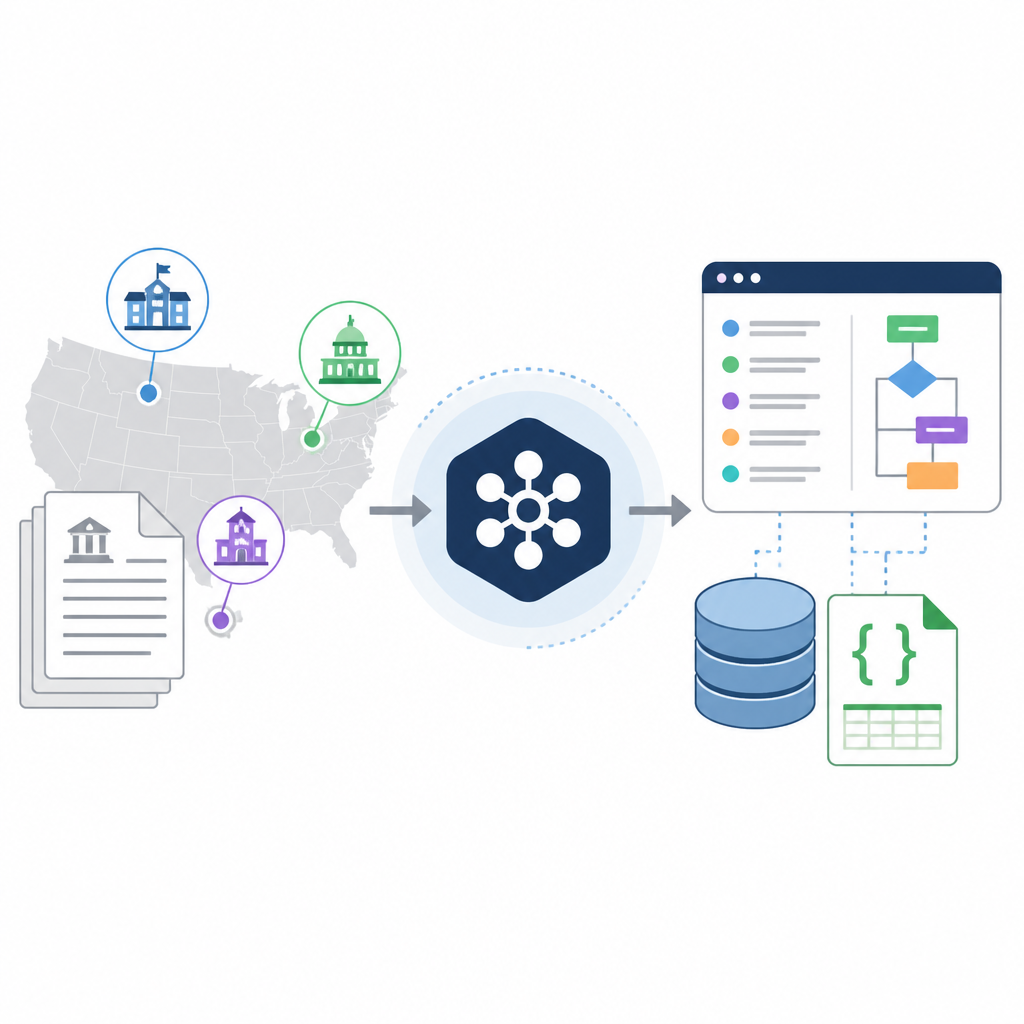
這篇工作的第一步是收集。摘要說,原始語料幾乎涵蓋所有公開可取得的 municipal 與 county ordinance codes。這代表它不是只挑幾個城市做樣本,而是想把美國地方規範的主要面貌先抓出來。
第二步是 OCR。這點很關鍵,因為地方法規的來源格式本來就很亂。不是每份法規都長得像乾淨的 API 回傳 JSON,很多是文件型資料,甚至需要先從掃描或排版混亂的內容裡把文字抽出來。論文把 OCR 放進流程,等於承認這個問題不是純檢索,而是資料基礎建設。
第三步是 county-harmonized access layer。摘要說這個層級覆蓋美國 3,144 個郡中的前 2,309 個,而且作者特別指出這部分涵蓋了多數人口。白話講,就是它不只想把資料堆大,還想把最有代表性的郡級結構先標準化,方便後續分析。
另外,作者也釋出 coverage metadata。這對法律資料很重要,因為你如果不知道哪些地區有收、哪些沒收,後面做模型訓練或統計分析時,很容易把缺漏誤當成現象。
這篇論文實際證明了什麼
摘要有給出幾個很明確的規模數字。LOCUS 的原始語料涵蓋 9,239 個城市與郡;郡級整合層則覆蓋 3,144 個美國郡中的 2,309 個。這些數字至少證明一件事:它不是概念展示,而是有實際規模的資料釋出。
不過,摘要沒有公開完整 benchmark 細節。它沒有列出 retrieval、classification、legal QA 或其他下游任務的準確率,也沒有提供和既有方法的直接對照分數。所以如果你期待的是模型性能表現,這份 abstract 其實沒有把那一塊講完。
摘要另外提到,作者訓練了一組基於 ModernBERT 的 classifiers 和 scorers,用來分析 local law 的 opacity 與 paternalism。這裡的重點不是單一模型有多強,而是語料庫一旦存在,研究就能從「有沒有資料」往「資料能量化什麼」前進。
但就摘要來看,這些分析工具比較像是初步的研究層,而不是整篇最終要證明的核心結論。真正最有力的成果,仍然是資料本身與它的整理方式。
對法律 AI 與開發者的意義
如果你在做法律搜尋、合規工具、civic tech,或是政策分析系統,LOCUS 這種資料集的價值很直接:它補上了很多系統原本看不到的法源層級。
