CARV 讓 diffusion 老師梯度更穩
CARV 用分層蒙地卡羅、重要性取樣與重用昂貴前處理,降低 diffusion-teacher 管線的梯度方差與計算浪費。

CARV 透過重用昂貴前處理與更聰明的噪聲取樣,降低 diffusion-teacher 管線的梯度方差。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:2-3x 有效計算倍率
- 突破點:分層 MC 重用
這篇論文處理的是一個很實務的問題:當 pretrained diffusion model 被拿來當「凍結的老師」時,真正昂貴的往往不是最後那個梯度公式,而是每次抽樣前後要做的上游工作。像是 rendering、simulation、encoding 這些步驟,都可能在每個樣本上重跑一次。結果就是,梯度估計一旦有高方差,算力成本也會跟著膨脹。
CARV 的重點,不是換一個新目標函數,而是把同一個目標估得更省、更穩。作者把這件事定義成 compute-aware variance-accounting:先看方差從哪裡來,再想辦法把最貴的部分重用起來,讓每次昂貴前處理能產生更多有用的梯度資訊。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
在 diffusion-teacher 工作流裡,梯度不是封閉形式的解析解,而是對噪聲等級與 Gaussian noise 的 Monte Carlo 期望。這代表你不是只算一次就結束,而是要反覆抽樣、反覆估計。只要估計器噪聲大,就得加更多樣本;樣本一多,上游成本就會被放大。

這種痛點在研究和工程都很常見。尤其當 teacher 是凍結的 pretrained diffusion model 時,系統常常把算力花在梯度之前:先渲染、先模擬、先編碼,再進入抽樣。CARV 直接把這個流程視為效率瓶頸,而不是單純的統計誤差問題。
換句話說,這篇不是在說「模型不夠準」,而是在說「你把太多算力浪費在重複估同一個東西」。這也是它最像系統優化的地方。
CARV 怎麼做
核心方法是 hierarchical Monte Carlo。白話講,就是不要把每一筆樣本都當成一次完整且獨立的昂貴計算。CARV 把昂貴的上游步驟和比較便宜的 diffusion noise 重抽樣拆開,讓前者能被後者攤提,多次利用同一份上游結果。
第二個技巧是 timestep importance sampling。它不是平均地對所有噪聲時間點撒資源,而是把更多抽樣力氣放在更重要的 timestep 上。這樣做的目的很直接:把有限的樣本數用在更能降低估計誤差的地方。
第三個技巧是 stratified inverse-CDF sampling。這是一種讓抽樣更有結構的做法,避免樣本太集中在某些重複區域,造成抽了很多次卻沒有增加多少資訊。作者把這些設計組合起來,目標就是在相同計算量下,把梯度估計的方差壓低。
值得注意的是,CARV 沒有改 loss,也沒有改 diffusion teacher 的本體。它做的是估計器層級的優化。對開發者來說,這種方法通常比較像「把現有 pipeline 做得更會省」,而不是「整個系統換代」。
論文實際證明了什麼
摘要給了兩組結果。在 text-to-3D distillation 和 attribution 實驗中,CARV 帶來 2-3x 的有效計算倍率。作者也指出,這裡的大部分收益來自 amortized reuse,也就是把昂貴上游工作重用到多個噪聲抽樣上。
