Fable 5解禁后只剩更窄的能力
我把 Fable 5 的“解禁”拆开看,顺手整理成一份可直接复用的模型上线检查模板。

我把 Fable 5 的解禁和能力收紧拆成了一份可复用模板。
我最近一直在盯着一件很烦的事:模型明明“回来了”,但你一上手就发现,它回来的不是原样。接口还在,名字还在,公告也写得挺像那么回事,可真正影响你交付的那些能力,被一层层收紧之后,体验就变得别扭了。你会以为自己在恢复工作流,实际上是在重写工作流。最让我不舒服的不是限制本身,而是这种“先让你以为能继续用,再告诉你只能这样用”的节奏。做开发久了,我对这种变化特别敏感,因为它会直接打断上线节奏、评测基线、权限配置,还有团队里那套默认假设。
我这次看的,就是 Anthropic 的 Fable 5 和 Mythos 5 重新上线这件事。表面上是“解禁”,实际上更像是一次按住手脚后的回归。于是我干脆把这篇拆开,不讲空话,只讲这类事件对我们做模型接入、上线审查和风险控制到底意味着什么。
触发我写这篇的是这条中文解读,原文在 知乎专栏。它转述了 Anthropic Fable 5 重新获准上线的消息,核心信息很明确:模型回来了,但能力边界也被重新画过了。这里我会把它当成一个“模型恢复上线但权限缩水”的案例来拆,不替原文下结论,只把可复用的部分拎出来。
别把“重新上线”当成“恢复原状”
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
经历数周限制风波后,Anthropic 的 Fable 5 终于获准重新上线,但代价是核心能力被大幅收紧。
这句话我读完第一反应不是“太好了”,而是“那你到底恢复了什么”。很多团队一看到模型重新可用,就默认之前的流程可以原封不动接回去。问题是,真正麻烦的从来不是“能不能调用”,而是“还能不能按原来的方式调用”。

What this actually means is:上线状态和能力状态是两码事。一个模型可以重新出现在控制台里,但它的工具调用、输出边界、上下文策略、可访问区域,可能已经不是你之前测过的那一版。
我自己吃过这种亏。以前接过一个第三方模型 API,供应商说“恢复服务”了,我们就照着旧配置回滚。结果一跑,发现同样的 prompt,输出长度短了一截,工具调用也更保守,原先依赖的自动分类链路直接掉了一半准确率。那次之后我就不再把“恢复”两个字看得太乐观。
How to apply it:你看到模型“解禁”或“恢复上线”时,先别急着改文案发公告,先做三件事:
- 重新跑一遍基准测试,不要复用旧结果。
- 检查能力范围是否变化,比如工具、长上下文、图片、文件、区域限制。
- 把“恢复可用”写成“恢复到什么程度可用”,别写得像完全没变。
如果你做的是平台侧产品,这一步尤其重要。用户不在乎你的内部状态机怎么切,他们只在乎“昨天能做的事今天怎么不行了”。
出口限制这回事,最先打到的是集成层
这次消息里一个很关键的点,是美国商务部先解除对 Anthropic Fable 5 和 Mythos 5 的出口限制,然后 Anthropic 才在 X 上确认相关动向。对外行来说,这像是政策新闻;对做集成的人来说,这其实是在提醒你:模型可用性不是纯技术问题,它和地区、合规、分发范围绑得很死。
