Qualcomm 用軟硬整合拆 CUDA
我把 Qualcomm 的 140 億美元布局拆成一個可抄的模板:先買編譯器與 runtime,再補 RISC-V 晶片,目標不是拼規格,而是降低 CUDA 轉移成本。

我把 Qualcomm 的 140 億美元布局拆成一個可抄的模板:先買編譯器與 runtime,再補 RISC-V 晶片,目標不是拼規格,而是降低 CUDA 轉移成本。
我最近看 Qualcomm 這套打法,越看越不對勁,但又不是那種「這公司又在畫大餅」的不對勁。它比較像是:終於有人承認,AI 基礎設施不是晶片賣得快就會贏。你晶片再快,開發者不想搬,整套還是卡住。我以前也碰過這種案子,硬體團隊一直跟我說效能很漂亮,結果一問到模型怎麼搬、kernel 怎麼改、runtime 怎麼接,現場就開始沉默。這種沉默我看太多次了。
所以我看到 Qualcomm 這次不是只買晶片公司,而是連編譯器、執行層、可攜性故事一起收,我反而覺得它終於摸到痛點。這篇我不是在幫它背書,我是把它的套路拆開來看:它到底在解哪個問題、哪個地方最容易翻車、以及如果你自己在做 AI 平台,哪些段落可以直接抄。
這份拆解的起點是 Jerry Owens 在 TechTimes 的報導,內容提到 Qualcomm 投資人日公布的 Modular 收購案,以及傳出的 Tenstorrent 接觸。原文有提到「超過 140 億美元」這個量級,但我這裡只拿它當策略訊號,不拿來當行銷口號。
Qualcomm 買的不是公司,是逃生門
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
「合在一起,這兩筆交易會把超過 140 億美元壓在同一個戰略目標上:讓雲端與企業買家能在不是 Nvidia 的硬體上跑 AI 工作負載。」
翻譯一下就是,Qualcomm 不是只想多賣一顆加速器,它想賣的是「離開 CUDA 的出口」。這個差很多。因為 Nvidia 的護城河從來不只是 GPU 規格,而是整套習慣、工具、函式庫、內部 know-how,還有每個團隊早就寫死在 CUDA 裡的假設。你要別人換,不是叫他換卡,是叫他重寫工作方式。

我以前看過很多平台遷移,最常見的死法就是:demo 看起來很順,真要進 production 就開始卡。原因很簡單,開發者不是不懂性能,他們是很懂「改動成本」有多噁心。只要你一講要搬 kernel、重測邊界條件、重做 profiling、重跑驗證,大家腦中就會浮出一句話:這值得嗎?通常答案是不值得。
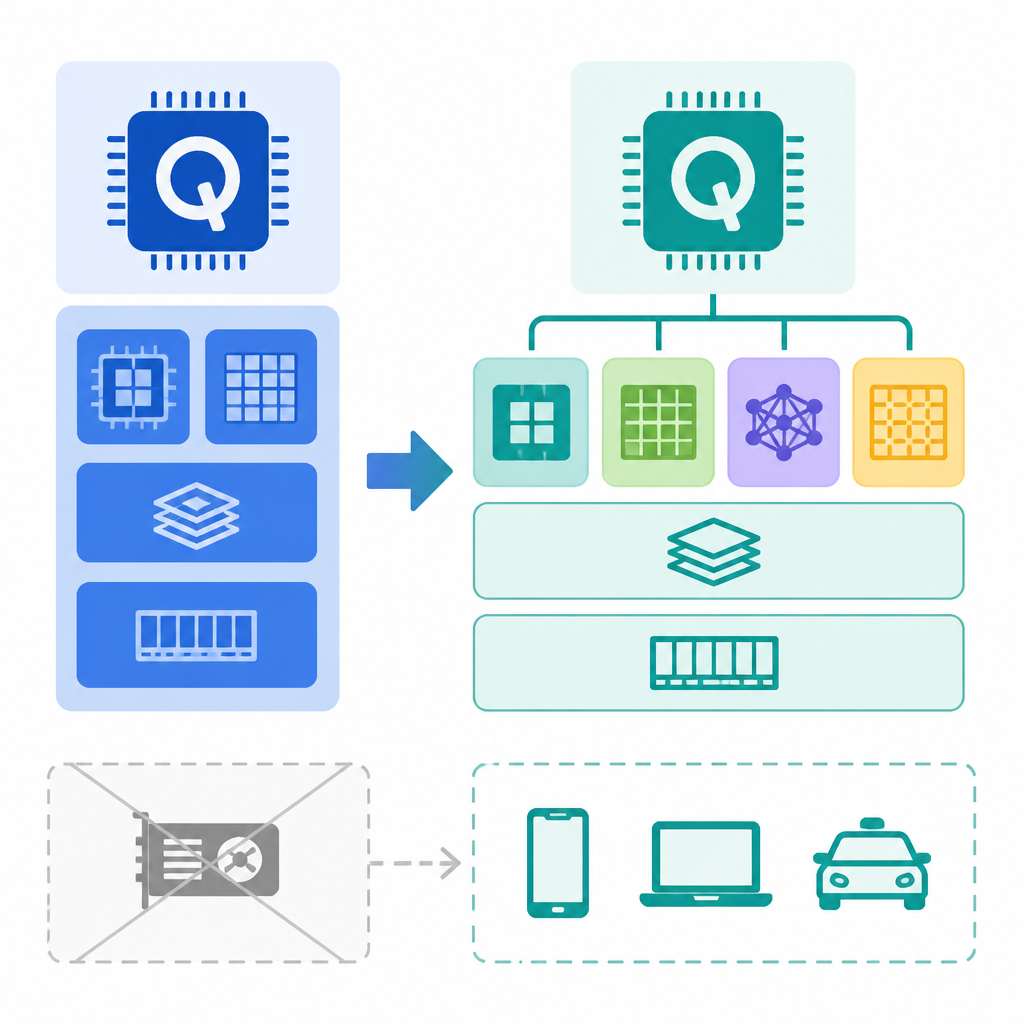
所以 Qualcomm 這次比較像是在買「降低痛苦的工具箱」。Modular 補的是編譯器與 runtime,Tenstorrent 補的是硬體與 RISC-V 路線。兩個一起看,才像一條真的逃生門,而不是一張漂亮簡報。
實操上,如果你自己在做 AI infra,我會建議你先改問法,不要問「我要支援哪顆晶片」,而是問「我能幫客戶少搬多少東西」。這句才是產品定義,不是口號。
