DexCompose 讓手部技能可重用
DexCompose 用手指級的動作分工,把已訓練好的靈巧手策略組成多任務操作,並在 16 個任務上達到 77.4% 平均成功率。

DexCompose 用手指級的動作分工,把已訓練好的靈巧手策略組成多任務操作。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:16 個任務、77.4% 平均 composite success rate
- 突破點:手指級動作 ownership
靈巧手的難,不只是在單一任務做對。更麻煩的是,當你想在既有技能上再疊一個新任務,原本穩住物體的動作,可能會被新的控制訊號打亂。DexCompose 就是在處理這種「保住原本狀態」和「執行新任務」互相打架的問題。
這篇論文的重點,不是再訓練一個更大的單一控制器,而是把已經學好的手部策略拿來重組。對做機器手、抓取、操作的開發者來說,這很實際:如果技能可以重用,新的任務就不一定要從頭學一次。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Dexterous manipulation 的核心痛點是 interference。手上每根手指都在影響接觸、摩擦、姿態和物體狀態。當你把第二個任務加進來,動作衝突很容易發生。原本該穩住的地方被動到了,原本該改變的地方又被保守策略卡住。
摘要把這件事描述成一種 destructive tradeoff:一邊要保留既有 manipulation outcome,一邊又要執行新任務。這不是單純的「先做 A 再做 B」就能解。因為在靈巧手上,兩個任務常常是同時爭搶同一組關節、同一個接觸面、同一個穩定條件。
所以 DexCompose 想解的不是「怎麼把兩個 policy 串起來」,而是「怎麼讓手的控制空間先分工」。它的假設很直接:如果能清楚分出哪些動作是用來保護原本狀態,哪些動作是用來完成新任務,干擾就能下降。
方法怎麼運作
DexCompose 被描述成一個 role-aware residual composition framework。白話一點,就是它不是把兩個全手策略硬疊在一起,而是先找出它們各自應該負責的部分,再用 residual 的方式做組合。
第一步,是從第一個技能的成功 post-task states 蒐集資料。接著,方法會做 release tests,並針對候選 finger masks 去測試哪些手指真的需要維持這個狀態。這一步很像在問:哪些手指是「穩定物體」的關鍵,哪些手指其實可以拿去做別的事。
這個 finger-level 的分析,最後會變成明確的 action ownership。某些手指被分派去保住既有結果,其他手指則被分派給新任務。這就是所謂的 role-aware:不是平均混合兩個 policy,而是先定義每一部分手到底該守住什麼、該改變什麼。
接著,框架會訓練兩個不對稱的 residual modules。第一個是 bounded residual stabilizer,用來限制保留任務的偏移,避免原本技能漂掉。第二個是 context-aware residual,用來調整 frozen downstream policy,但它只會在分配給新任務的 action subspace 裡運作。
這種不對稱設計很關鍵。論文的意思不是「兩個任務都一起學、一起改」,而是保留和適應本來就是不同的控制問題,所以應該交給不同的 residual 機制處理。
論文實際證明了什麼
摘要提到的評估涵蓋 16 個 composite dexterous manipulation tasks。這些任務橫跨 4 種 object-retention skills 和 4 種 downstream interactions。就摘要資訊來看,這比只做單一 demo 來得完整,至少說明方法不是只在一個小場景裡有效。
