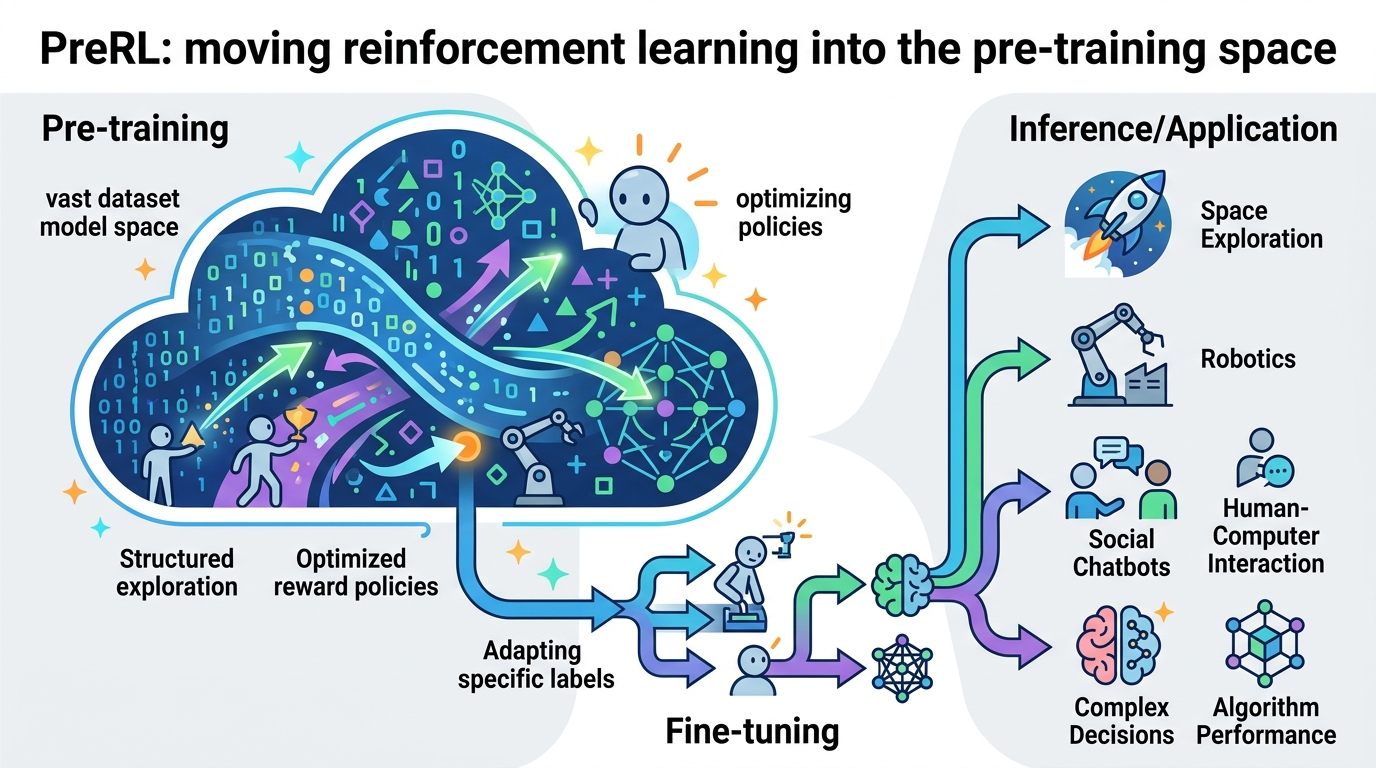
PreRL:把強化學習搬進預訓練空間
PreRL 把 RL 從 P(y|x) 轉向 P(y),直接在預訓練空間做獎勵更新,主打增強推理與探索。摘要也提到 NSR 與 DSRL 兩種設計。

大型語言模型近年常靠可驗證獎勵的強化學習來補推理能力,但這篇論文認為,問題還卡在基礎模型原本的輸出分布。它提出一個更前面的切入點:不要只調整「給定提示詞時會怎麼回答」,而是直接在預訓練空間裡,調整模型整體的生成分布。論文原文可見 From $P(y|x)$ to $P(y)$: Investigating Reinforcement Learning in Pre-train Space。
白話一點說,這不是單純把某個 prompt 的答案修正得更準,而是想把模型整個「比較會想」的空間先塑形。對開發者來說,這代表學習壓力被放到更底層:不只是「這題答對」,而是「讓正確推理更容易被走到」。
這篇摘要沒有公開完整 benchmark 細節,所以我們能確認的是方法方向、幾個量化觀察,以及作者對效果的總結;但還不能從摘要直接看出它在各任務上的完整表現表格。
這篇論文想解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
論文先從 RL with verifiable rewards,也就是 RLVR 的限制切入。RLVR 的重點是優化 P(y|x),也就是在輸入 x 給定時,讓輸出 y 的機率更高。這種做法確實能改善推理,但作者認為它仍然受限於 base model 原本就會不會產生那些路徑。
如果模型本來就偏向某些不太有用的生成軌跡,那麼你再怎麼用 RLVR 拉,也只是沿著既有分布做局部修補。論文想修的,就是這個天花板。它主張與其只改條件分布,不如直接改更底層的邊際分布 P(y)。
作者把這個訓練場域稱為「Pre-train Space」。意思不是回到傳統靜態預訓練資料那套,而是把獎勵訊號直接灌進更廣的生成空間。這樣做的目標,是讓模型的整體探索範圍更適合推理,而不是只在某個 prompt 上表現好看。
這裡還有一個背景問題:傳統預訓練靠的是靜態語料與被動學習。作者認為,當目標已經是針對推理能力做定向提升時,這種方式會產生分布落差。也就是說,模型學到的東西和你真正想優化的行為,未必在同一個空間裡。
PreRL 到底怎麼運作
這篇論文提出的方法叫做 PreRL,意思是 Pre-train Space RL。核心做法很直接:把獎勵驅動的線上更新,從只作用在 P(y|x),改成直接作用在 P(y)。作者想藉此改善模型整體的輸出空間,而不只是修某個 prompt 的局部行為。
論文同時主張,log P(y) 和 log P(y|x) 之間存在強烈的梯度對齊,而且這件事有理論與實驗上的驗證。這個說法很關鍵,因為它等於在說:優化邊際分布不只是另起爐灶,而是可以當成標準 RL 的可行替代或近似。若兩邊梯度方向相近,那麼在一個空間裡做更新,可能也能帶動另一個空間的改善。
方法裡一個重要元件是 Negative Sample Reinforcement,簡稱 NSR。論文把它描述成 PreRL 裡特別有效的推理驅動器。它的概念是從負樣本中學習,快速剪掉錯誤推理路徑,同時刺激模型出現內生的反思行為。這不是單純多給資料,而是用負例去重塑搜尋空間。
另一個設計是 Dual Space RL,簡稱 DSRL。作者把它描述為一種 Policy Reincarnation 策略。流程上,模型先用 NSR-PreRL 初始化,先把推理視野打開,再切回標準 RL 做更細的最佳化。這種兩階段設計,反映作者的判斷:先擴張可走的推理空間,再做精修,可能比一開始就硬做單一 RL 目標更有效。
