自蒸餾會縮小模型多樣性
這篇論文指出,自蒸餾能拉高 pass@1,卻會壓縮輸出多樣性,讓模型在分布外情境更脆弱。

這篇論文指出,自蒸餾能拉高 pass@1,卻會壓縮輸出多樣性,讓模型在分布外情境更脆弱。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:摘要無公開 benchmark 數字
- 突破點:把自蒸餾視為偏置更新
Self-Distillation Can Shrink Model Diversity 這篇論文在提醒一件事:模型看起來更準,不代表它真的更會想。作者討論的是 on-policy self-distillation,也就是模型同時扮演 teacher 和 student,並用自己抽樣出的正確示範來訓練自己。這種做法很吸引人,因為它有機會提升 pass@1,還不用另外找一個外部老師模型。
但代價也很直接。當訓練訊號一直回灌到模型自己偏好的路徑,輸出分布可能會越來越窄。對開發者來說,這不是小問題。因為很多系統真正需要的,不是第一個答案看起來漂亮,而是能產生多個不同但都合理的候選解。
這篇論文在處理什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
作者要解的是一個很現實的訓練取捨:自蒸餾可以改善平均表現,但會不會同時削弱模型的探索能力。論文把焦點放在 on-policy self-distillation,也就是 teacher 會根據一個抽樣得到的正確示範,對 student 的 rollout 給出 token-level 的密集回饋。

這個設計的吸引力在於,它可能在不依賴外部 teacher 的情況下,提升 pass@1。也就是說,模型第一個吐出的答案更容易對。但作者指出,這背後可能藏著一個副作用:rollout diversity 下降,pass@k 曲線變平。
白話講就是,當你多抽幾次時,模型沒有像你期待的那樣冒出更多不同解法,而是一直重複類似的答案。這對需要多路徑推理、搜尋、合成、或多候選挑選的工作流程,都很關鍵。
方法到底怎麼運作
這篇論文的核心設計,是用「抽樣得到的正確示範」來做自蒸餾。teacher 不是單純看 student 的輸出,而是會在某個正確 rollout 的脈絡下,評估另一個 rollout。接著,這些回饋再回到模型自己的訓練過程裡。
作者的理論分析把這件事講得更明確:最優的 self-distillation policy,會用一個 pointwise conditional mutual information 分數去傾斜 base distribution。翻成白話,就是訓練訊號不只在獎勵「答對」,還會把機率質量往那些本來就符合模型偏好的答案推過去。
這點和理想的 on-policy reinforcement learning 不一樣。論文指出,理想的 RL 設定會保留等價正確 rollout 之間的機率比例。也就是說,只要答案都對,RL 不一定會把分布壓得那麼尖;但 self-distillation 可能會放大原本就存在的機率差距,讓某些模式越來越占優勢。
用工程角度看,這代表模型學到的不只是「什麼可行」,還有「它本來就比較常做什麼」。一旦這種偏好被強化,policy 就會變得更 peaked,也更不愛探索。
