用 LangGraph 做出代理式 RAG 系統
這篇操作指南帶你把基本檢索應用升級成代理式 RAG,完成 PDF 轉檔、向量索引、LangGraph 工作流與可切換模型的問答系統。

這篇教你把基本檢索應用升級成代理式 RAG,完成 PDF 轉檔、向量索引、LangGraph 工作流與可切換模型的問答系統。
這篇給想把文件問答做得更穩、更能追問的開發者看。照著做完,你會得到一個可在本機跑起來的代理式 RAG 專案,能匯入 PDF、建立混合式向量索引、執行 LangGraph 流程,並用可切換的 LLM 供應商回答問題。
這份流程也適合拿來當學習路線,先跑筆記本版本理解資料流,再切到模組化應用,把自己的模型、嵌入向量或文件格式接進去。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Python 3.10 或 3.11
- Git 已安裝且可正常使用
- 本機已安裝 Ollama,或備妥 OpenAI、Anthropic、Google 的 API 金鑰
- Qdrant 已在本機執行,或已規劃好本機磁碟路徑
- 至少一份要建立索引的 PDF 文件
- 可存取 GitHub 原始碼 與 LangGraph 文件
- 已安裝專案需求套件,包含 LangChain、Qdrant、PyMuPDF
Step 1: 複製專案倉庫
先把專案拉到本機,才能同時查看筆記本流程與模組化應用流程,確認你接下來要改哪一段。

git clone https://github.com/GiovanniPasq/agentic-rag-for-dummies.git
cd agentic-rag-for-dummies
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt你應該看到 notebooks、project、assets 等資料夾,且套件安裝完成,沒有缺少套件的錯誤訊息。
Step 2: 設定模型與儲存路徑
這一步的目的,是先把模型提供者、嵌入模型與本機儲存位置定義好,讓代理流程在檢索時有固定的運作環境。
export OPENAI_API_KEY="your-key" # 或 ANTHROPIC_API_KEY / GOOGLE_API_KEY
ollama pull qwen3:4b-instruct-2507-q4_K_M
mkdir -p docs markdown_docs parent_store qdrant_db你應該看到 Ollama 顯示模型已可用,並且 docs、markdown_docs、parent_store、qdrant_db 這些資料夾都已建立。