真正的對手不是晶片,是 CUDA 習慣
TechTimes 直接點出來,Nvidia 的主導地位靠的不只硬體,還有從 2006 年一路養大的 CUDA 生態。文中也提到大約有 400 萬開發者在這個生態裡打轉。這個數字比任何 benchmark 圖都更值得怕,因為它代表的不是人數,是慣性。
白話講,開發者買的不是 FLOPS,他們買的是延續性。CUDA 代表函式庫、工具、文件、範例、社群、以及一堆公司內部已經默認存在的做法。你如果只是換一顆更快的晶片,卻要他們重寫邏輯、重學工具、重驗證行為,那你不是在賣硬體,你是在賣一個包著硬體外皮的遷移專案。
我自己碰過從一個加速器搬到另一個加速器的案子,前面總是很樂觀。大家都說:「應該不難吧?」結果一問到 custom op、量化路徑、記憶體配置、效能分析、部署一致性,整個專案就從兩週變兩季。這就是為什麼 Qualcomm 不能只買晶片公司,它一定得把編譯器那層一起拿下來。
- 硬體不是問題本身,軟體鎖定才是。
- 少一次重寫,比多一點 benchmark 更值錢。
- 要讓人換平台,先讓人覺得不痛,而不是先講規格。
實操寫法很直接:如果你在做 AI 平台,先列出客戶切換成本。你要能講清楚 code 怎麼搬、ops 怎麼搬、團隊怎麼搬。講不清楚,你就不是平台,你只是 demo。
Tenstorrent 負責硬體面:RISC-V、tile、少一點廢話
TechTimes 描述 Tenstorrent 的 Blackhole 晶片是以 RISC-V 為基礎的加速器,核心架構叫 Tensix。每個 Tensix 核心裡面有五個 RISC-V 處理器、local SRAM、矩陣與向量引擎,還有串到 mesh network 的路由器。原文也提到 Blackhole 有 120 個 Tensix 核心、16 個較大的 RISC-V 核心、32GB GDDR6 記憶體,以及 664 TFLOPS 的 BF16 效能。
這段的重點不是「它也很快」,而是它根本不是想當另一張 Nvidia。Tenstorrent 比較像是在重排計算方式:讓資料更靠近運算、減少頻繁去外部記憶體繞一圈、降低功耗浪費。這種 tile-based 的思路,特別適合 inference,因為 inference 很常不是在拼最大吞吐,而是在拼成本、局部性、以及一堆小而碎的請求能不能撐住。
我看過不少 GPU 在真實服務裡被浪費掉,原因不是不夠強,是工作負載太零散、太小、太不規則。這種情境下,硬體再猛也會閒著。Tenstorrent 的路線比較像是承認:不是所有工作都該用同一種方式跑。這個承認很務實,也很麻煩,因為一旦硬體有立場,程式設計就會變得更挑人。
原文也提到開發者得明確管理 local SRAM 的資料放置,以及在 mesh 裡的資料移動。這不是小註腳,這就是代價。你得到更好的效率,但你也逼 programmer 多想一步。這在工程上沒問題,前提是你的客戶真的願意付這個腦力成本。
實操上,如果你在設計 AI 硬體,不要裝成萬用型。你如果主打 inference,就老實講 inference;你如果主打低功耗,就老實講低功耗。買的人不是不能接受限制,他們最討厭的是你明明有限制,還硬說自己通吃。