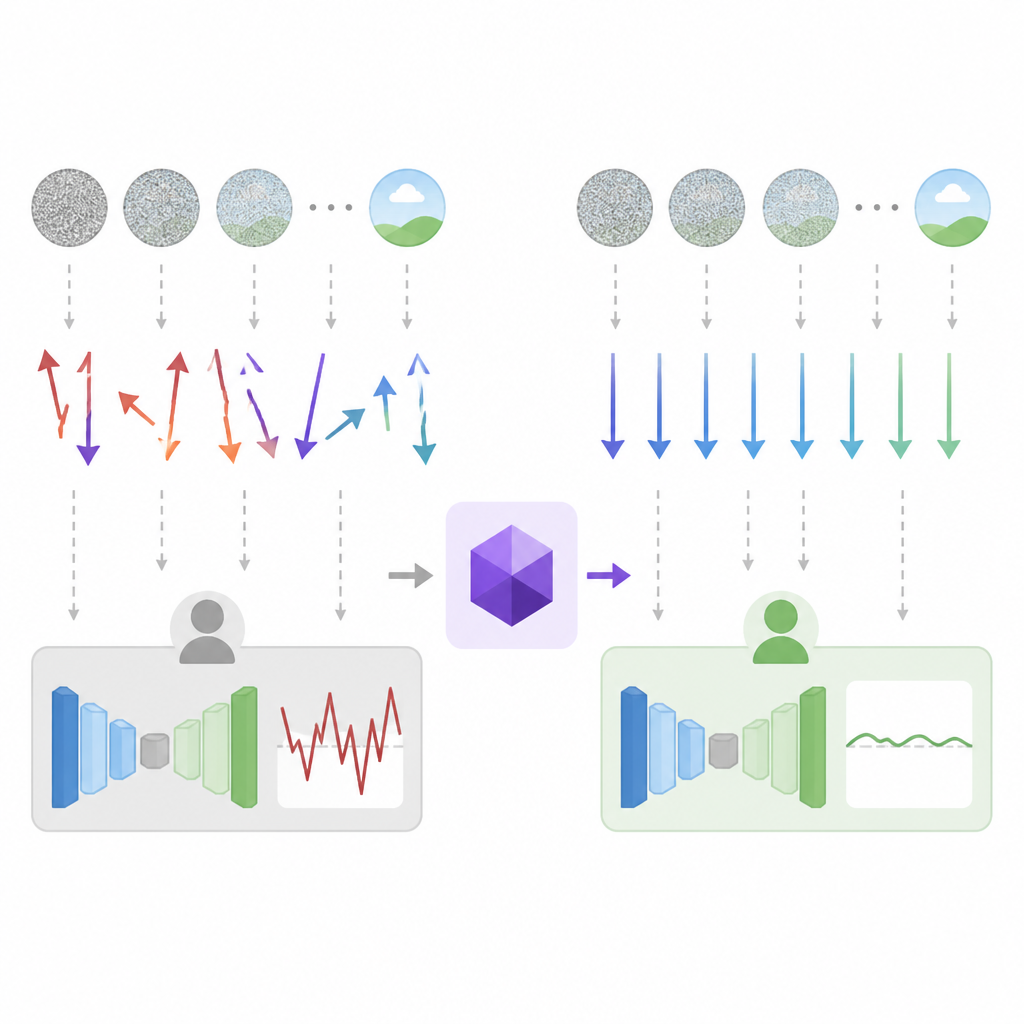
另外,重要性取樣與 stratification 還能再多帶來約 25% 的額外收益。這表示它不是只有單一技巧有效,而是重用、取樣分配、結構化抽樣三者一起配合,才把效益做出來。
在 single-step distillation 裡,CARV 也把梯度方差降了一個數量級。這個數字很醒目,但摘要同時也說,最後的 FID 沒有改善。這點很關鍵,因為它直接提醒讀者:梯度更穩,不代表最終品質一定更好。
摘要沒有公開完整 benchmark 細節,也沒有列出完整資料集數字,所以目前能確定的是「估計器變便宜、方差變小」;不能直接延伸成「全面打贏某個 baseline」。這種界線要講清楚,才不會把方法層的進步誤讀成任務層的大勝。
對開發者有什麼影響
如果你在做 diffusion-based pipeline,這篇的啟發其實很工程。很多時候瓶頸不是模型本身,而是你為了拿到穩定梯度,得反覆做昂貴的前處理。CARV 提醒你,先問一句:這些上游工作能不能被攤提到多個噪聲抽樣上?
這也代表 variance reduction 不只是數學題,而是算力配置題。當梯度估計噪聲太大,你會需要更多樣本;樣本越多,render、simulation、encoding 的成本就越高。若能把這些成本重用,整個訓練或分析流程就可能更划算。
對研究團隊來說,這種方法特別適合那些 teacher frozen、但 sampling 很重的場景。因為你不一定能改 teacher,本來就只能在抽樣與估計器上找空間。CARV 給的是一個很明確的方向:先看方差,再看計算怎麼攤。
不過限制也很明顯。摘要已經指出,在 single-step distillation 裡,雖然方差下降很多,但 FID 沒變好。這表示當其他瓶頸更大時,單純把 Monte Carlo 估計做得更漂亮,未必能推動最終指標。
這篇論文的邊界在哪裡
CARV 的定位不是新 diffusion model,也不是新任務設定。它比較像一個讓既有 diffusion-teacher 流程更省的框架。這種方法的價值,通常會在「重複估計很多次」的情境裡特別明顯。
但它也把一個老問題重新擺到檯面上:當你把估計器變好之後,下一個瓶頸會跑出來。這也是為什麼摘要裡雖然看到 2-3x 的有效計算倍率、以及單步蒸餾中方差下降一個數量級,最後還是不能直接說任務品質全面提升。
對台灣開發者來說,這類研究的實用價值在於思路,不只是數字。它告訴你,如果 pipeline 的成本卡在 Monte Carlo 抽樣,優化方向可能不是再堆更多 sample,而是更聰明地分配 sample、重用昂貴步驟、把估計器做穩。
總結來看,CARV 證明的是:在 diffusion-teacher 管線裡,降低梯度方差本身就能換來實際算力收益;但它也同時證明,估計器更有效率,不等於最終任務指標一定會同步上升。
重點整理
- CARV 針對 diffusion-teacher 的 Monte Carlo 梯度方差下手,不改原始目標。
- 它把昂貴上游工作重用到多次噪聲抽樣,並搭配重要性取樣與 stratified inverse-CDF sampling。
- 摘要顯示它能提升計算效率,但在某些設定下,方差下降不會自動轉成更好的最終指標。