Step 3: 將 PDF 轉成 Markdown
這一步的目的,是把來源文件標準化成 Markdown,讓後續切塊更穩定,也能保留標題、段落等結構資訊。
python -c "from project.pdf_utils import pdfs_to_markdowns; pdfs_to_markdowns('docs/*.pdf')"你應該看到 markdown_docs 內出現對應的 .md 檔案,而且每份檔案都能直接用文字編輯器打開閱讀。
Step 4: 建立階層式索引
這一步的目的,是建立父子切塊的檢索架構,讓小切塊負責提高命中率,父切塊負責在生成答案時補回上下文。
python -c "from project.indexing import build_index; build_index()"你應該看到 Qdrant collection 已建立,子切塊已寫入向量資料庫,父切塊 JSON 也已輸出到 parent_store。
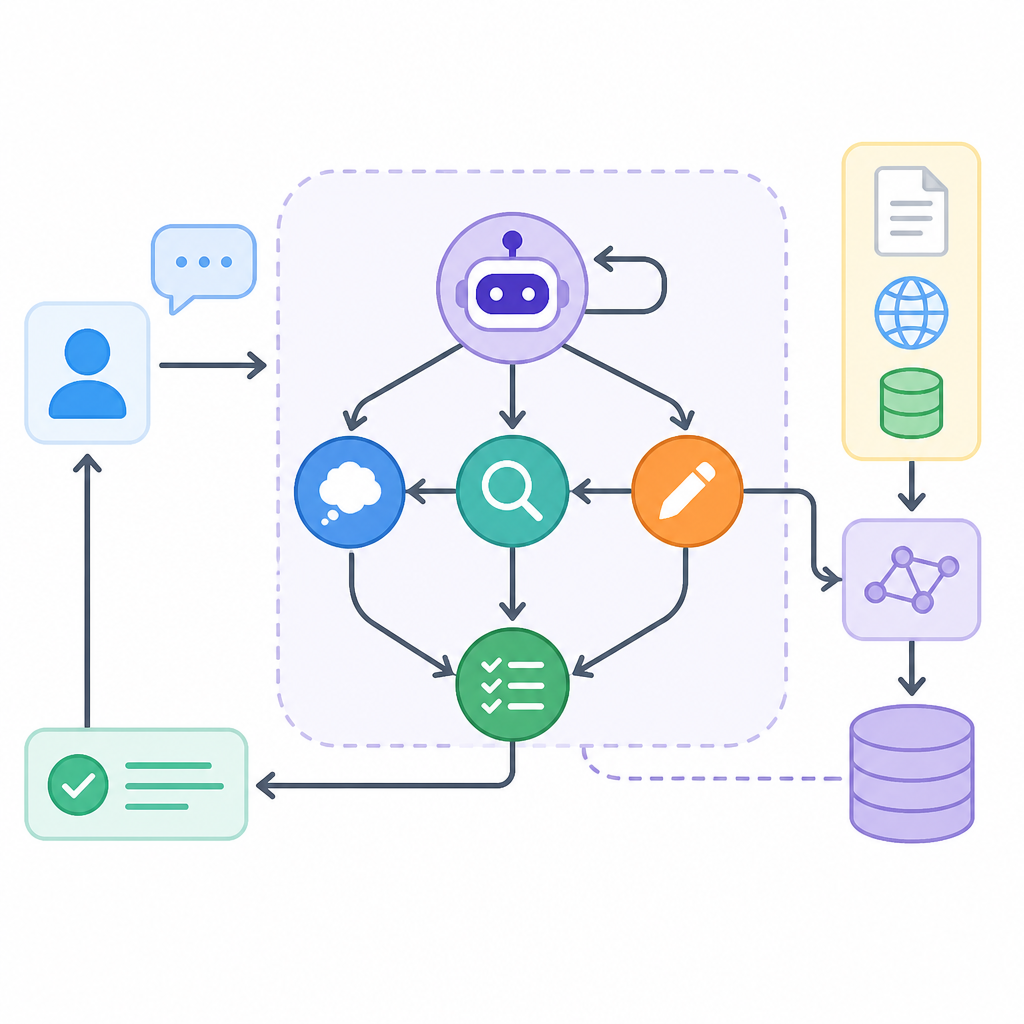
Step 5: 啟動 LangGraph 代理流程
這一步的目的,是把查詢改寫、缺漏澄清、檢索與答案生成串成一條工作流,讓系統不只回傳文件片段,而是回傳可讀答案。
python -m project.app你應該看到圖流程依序跑過對話摘要、查詢改寫、檢索與回應生成,最後輸出的是完整回答,而不是原始文件堆疊。
Step 6: 測試多段問題
這一步的目的,是確認代理能把複雜問題拆成多個子查詢,再把結果整合成一段連貫回答。
JavaScript 是什麼?Python 是什麼?你應該看到兩條檢索路徑依序或平行經過工作流,最後產生一個同時涵蓋兩個主題的整合答案。
| 指標 | 基準/優化前 | 結果/優化後 |
|---|---|---|
| 檢索流程 | 單次通過的基本 RAG | 具備澄清、自我修正與多步推理的代理式 RAG |
| 文件上下文 | 只有小切塊 | 父子切塊並用,兼顧精準與上下文 |
| 模型支援 | 單一供應商 | 以 Ollama 為主,並可切換 OpenAI、Anthropic、Google |
常見錯誤
- 使用太小的本機模型,導致工具指令常被忽略。修法:改用 7B 以上模型,或換成較強的雲端聊天模型。
- 跳過 Markdown 轉換步驟,讓切塊結果不穩定。修法:先轉檔再建立索引,保留標題與段落結構。
- 忘記建立 Qdrant 儲存路徑。修法:先建立本機資料夾,再執行索引,或把客戶端指向正確的資料庫路徑。
接下來可以看什麼
等本機流程跑通後,可以把自己的文件集接進來,替換嵌入模型或聊天供應商,並加入 Langfuse 與 RAGAS 追蹤評估,先量測檢索品質再上線。