C-DIC compresses long dialogue memory turn by turn
C-DIC keeps long dialogue memory stable by revising compact per-thread context instead of reprocessing everything.

C-DIC keeps long dialogue memory stable by revising compact per-thread context instead of reprocessing everything.
- Research org: Unspecified in arXiv abstract
- Core data: Stable inference latency and perplexity over hundreds of dialogue turns
- Breakthrough: Revisable per-thread compression with retrieve, revise, and write-back
Context-Driven Incremental Compression for Multi-Turn Dialogue Generation is about a problem every engineer building conversational systems eventually runs into: the context window keeps growing, and so does the cost of doing anything useful with it. The paper argues that both naive truncation and one-shot summarization can damage fidelity, while many existing compressors fail to share memory across turns or update old memories when the conversation changes.
The practical appeal here is not just saving tokens. It is about keeping a dialogue model responsive and consistent as the exchange gets longer, without letting old mistakes or stale summaries snowball. The authors frame that as a robustness problem as much as an efficiency problem, which is a useful way to think about any multi-turn system that has to remember, revise, and act.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Modern conversational agents usually condition on the full dialogue history at each turn. That sounds straightforward, but in practice it means redundant attention and encoding work that grows with conversation length. The longer the chat, the more compute gets spent re-reading the same material, and the more likely the system is to lose track of what matters.
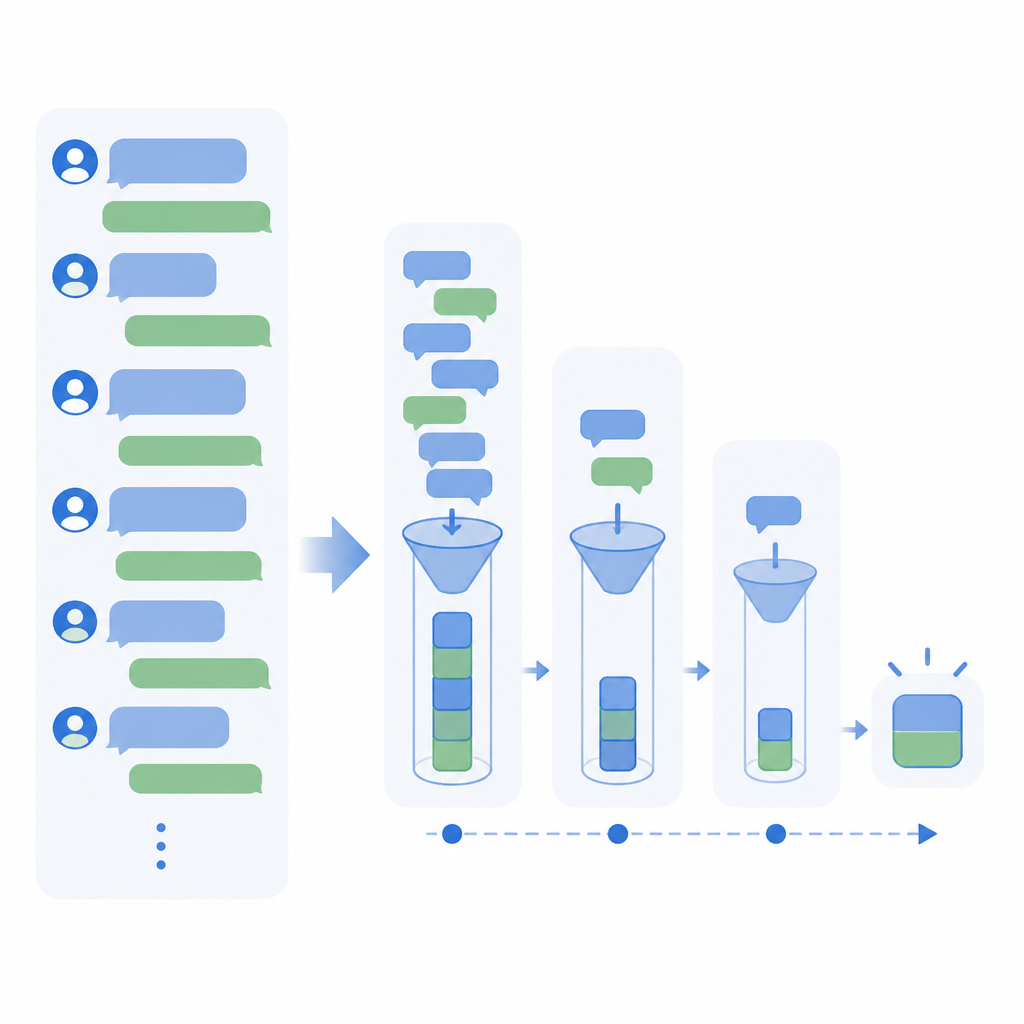
The abstract says naive truncation or summarization degrades fidelity. That matters because the easy fixes are often the ones teams reach for first when context gets too large. Truncation can drop important details. Summarization can compress away nuance or introduce drift. And if the compressor cannot revise earlier memory, the model may keep carrying forward stale or incomplete information.