很多實務問題其實都落在地方規範。你查得到州法,不代表你知道某個城市能不能開某種店;你能做條文檢索,不代表你能快速比較不同郡的規範差異。LOCUS 提供的是一個讓這些工作變得可做的基礎。
對工程實作來說,county-harmonized layer 特別有用。因為法律資料最麻煩的地方之一,就是 jurisdiction 結構不一致。當你要做跨地區比較、檢索排序或分類模型時,標準化的郡級入口可以大幅降低前處理成本。
換句話說,這篇論文的價值不只在「資料很多」,而在「資料終於比較像資料」。這對任何要把 LLM 或傳統 NLP 套進法律場景的人,都很重要。
這篇沒有解決的地方
摘要也很誠實:LOCUS 是資料集與 access layer,不是宣告地方立法資料問題已經完全解決。郡級整合層雖然覆蓋面很大,但不是全覆蓋;原始語料雖然廣,但摘要沒有保證每份法規都已經結構化到同一個程度。
OCR 也帶來風險。論文只說它用來處理多樣化文件格式,但沒有在摘要裡交代錯誤率、驗證流程,或手動校正的比例。對法律應用來說,這些細節很重要,因為一個抽錯字,可能就會改變法條意思。
還有一個限制是下游評估資訊不足。摘要提到 ModernBERT-based 的分析器,但沒有公布任務指標,所以目前比較適合把 LOCUS 當成研究基礎設施,而不是已經被完整驗證的 benchmark 套件。
給台灣開發者的實際啟發
這篇論文其實很像一個提醒:真正能讓 AI 進入專業領域的,不一定是更大的模型,而是更好的資料層。當資料本身分散、格式混亂、缺乏標準入口時,模型能力常常被資料瓶頸卡住。
如果你在做 RAG、法遵檢索、政策比對,或任何需要 jurisdiction-aware 的系統,LOCUS 這種做法提供了一個很清楚的方向:先把資料收進來,再把資料層做平,最後才談模型。
這也說明一件事。很多看起來很「AI」的問題,最後其實是資料工程問題。LOCUS 沒有把法律 AI 一次做完,但它把最難碰到、也最容易被忽略的那一層,先打開了。
總結
LOCUS 的貢獻很明確:它把美國市郡層級的地方法規整理成可供機器處理的語料庫,並加上一層郡級整合入口,讓法律 AI 終於有機會看見這些平常很難碰到的規範。
摘要沒有提供完整 benchmark 數字,所以這篇不是在比模型誰贏誰輸,而是在證明一個更底層的命題:如果你要做真正實用的法律 AI,地方條例不能再是盲區。
對研究者來說,這是新資料源。對工程團隊來說,這是新的基礎建設。對整個法律 AI 領域來說,這是把「看不見」變成「可運算」的一步。