論文實際證明了什麼
就摘要能看到的資訊,作者給出的主張分成兩層。第一層是理論與實驗都支持 log P(y) 和 log P(y|x) 的梯度對齊。第二層是大規模實驗顯示,DSRL 持續優於強基線。這兩點是目前最核心的結果敘述。
摘要裡唯一明確公開的數字,是 NSR-PreRL 的行為變化:transition thoughts 增加 14.89 倍,reflection thoughts 增加 6.54 倍。作者用這組數字來支持一個判斷:NSR 不只是把錯誤壓下去,還能更快地清掉不良推理空間,並刺激模型出現更多反思式的中間步驟。
這組結果的意義在於,它把「推理變強」拆成可觀察的行為訊號,而不只是最後答案對不對。對做 reasoning trace、self-correction 或 search-like generation 的團隊來說,這種訊號很有參考價值,因為它指向的是模型內部的探索方式。
但也要講清楚,摘要沒有提供完整 benchmark 細節。沒有任務名稱、沒有逐項分數、沒有完整 evaluation table。換句話說,我們可以說它宣稱優於強基線,也可以說它觀察到某些推理行為大幅增加;但不能從這份 raw 資料直接推導出它在哪些資料集上、贏了多少、或是否對所有場景都穩定。
對開發者有什麼影響
如果你在做 LLM 系統,這篇論文最值得注意的地方,是它重新定義了強化學習的作用點。它不是只把 prompt-response 的結果修正得更好,而是試著把模型的生成先驗整體往「更會推理」的方向推。這對需要多步推理、探索中間步驟、或需要模型自己找路徑的應用,會特別有吸引力。
NSR 的設計也很實用。很多訓練流程都偏向正向監督,也就是把正確答案拉高。但這篇論文提醒你,負樣本不只是拿來懲罰錯誤,它也可以主動切掉壞路徑,讓模型更容易走到反思式軌跡。對有做 chain-of-thought、校正式生成、或自我檢查流程的人來說,這是很直接的設計靈感。
DSRL 也提供一個很工程化的想法:先粗後細。先用 pre-train-space 的強化把推理空間打開,再切到標準 RL 做收斂。這種 staged optimization 的思路,往往比想用單一目標一次解決所有問題更容易管理。
- PreRL 把訓練目標從
P(y|x)推到P(y)。 - NSR-PreRL 被作者描述為能快速剪掉錯誤推理路徑。
- DSRL 結合了 pre-train-space 的擴張與標準 RL 的精修。
- 摘要公開的數字只有 14.89 倍與 6.54 倍,沒有完整 benchmark 表。
- 這篇的重點是訓練空間的重設,不是單純再做一次 RLVR。
限制與還沒回答的問題
最大的限制很明顯:目前看到的是摘要,不是完整論文。它告訴我們方法方向與幾個結果,但沒有足夠資訊去評估失敗模式、訓練成本、穩定性,或對模型規模的敏感度。
另一個還沒釐清的問題是泛化範圍。摘要說有理論與實驗上的梯度對齊驗證,但沒有說這個結論在不同架構、不同任務、不同領域是否都成立。對實務團隊來說,這會直接影響它能不能搬進現有 pipeline。
部署面也還有疑問。把更新放到 P(y) 的 pre-train space 聽起來很強,但它到底要怎麼接到既有的 RLHF 或 RLVR 流程,摘要沒有交代。作者把 PreRL 定位成標準 RL 的 surrogate,可是從這份資料還看不出整合成本有多高。
所以比較務實的結論是:這篇論文不是叫你明天就把現有 RL stack 全換掉,而是在提醒一件事——如果你的模型卡在推理深度、反思能力或探索多樣性,也許問題不只在 reward 設計,而是訓練訊號打到的層次不夠前面。PreRL 想做的,就是把學習壓力往更底層搬,先改變模型「有哪些路可走」,再來談「哪條路最對」。