Modular 負責軟體面:把搬家變得沒那麼痛
TechTimes 提到 Modular 是 Chris Lattner 和 Tim Davis 創立的,Mojo 語言與 MAX inference engine 的目標,是讓同一份 AI 模型程式碼能跑在 Nvidia、AMD、Intel、Qualcomm、Apple Silicon,還有多家 CPU 平台上。這件事的核心不是語言炫不炫,而是它在對抗一件很煩的事:硬體綁定。
翻譯一下,Modular 想把「選哪家硬體」變成實作細節。理想狀態是,團隊寫一次模型邏輯,換晶片時不用整組重寫。這不是把 lock-in 直接消滅,而是把它削弱。對企業採購來說,能削弱就夠了,因為很多案子卡住不是因為找不到替代品,而是替代品的遷移成本太高。
我對編譯器故事一直有點戒心,因為它們常常死在兩種地方:一種太學術,工程師看得很爽,營運團隊看不懂;另一種太半吊子,簡報很漂亮,真到 production 就露餡。Modular 的價值在於它卡在中間:不是只做語法糖,也不是只做一個能跑的殼,而是把模型碼和硬體之間那層髒事收起來。
原文還提到 Modular 在 2025 年 9 月曾以 16 億美元估值募到 2.5 億美元,而 Qualcomm 的收購價約 39.2 億美元。這個跳幅很能說明市場現在怎麼看軟體層:大家終於比較願意為「減少搬家痛苦」付錢了。
- 可攜性會降低試用門檻。
- 可攜性也會降低未來換供應商的成本。
- 這正是平台老大最不想看到的事。
實操寫法:如果你在做開發者工具,先把第一次搬移做得很無聊。越少戲劇性,客戶越敢試。不要一開始就想證明你多強,先證明你不麻煩。
為什麼 Qualcomm 兩手都要抓
這裡最容易被忽略的,是 Qualcomm 其實不能只買一邊。只買軟體,你會變成一層很聰明的相容殼,但沒有硬體差異化。只買硬體,你會變成另一顆很快、但沒人想搬過去的晶片。兩個都要,才有機會把 CUDA 的牆挖出洞。
TechTimes 的敘事其實已經把這個邏輯講出來了:Tenstorrent 提供開放的 RISC-V 硬體路線,Modular 提供 CUDA 替代的軟體路線。這兩個一起,才同時打到兩個死穴——沒有生態、沒有硬體差異。只要少一個,整個故事就會變成一半。
我以前看過很多「開放平台」專案,買家最常問的其實不是「你開不開放」,而是「我現在用你,會不會省時間,還是只是把痛苦延後」。這句話很殘酷,但很真。Qualcomm 這波如果只是把未來的自由講得很漂亮,現在的客戶還是不會動;它必須同時給一個現在就有感的經濟理由。
原文也提到 Qualcomm 預計在 2026 年底前,會開始替一家大型雲端業者出貨客製晶片。這種時間點很重要,因為它代表公司想帶著真實客戶路徑上場,而不是只拿策略簡報騙人。很好,因為簡報不會產生推論收入。
實操上,你在做平台時也一樣:相容性故事要配一個現在就能成立的性能或成本理由。只有未來彈性,客戶通常只會把決策往後拖。
我會抄的不是公司名,是這個結構
