Fine-Tuning Methods: SFT, LoRA, DPO, RLHF, GRPO
A practical guide to choosing the right LLM fine-tuning method from SFT to GRPO.

This guide shows developers how to choose the right LLM fine-tuning method.
This guide is for ML engineers, applied AI developers, and technical leads who need to turn a base LLM into a model that matches a product’s data, tone, or reasoning goals. By the end, you will know what SFT, LoRA, QLoRA, DPO, RLHF, GRPO, and full fine-tuning optimize, what data each one needs, and which path fits your hardware and team setup.
You will also leave with a simple decision path: start from the labels you have, match them to the training objective, and pick the lightest method that can reach your target quality.
Before you start
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
- Hugging Face account and access to the Transformers docs and PEFT GitHub repo.
- Python 3.10+
- PyTorch 2.2+
- CUDA-capable GPU with 16 GB VRAM minimum for QLoRA, 24 GB+ for easier LoRA or SFT runs.
- At least one dataset in a usable format: input-output pairs, preference triples, or rule-scored completions.
- Optional but useful: Weights & Biases account for training logs.
Step 1: Classify your training data
Your first job is to identify the shape of the labels you already have, because the data format determines the method. If each prompt has one correct answer, you are in supervised fine-tuning territory. If you have chosen and rejected responses, you are in preference training territory. If you can score outputs automatically, you can use reinforcement-style optimization with a verifiable reward.
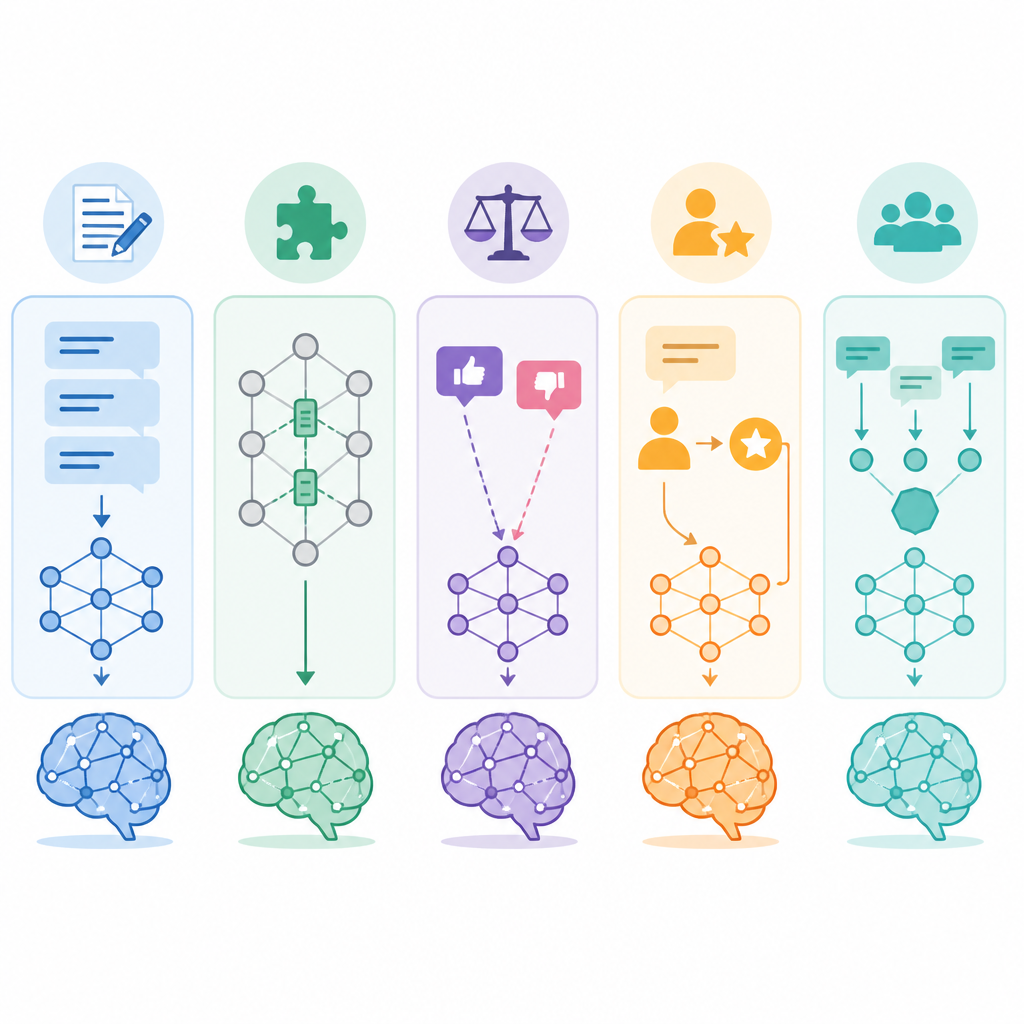
Map your dataset into one of these three buckets before you write any training code:
input-output pairs -> SFT / LoRA / QLoRA
(prompt, chosen, rejected) -> DPO / RLHF
prompt + scoring rule -> GRPO-style RLYou should see a clear one-line label for each row type. If you cannot describe the row in one sentence, the dataset is not ready yet.