論文實際證明了什麼
作者同時做了理論和實驗分析。理論上,他們指出 sampled demonstrations 的 self-distillation 會導致偏置更新;實驗上,則觀察到 rollout diversity 下降,pass@k 曲線也會變平。
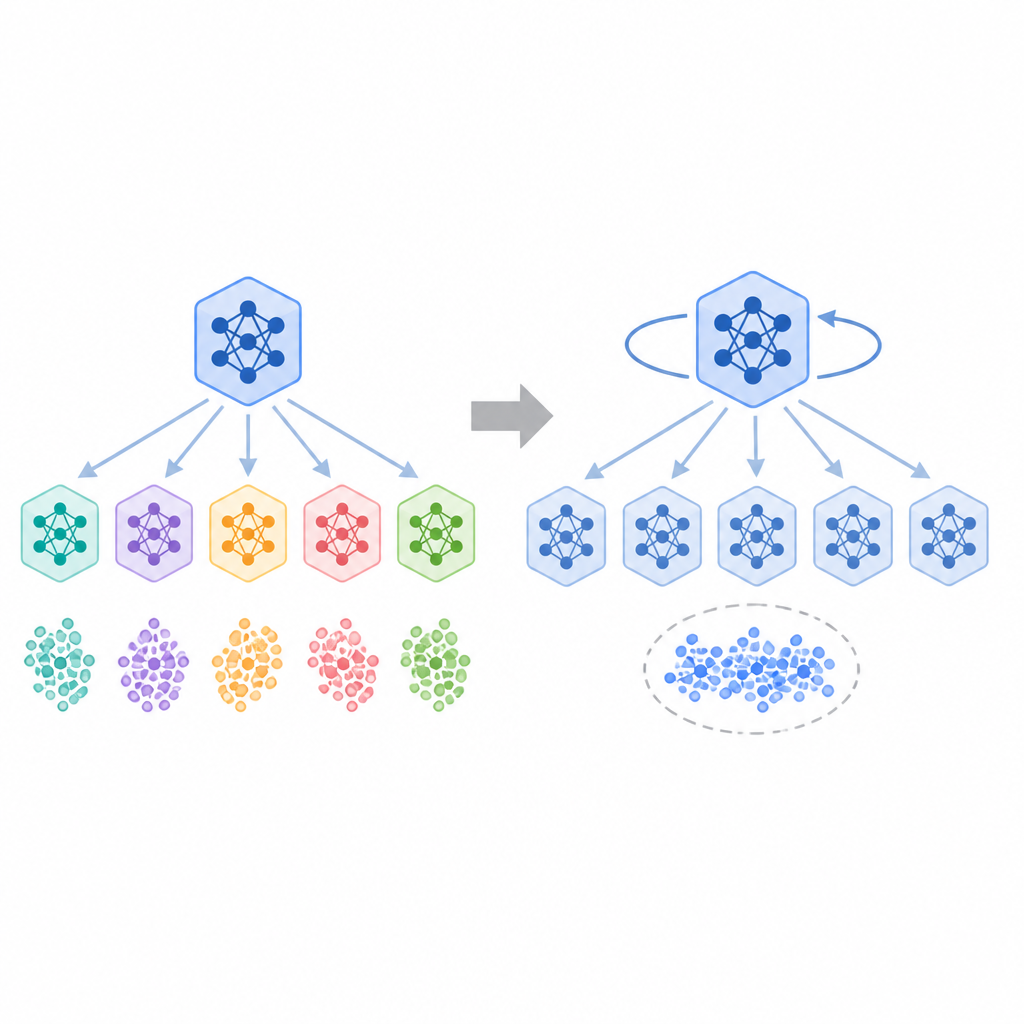
論文測了兩類任務:一個是受控的 graph path-finding task,另一個是 science question-answering benchmarks。摘要沒有公開完整 benchmark 數字,所以這裡不能硬列分數;但摘要明確說,自蒸餾模型在平均表現上可以和 RL 相當,甚至更好,同時 functional diversity 和 semantic diversity 卻更低。
這個結果很重要,因為它把「平均分數」和「輸出多樣性」拆開了。只看單一指標時,自蒸餾看起來很有競爭力;但如果你把答案的廣度也算進來,畫面就會變得不一樣。
作者還指出,這些自蒸餾模型在需要多樣策略的 out-of-distribution 設定中會失敗。這也合理:當模型過度依賴某一類解法時,遇到分布外輸入,就容易卡在同一套思路裡,錯過原本可行的替代路徑。
對開發者有什麼影響
如果你在做 agent、推理系統,或任何會一次抽多個候選答案的 pipeline,diversity 不是裝飾品。它會直接影響 beam search、reranking、self-consistency,甚至多樣本選擇到底有沒有價值。
這篇論文的警訊是:自蒸餾可能把這些好處吃掉。模型的 pass@1 可能上升,但如果 pass@k 曲線變平,你多給的 inference budget 其實換不到多少額外資訊。對評估設計、訓練策略、以及 leaderboard 解讀方式,這都有直接影響。
換句話說,訓練目標有時會掩蓋分布崩縮。當優化一直推模型去強化它本來就喜歡的答案,你可能得到一個更自信、但更單一、也更不耐分布偏移的系統。
這篇論文的限制在哪裡
摘要講得很清楚,這個方法有風險;但它沒有公開完整 benchmark 數字、ablation 細節,或實作層面的更多資訊。所以從 raw 摘要本身,我們只能確認方向,不能精準量化這個 tradeoff 到底有多大。
另外,這也不是在否定 self-distillation 本身。摘要同時說了,它在平均表現上可以和 RL 相當或更好。這代表如果你的目標就是把 top-line accuracy 拉高,這條路還是可能有價值。真正的問題是:怎麼保留這些好處,同時避免輸出多樣性塌縮。
對實務團隊來說,這篇論文最直接的提醒是:別只看 pass@1。只要你的應用需要多候選推理、穩定的抽樣廣度,或對 out-of-distribution 輸入有韌性,就應該把 diversity metrics 一起納入評估。
如果沒有這層檢查,你很可能會以為模型變強了,實際上只是它更會重複自己。
- 自蒸餾可提升平均表現,但可能壓縮輸出空間。
- 抽樣示範會強化既有偏好,不一定保留多樣正解。
- 多候選與分布外任務,不能只看 pass@1。