What this actually means is:你不能只看模型 API 文档,还得看它背后的地理和合规条件。今天能调,明天不能调,很多时候不是你代码错了,是你部署区域、账号主体、出口政策或者服务条款变了。
我很讨厌这种不确定性,因为它会让工程团队陷入一种很蠢的状态:前端已经发版,后端也写好了,只有法务和平台策略像一堵看不见的墙。你没法靠重试解决,最多只能把错误码打得更漂亮一点。
How to apply it:如果你在做模型接入,我建议把“地区/主体/合规”当成配置项,而不是文档附录。最少要有这些检查:
- 账号主体是否允许调用该模型。
- 部署区域是否在允许范围内。
- 是否需要单独的审批、白名单或合同条款。
- 一旦限制变化,是否能自动降级到备用模型。
这里别偷懒。很多事故不是模型坏了,而是你根本没给限制变化留后路。
能力收紧后,最先坏掉的是默认假设
“核心能力被大幅收紧”这几个字听起来很抽象,但工程上它一点都不抽象。你可以把它翻译成:原来默认可用的能力,现在要么变成条件可用,要么直接不可用。最危险的地方就在于“默认”两个字。
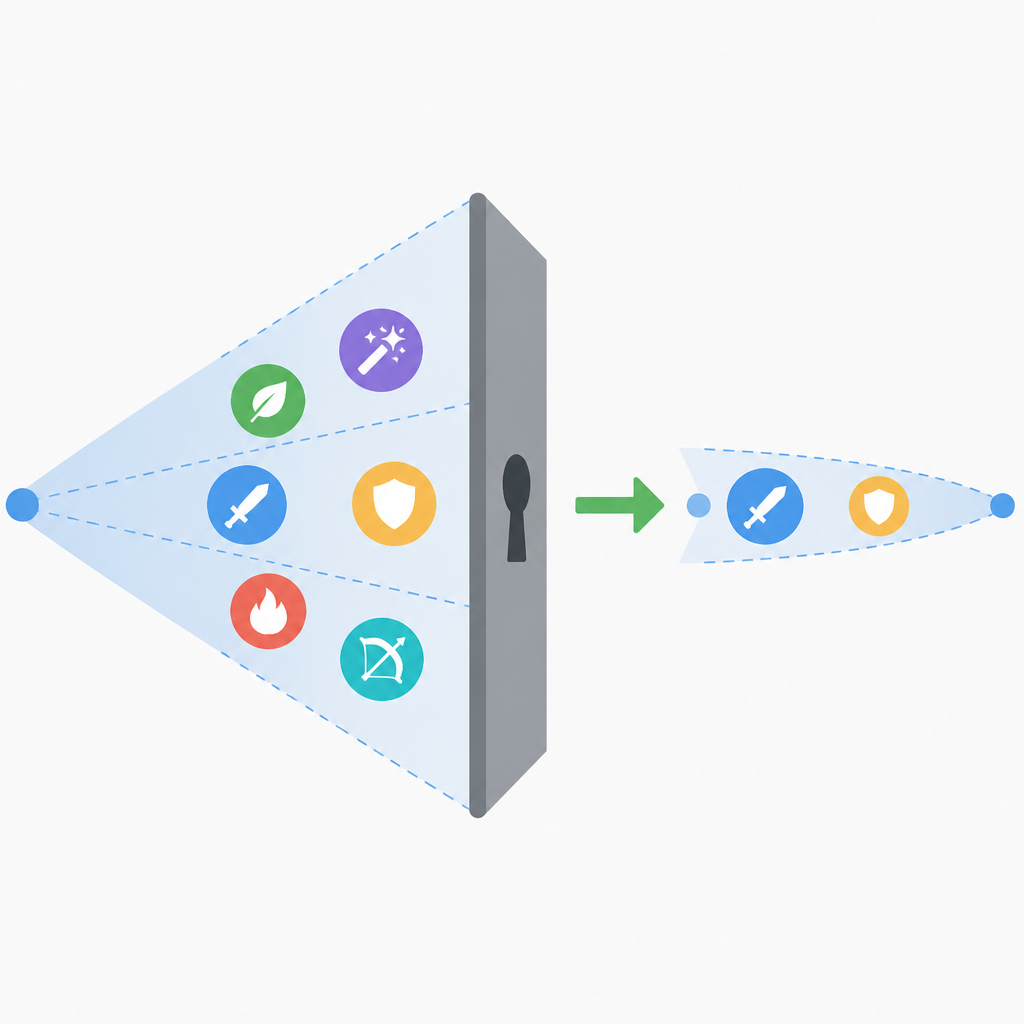
What this actually means is:你原先写进产品逻辑里的那些隐含假设,开始失效了。比如你默认它能稳定输出长答案,默认它能处理复杂指令,默认它能接工具,默认它能在某个上下文长度下不崩。只要其中一条变了,你的链路就会抖。
我见过最典型的场景,是一个团队把模型当作“万能中间层”,前面接用户问题,后面接数据库查询和摘要生成。模型一旦变得更保守,原本会主动补全的步骤不做了,整条链路就像被人抽走了中间那块板子。不是完全坏,但就是处处别扭。
How to apply it:把模型能力拆成清单,不要只写“支持/不支持”。我通常会分成四层:
- 输入层:文本、图片、文件、音频是否还可用。
- 推理层:上下文长度、复杂指令、链式任务是否稳定。
- 执行层:工具调用、函数调用、外部检索是否受限。
- 输出层:长度、格式、拒答阈值、敏感内容策略是否变化。
这份清单看起来啰嗦,但它能救你。因为一旦供应商改策略,你就能快速定位到底是“模型挂了”还是“某一层被收紧了”。
公告不是结论,X 上确认只是开始
原文提到 Anthropic 随后在 X 平台上确认了相关信息。这里我不想把社交平台确认说得太神,但它确实说明了一件事:很多时候,真正影响开发者决策的,不是正式公告写了什么,而是平台方在公开渠道怎么补充说明。
What this actually means is:你得同时看正式渠道和公开沟通渠道。正式公告负责立规矩,X、博客、帮助中心更新负责解释边界。只看其中一个,你很容易误判。
我以前就因为只看产品公告吃过亏。公告写得很漂亮,结果帮助中心的 FAQ 里悄悄加了一条“某些区域暂不支持”。那条小字才是真正会让你半夜报警的东西。后来我学乖了,碰到模型政策变化,第一时间不是转发,而是去翻文档、状态页、FAQ、开发者论坛和官方社媒。