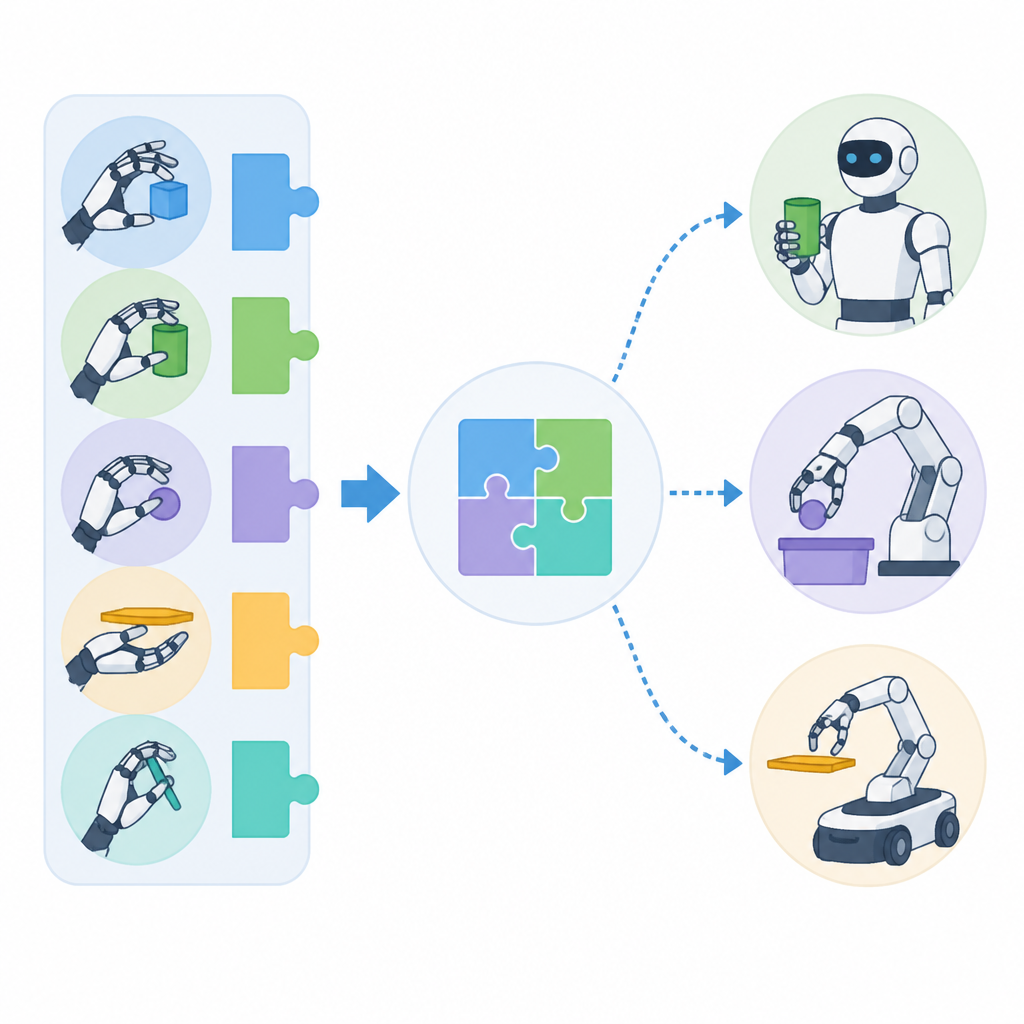
唯一公開的具體數字,是 77.4% 的平均 composite success rate。摘要沒有再提供 per-task breakdown、baseline 對照表、ablation 數字,或其他更細的 benchmark 細節,所以目前只能確認這個平均成功率,而不能把它解讀成全面勝出。
不過,這個結果已經足以支持論文的主張:如果把動作 ownership 做清楚,再搭配雙 residual 結構,技能組合就有機會比傳統 policy chaining 更穩。換句話說,這篇不是在說「單一 policy 更強」,而是在說「可組合性本身可以被設計出來」。
同時也要注意,摘要沒有交代硬體、訓練成本、延遲、失敗模式,這些對實作很重要的資訊都沒有公開。對工程端來說,這代表目前看到的是研究方向,不是可以直接拿去部署的完整 recipe。
對開發者有什麼意義
如果你在做 manipulation 系統,這篇最有價值的地方是「重用」。訓練一個穩定的靈巧手策略本來就貴,而每加一個新任務,干擾風險就跟著上升。能夠保留舊技能、再疊上新技能,理論上可以降低重新訓練的成本。
finger mask 的設計也很值得注意。它讓組合方式更可解釋。不是只靠網路自己學著不要互撞,而是直接把控制責任分給不同手指。這對 debugging 很有幫助,因為你比較容易看出是哪一部分在維持穩定,哪一部分在推進新任務。
但這個方法仍然有前提。它依賴已經訓練好的 full-hand policies,也依賴能夠找到有效的 post-task states 和 release behavior。也就是說,它比較像是「把既有技能組合得更好」,不是「取代技能學習本身」。
限制和還沒回答的問題
摘要沒有說明,這個方法對 pretrained policies 的品質有多敏感。若底層技能本來就不穩,finger-level ownership 是否還能維持效果,摘要裡看不出來。
另一個問題是泛化。不同物體、不同 grasp、不同手型,會不會需要不同的 finger masks?摘要沒有提供這方面的資訊。也沒有說明當穩定任務和新任務的衝突更劇烈時,這套方法會不會失效。
還有擴展性。這篇摘要描述的是兩個 pretrained policies 的 composition,但真實機器人系統常常不是兩段式,而是更長的技能鏈或分支任務圖。摘要沒有交代這種 ownership 機制能不能平順延伸到更多技能。
所以目前最合理的解讀是:DexCompose 提供了一個結構化的組合框架,但它還不是通用解法。它證明的是「分工式組合」這條路值得走,不是已經把所有靈巧手任務都解完了。
總結
DexCompose 的核心訊息很清楚:靈巧手要做多任務操作,關鍵不只是學得更強,而是把控制空間分得更清楚。它用手指級 action ownership 和兩個不對稱 residual,讓既有技能可以被拿來重組。
從摘要能確定的結果來看,這個方法在 16 個 composite tasks 上拿到 77.4% 平均成功率。雖然缺少更完整的 benchmark 細節,但至少說明「技能可組合」不是空想,而是可以被方法化處理的問題。
對做機器手、操作控制、技能庫管理的團隊來說,這篇的啟發很直接:與其一直追求單一 policy 包辦全部,不如思考怎麼讓策略之間可以分工、接力、重用。
- 它把手部控制拆成保留與適應兩種角色。
- 它用 finger masks 和 residual modules 降低任務干擾。
- 摘要只公開平均成功率,沒有完整 benchmark 細節。