CoorDex 讓人形機器人邊走邊操作
CoorDex 把人形機器人的身體與手部控制壓成 latent priors,讓它能在移動中完成精細操作。

CoorDex 把人形機器人的身體與手部控制壓成 latent priors,讓它能在移動中完成精細操作。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:20-DoF WUJI hand
- 突破點:凍結潛在先驗
人形機器人做操作任務時,常見做法是先走到目標前停下來,再開始抓取、開門或搬運。這樣比較好訓練,也比較容易做出 demo。問題是,真實環境裡的任務往往不是這種「停、做、再走」的節奏,而是要一邊移動、一邊維持接觸、一邊完成手部動作。
這篇 CoorDex 想處理的,就是這個卡點。它不是單純把 locomotion 和 manipulation 各自做強,而是把兩者之間的控制介面重新設計,讓身體移動和手部操作不要互相拖累。對開發者來說,這很重要,因為很多人形機器人的失敗,不是單一子系統不夠強,而是整體協調方式太脆弱。
這篇論文要解的痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
摘要點出兩個常見限制。第一,很多人形 loco-manipulation 系統會把任務切成不同階段:先走路,再操作,再繼續走。這能降低學習難度,但也讓機器人很難在移動中維持穩定操作。

第二,許多系統把末端執行器簡化成低自由度的開關式抓握。這對基本搬運也許夠用,但遇到更細緻的接觸型任務,就不夠了。尤其當機器人還在移動時,手部需要處理的接觸狀態更複雜,不能只靠單純的開合動作。
CoorDex 的切入點,就是把高自由度身體控制和高自由度手部控制一起處理,目標不是只讓它「會做」,而是讓它能在持續移動時做得穩。這也是這篇工作的核心價值:它把問題從單純的控制能力,推進到控制介面的設計。
CoorDex 的方法怎麼運作
這套方法的核心概念,是不要讓一個 policy 從零直接輸出所有關節命令。CoorDex 先把高維度的身體與手部控制,轉成協調過的 latent residual control。白話一點說,就是先學出一組比較濃縮的動作先驗,再讓下游 policy 在這些先驗上做小幅修正。
流程從模擬中的全身與手部示範開始。作者先從示範資料訓練 privileged motion tracking teachers,而且分成兩個老師:一個負責 humanoid body,一個負責 dexterous hand。這兩個老師之後會被蒸餾成以 proprioception 為條件的 latent priors。
接著,這些 priors 會被凍結,直接拿來當下游 residual reinforcement learning 的 action space。這一步很關鍵。因為 RL 不需要從巨大的動作空間裡重新摸索所有控制細節,而是站在一個已經帶有運動結構的 latent 介面上學習。
最後的 policy 不是單一大模型硬扛全部任務,而是用協調式架構把身體與手部 prior 結合起來。它們共享任務脈絡,但保留各自的 residual heads。這代表 locomotion 和 manipulation 可以在同一個任務目標下協同,但又不必完全綁死在一起。
這種設計思路,和很多現代 robotics pipeline 很像:先用較強的監督或模擬資訊建立可用的運動結構,再把更乾淨的控制介面交給下游 policy。CoorDex 的差別在於,它把這個模式用在了人形機器人的邊走邊操作上。
論文實際證明了什麼
先講限制。摘要沒有公開完整 benchmark 數字,也沒有列出成功率、提升幅度或表格型成績,所以這篇摘要不能讓我們直接比較它和其他方法差多少。
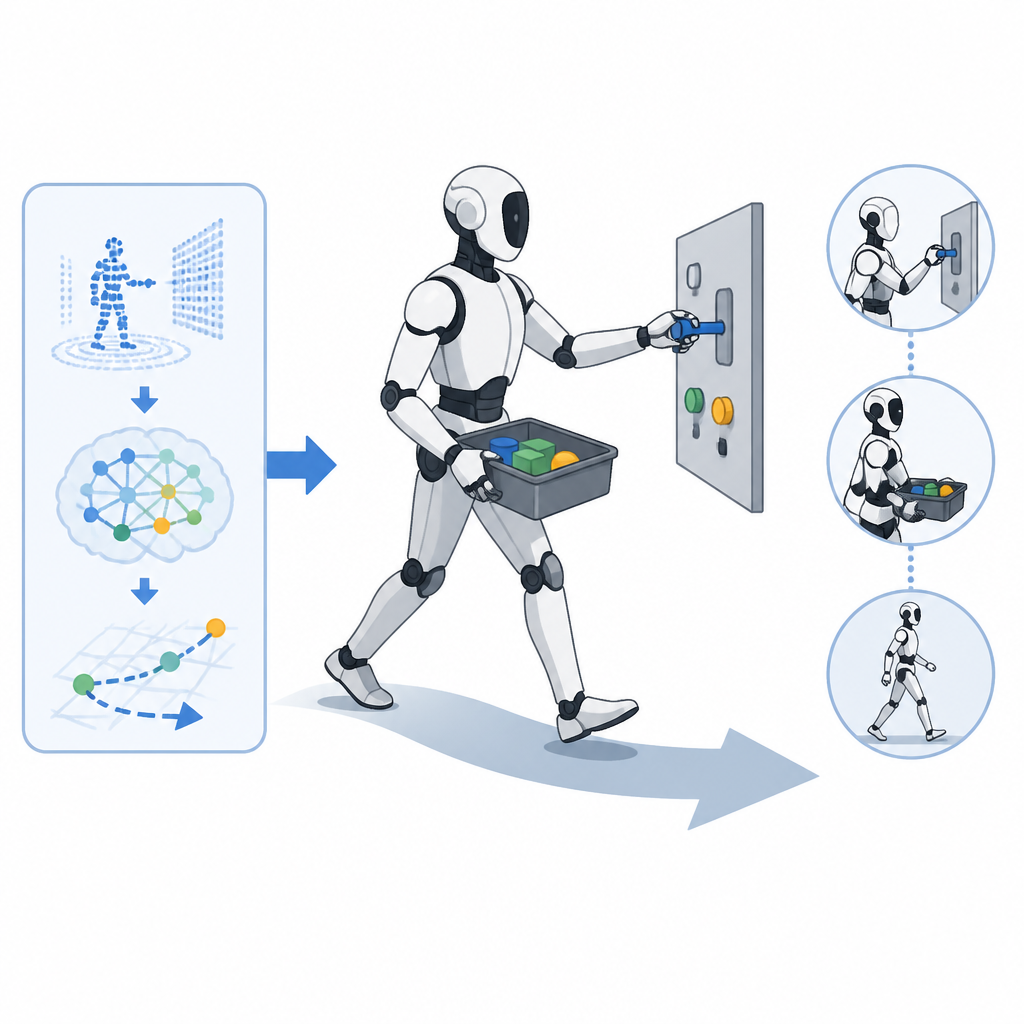
但摘要還是給了具體能力展示。CoorDex 讓一台配備 20-DoF WUJI hand 的 Unitree G1 人形機器人,能在移動中做精細操作。摘要點名的例子包括:不中斷地抓取與搬運瓶子、在移動時打開冰箱門,以及 cube pick-and-turn。