The paper also says existing context compressors lack cross-turn memory sharing or revision. In other words, they may compress each turn in isolation, which is fine for short interactions but brittle for long ones. The result is information loss and compounding errors as the dialogue continues.
How C-DIC works in plain English
The core idea behind Context-Driven Incremental Compression, or C-DIC, is to treat a conversation as a set of interleaved contextual threads rather than one flat stream of text. Instead of repeatedly encoding the whole history, the system stores compact compression states for each thread in a single dialogue memory.
That memory is not static. At each turn, C-DIC runs a lightweight retrieve, revise, and write-back loop. It pulls in the relevant compressed state, updates stale memories when new information changes the picture, and writes the revised state back into memory. The point is to share information across turns while still allowing earlier context to be corrected rather than frozen forever.
This is a small but important design shift. A lot of context compression methods are optimized for shrinking input, but not for living inside a changing conversation. C-DIC is trying to make compression incremental and revisable, which is closer to how real dialogue behaves. People backtrack, clarify, contradict themselves, and add new constraints. A useful dialogue memory has to handle that.
The paper also adapts truncated backpropagation-through-time, or TBPTT, to the multi-turn setting. The abstract’s claim is that this lets the model learn cross-turn dependencies without requiring full-history backpropagation. For developers, that means the training setup is designed to capture longer-range conversational structure without paying the full cost of backpropagating through every past token in every turn.
What the paper actually shows
The abstract says the authors first revisit context compression under conversational dynamics and empirically present its fragility. That is an important setup: before proposing C-DIC, they are claiming that the usual assumptions behind context compression break down once the dialogue becomes genuinely multi-turn and dynamic.
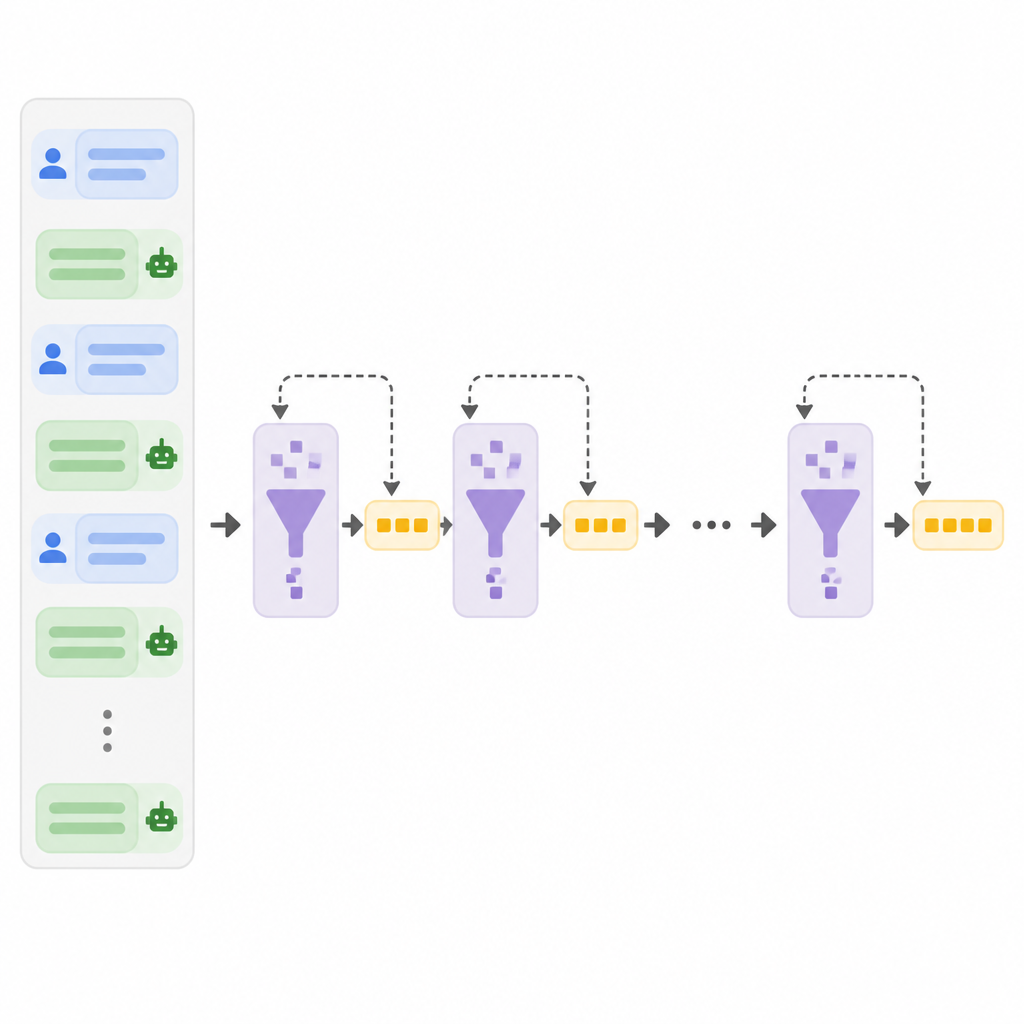
On the results side, the paper says extensive experiments on long-form dialogue benchmarks demonstrate superior performance and efficiency for C-DIC. The abstract does not list the benchmark names or exact scores, so there are no per-task numbers to report here. It does, however, call out one concrete behavior: C-DIC shows stable inference latency and perplexity over hundreds of dialogue turns.