How to apply it:建立一个最小的信息核对流程,别靠人肉刷消息:
- 公告页:看主结论。
- 状态页:看是否真的恢复。
- 帮助中心:看限制细则。
- 开发者社区或社媒:看官方补充说明。
如果你们团队里有人负责平台接入,让他把这些来源做成一个固定检查表。别每次都靠“谁刷到了算谁的”。
真正该改的,是你的降级策略
每次模型能力变化,我最先问的不是“还能不能用”,而是“不能用的时候怎么办”。因为现实里,模型波动比你想象得频繁。今天是限制风波,明天可能是区域下线,后天也许只是某个能力临时退回。
What this actually means is:你的产品不能把单一模型当唯一支点。要么能切换,要么能降级,要么能在能力缩水时自动缩短任务链路。
我非常建议你把降级策略写成明确规则,而不是一句“异常时返回默认结果”。那种写法基本等于没写。真正能救命的是这种规则:如果工具调用失败,就改成纯文本回答;如果长上下文不可用,就缩短输入并提示用户;如果高风险能力被关,就直接切到保守模式。
How to apply it:
- 给每个核心能力指定一个备用路径。
- 给每个路径设定触发条件。
- 给前端和客服准备统一话术,别让用户自己猜。
我知道这听起来像额外工作,但其实这才是你少加班的办法。能力变化不可控,降级策略至少能让你可控一点。
别只盯着模型,盯住你的测试基线
这类事件最容易暴露一个老毛病:团队把测试写成一次性的。模型一变,大家就开始凭感觉讨论“好像没那么差”“应该还能接受”。我对这种讨论已经很烦了,因为它没有基线,全靠嗓门。
What this actually means is:你得保留一套可重复的回归集。模型恢复、限制解除、权限变化、策略收紧,这些都应该触发同一套测试,而不是每次临时拼一批 prompt。
我建议你至少保留三类样本:
- 正常样本:看基础能力有没有退化。
- 边界样本:看拒答、格式、长度和工具调用是否变化。
- 失败样本:看降级路径是否真的能接住。
如果你做的是内部平台,最好把这些样本直接挂到 CI 或 nightly job 里。别等到业务同学来问“为什么今天摘要短了一半”,你才开始翻日志。那太晚了。
顺手说一句,Anthropic 的官方开发者文档和状态页也值得长期盯着,至少可以减少你被动接消息的次数。相关入口可以看 Anthropic Docs、Anthropic Status,以及他们的 X 账号。如果你还在做模型选型,最好把这些来源加入日常监控,而不是等出事才去翻。
把这件事翻译成团队能执行的规则
说到底,Fable 5 这次“解禁但收紧”的故事,真正有价值的地方不在新闻性,而在它提醒我:模型供应方的状态变化,必须被你翻译成工程规则。不能停留在“知道了”。
What this actually means is:你要把外部变化变成内部动作。动作越具体,团队越不容易乱。
我自己的做法很简单,基本就三步:先确认变化是不是影响你当前链路,再更新基线和降级策略,最后把变化写进变更记录和发布说明。听上去朴素,但很管用。大多数事故不是因为没人知道,而是因为知道了却没落到执行层。