這些不是單純的手臂動作。它們都同時牽涉到身體平衡、接觸控制、手指協調與整體路徑移動。換句話說,作者想證明的不是「機器人會抓」,而是「機器人可以在走動過程中維持可用的手部操作能力」。
摘要裡最有力的證據,是 ablation 結果。作者說,在 walk-grasp-carry 任務上,joint-space PPO 會失敗,joint-space hand control 也會失敗,monolithic latent prediction 同樣失敗。這表示問題不只是演算法名字換一個而已,而是控制空間的結構真的會影響能不能學起來。
從這個結果看,CoorDex 的貢獻不是單純提升某個 reward,也不是靠更大算力硬堆出來。它比較像是在說:如果你想做連續的 dexterous humanoid 行為,先把 action interface 設計對,比單純擴大 policy 規模更重要。
對開發者有什麼啟發
如果你在做人形機器人,這篇很像是在提醒一件事:把 locomotion 和 manipulation 切成兩段,雖然好訓練,但也可能把真正難的整合問題藏起來。只要機器人還要邊走邊抓,控制介面就會變成瓶頸。
這對已經在用 imitation learning、motion priors 或 hierarchical policy 的團隊特別有參考價值。CoorDex 的思路是,當任務是 contact-rich、而且自由度很高時,凍結後的 learned prior 可能比原始 joint-space control 更適合當 action interface。
另一個實作上的啟發,是它把 privileged teachers、proprioception-conditioned priors 和 residual learning 串成一條管線。這種做法很符合現在 robotics 的常見路線:先用模擬或額外資訊把運動先驗學好,再把較穩定的控制空間交給下游 policy 微調。
不過,這也帶來一個現實問題:這類 latent-prior 系統通常很吃 embodiment。摘要只提到 Unitree G1 和 WUJI hand,沒有說它對不同平台的泛化狀況,也沒有講訓練成本或 runtime 細節。對實務團隊來說,這些都是落地時一定會問的事。
還有哪些限制沒講清楚
這篇摘要沒有公開完整 benchmark 數字,所以我們不能知道提升到底有多大,也不能判斷它在不同任務上的穩定性。摘要也沒有說訓練時間、資料量、模擬設定或硬體執行細節。
另外,摘要雖然展示了幾個任務,但沒有說這套方法能不能外推到更多物體、更多環境,或更複雜的操作序列。也就是說,目前能確定的是它在列出的 demo 任務上有效,但還不能直接推論成通用解法。
即便如此,這篇的方向仍然很清楚。它把人形 loco-manipulation 看成控制介面的問題,而不是單純的 policy size 問題。這個 framing 如果成立,對後續想做連續動作的人形機器人研究,會是很實用的設計模板。
總結
CoorDex 的重點,是用凍結的 latent priors 和 coordinated residual learning,讓人形機器人的身體控制與手部控制協同起來。摘要展示的結果顯示,這條路有機會讓機器人在移動中完成更細緻的操作,而不是每次都先停下來再做事。
- 它把高維度身體與手部控制壓成可重用的 latent priors。
- 它用分開的 residual heads 來協調 locomotion 與 dexterous manipulation。
- 它在 Unitree G1 加 20-DoF WUJI hand 上展示了邊走邊抓、開冰箱、cube pick-and-turn 等任務。
對開發者來說,這篇最直接的訊息是:如果你想讓人形機器人真的「動起來還能操作」,控制介面本身,可能和 reward 設計一樣重要。