That stability claim is the most actionable result in the abstract. In long-context systems, average performance numbers can hide a lot of pain. A method that looks good at 10 turns but degrades badly at 100 turns is not very useful in production. The paper’s emphasis on stable latency and perplexity over hundreds of turns suggests the method is designed for long-horizon use, not just short demos.
Because the abstract does not provide exact benchmark values, it is not possible to compare C-DIC against specific baselines by percentage or absolute score from the source alone. What you can safely take from the note is that the authors report better efficiency and better dialogue quality behavior, with a particular focus on long-run stability.
Why developers should care
If you are building a chat agent, support assistant, game NPC, tutoring system, or any other multi-turn interface, context management is one of the hidden costs that can dominate the system design. You can always throw more tokens at the problem for a while, but that quickly gets expensive and fragile. A method like C-DIC points toward a more structured memory layer that compresses continuously instead of periodically restarting from scratch.
The retrieve, revise, and write-back pattern is especially relevant for production systems that need to remember facts across turns while still correcting them when the user changes direction. That is a common failure mode in real deployments: the system remembers too little, or it remembers the wrong thing for too long. C-DIC is explicitly trying to make memory revision part of the algorithm, not an afterthought.
There is also a training-side takeaway. TBPTT adapted to multi-turn dialogue suggests one path for scaling learning without full-history backpropagation. That matters if you are experimenting with longer conversational traces and want to keep training manageable. Even if you do not adopt this exact method, the paper reinforces a broader lesson: efficient dialogue modeling is not only about inference tricks, but about how memory is represented and updated during training.
Limits and open questions
The abstract is strong on mechanism and broad outcome, but light on the details a practitioner would want before implementation. It does not specify the benchmark names, the exact efficiency gains, or the model sizes used in the experiments. It also does not explain how the per-thread decomposition is learned in enough detail to judge how easy it would be to port into an existing stack.
Another open question is how well the approach generalizes outside long-form dialogue benchmarks. The abstract focuses on multi-turn dialogue generation, so it is reasonable to treat the method as dialogue-specific unless the full paper shows broader applicability. It also does not say how the method behaves when conversations branch heavily, involve many simultaneous entities, or require strict factual grounding over very long sessions.
Still, the direction is clear. The paper is arguing that long-context dialogue should be managed as a living memory system, not a static blob of text. For engineers, that is a useful mental model even if you never ship C-DIC itself. If your product depends on long conversations, you need a way to compress, revise, and reuse context without letting the memory layer become the bottleneck or the source of drift.
In that sense, C-DIC is less about a single benchmark win and more about a design principle: make dialogue memory incremental, revisable, and aware of turn structure. That is the kind of idea that tends to matter when you move from toy chats to systems people actually rely on.
Bottom line
C-DIC proposes a compact, revisable memory loop for long dialogue and reports stable behavior over hundreds of turns. The abstract does not give enough numeric detail to make a hard performance claim beyond that, but it does make a convincing case that long-horizon dialogue needs more than truncation or one-shot summarization.
- It targets the real cost center in long chats: repeated re-encoding of growing history.
- It updates memory incrementally, which helps avoid stale summaries and compounding errors.
- It pairs the compression idea with TBPTT to learn cross-turn dependencies more efficiently.
// Related Articles
- [RSCH]
Explainable RL for Air Traffic Control
- [RSCH]
Skill Self-Play lets LLMs co-evolve skills
- [RSCH]
SM4RT brings rigid motion into 4D reconstruction
- [RSCH]
Prompt engineering turns codegen into a repeatable workflow
- [RSCH]
CLEAR prompts turn AI search into usable answers
- [RSCH]
Prompt engineering in 2026: the cheat sheet