這波最值得抄的,不是 Qualcomm、也不是 Modular、甚至不是 Tenstorrent,而是它們拼起來的結構。先用開放一點的硬體路線降低供應商依賴,再用編譯器與 runtime 把遷移成本壓下來,最後用一個明確的工作負載當切口。這三段一旦接起來,故事就不是「我們也有晶片」,而是「你不用為了換硬體重寫整套」。
這種打法很務實,也很現實。它不是說開放就會簡單,而是說複雜度可以被重新分配。原本是客戶自己吞,現在是供應商幫你吞一部分。這樣的差別,對採購來說就夠大了。
如果我要把它變成內部方法論,我會這樣寫:先定義一個切口,再定義一個可攜層,最後才談硬體。不要反過來。很多團隊一開始就陷在晶片規格戰,結果做了半天,客戶只記得你很吵,沒記得你有用。
可抄的模板
# AI 平台對抗 CUDA 鎖定的內部模板(繁中版,可直接改名套用)
## 1. 先選切口,不要先談全包
我們不試圖一次取代所有 GPU 工作負載。
我們先鎖定:
- [推論 / 訓練 / 邊緣推論 / 代理式工作負載]
- [一種明確模型家族]
- [一個能算出成本差的場景]
## 2. 硬體故事要具體
我們的硬體優化重點是:
- [本地記憶體 / tile-based compute / 低功耗推論]
- [特定吞吐或延遲目標]
- [特定成本區間]
## 3. 把可攜性當產品,不是附加功能
我們會提供:
- 編譯器層
- runtime 層
- 模型匯入 / 匯出流程
- profiling 與除錯工具
- 跨硬體的部署說明
## 4. 明講搬移時會痛哪裡
對每個支援框架,文件要寫清楚:
- 哪些程式碼可以直接跑
- 哪些需要翻譯
- 哪些需要手動調整
- 會付出哪些效能代價
## 5. 用一個真實客戶把故事釘住
第一個 production 故事要是:
- 客戶類型:[雲端業者 / 企業 / OEM]
- 工作負載:[LLM 推論 / 影像 / 推薦系統]
- 成功指標:[延遲 / 成本 / 吞吐]
## 6. 不要假裝沒有代價
開發者需要管理的事情包括:
- 記憶體配置
- kernel 調校
- 模型轉換
- 硬體特定 profiling
我們不把這些藏起來,我們把它們文件化、流程化、可預期化。
## 7. 對外訊息只講一句核心話
「你不應該為了換硬體而重寫整套 AI 堆疊。」
## 8. 發版前檢查清單
- 一條可用的編譯路徑
- 一個支援的模型家族
- 一個量化過的硬體目標
- 一個可說服人的 migration guide
- 一個已經在跑的客戶案例
## 9. 成功的定義
成功不是只有更快。
成功是團隊真的能比較供應商、切換供應商,還能繼續交付。我如果要把這篇濃縮成一句話,就是:Qualcomm 不是在賣更強的板子,它是在買一條讓客戶離開 CUDA 時不至於崩潰的路。這個思路,才是你在做 AI infra 時最值得學的地方。
來源網址:TechTimes 原文。本文的策略拆解是我根據該報導,加上 Modular、Tenstorrent、Qualcomm、RISC-V 的公開資訊整理而成,原創分析多於轉述。