如果你现在就在做模型接入,我建议你别把这类消息当“资讯”,而是当“配置变更事件”来处理。这样你会少很多情绪,多很多动作。工程就是这样,最怕的不是限制,最怕的是限制来了,你还在用旧脑子。
你可以直接复用的上线检查模板
下面这份模板,我是按“模型恢复上线但能力可能变化”的场景整理的。你可以直接复制到团队文档、变更单或者发布 checklist 里。
# 模型恢复上线检查模板(适用于能力变化、权限收紧、区域调整场景)
## 1. 变化确认
- [ ] 已确认模型/服务状态恢复
- [ ] 已确认恢复范围:地区 / 账号主体 / 版本 / 能力
- [ ] 已确认是否存在新的限制条款
- [ ] 已确认官方公告、文档、状态页信息一致
## 2. 能力核对
- [ ] 输入类型是否变化:文本 / 图片 / 文件 / 音频
- [ ] 上下文长度是否变化
- [ ] 工具调用 / 函数调用是否变化
- [ ] 输出长度、格式、拒答策略是否变化
- [ ] 是否仍适用于当前业务场景
## 3. 回归测试
- [ ] 正常样本通过
- [ ] 边界样本通过
- [ ] 失败样本能正确触发降级
- [ ] 关键指标与上一次基线对比完成
- [ ] 结果已记录到变更日志
## 4. 降级策略
- [ ] 有备用模型
- [ ] 有纯文本降级路径
- [ ] 有缩短上下文的策略
- [ ] 有统一用户提示文案
- [ ] 有客服/运营同步话术
## 5. 发布与监控
- [ ] 已更新发布说明
- [ ] 已通知相关团队
- [ ] 已设置监控告警
- [ ] 已设置异常回滚条件
- [ ] 已安排 24 小时内复查
## 6. 复盘记录
- [ ] 记录变化发生时间
- [ ] 记录受影响能力
- [ ] 记录修复或替代方案
- [ ] 记录后续跟进人
- [ ] 记录是否需要调整供应商策略
这份模板不是为了显得正式,它的作用很现实:把“感觉模型变了”变成“我们具体改了什么”。你只要能把这件事写清楚,后面很多争论都会少一半。
最后补一句,这篇内容是我基于你给的知乎专栏信息做的拆解和工程化整理,不是原文逐字复述。原始来源是 https://zhuanlan.zhihu.com/p/2055722791937356404,我这里主要做的是把它翻成开发者能直接拿去用的检查清单和模板。
// Related Articles
- [IND]
Equity tokenization platform features that matter most
- [IND]
OpenAI’s 5% fund pitch turns equity into policy
- [IND]
California’s Claude deal puts AI inside state offices
- [IND]
Meta一句话引爆AI硬件,华尔街仍看多算力
- [IND]
Cloudflare sets September 15, 2026 crawl defaults
- [IND]
Cloudflare’s new crawler rules shift power to publishers