Step 2: Train supervised outputs with SFT
Use supervised fine-tuning when you want the model to imitate a known good answer. This is the default choice for product teams that need stable tone, formatting, taxonomy labels, or domain phrasing. Instruction tuning is a common SFT variant where each example looks like a short chat turn with a user message and an assistant reply.
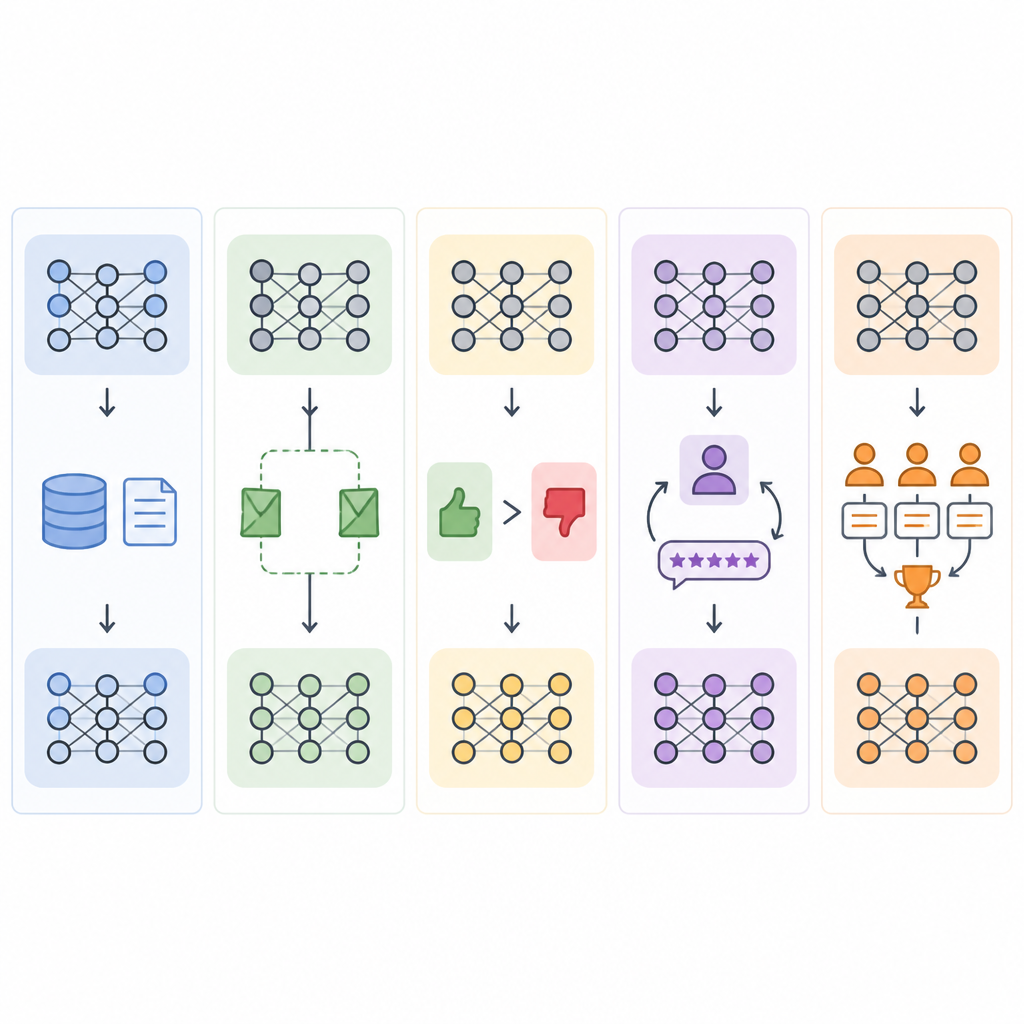
In practice, SFT updates the model on labeled prompt-answer pairs so it learns to produce similar answers on new prompts. If you want to keep compute lower, pair SFT with parameter-efficient fine-tuning so you only train adapters instead of the full model.
You should see training loss fall and sample outputs begin to match your target style more closely. A quick sanity check is to prompt the model with examples from your validation set and confirm the responses follow the same structure and tone.
Step 3: Add adapters with LoRA or QLoRA
Choose LoRA when you want to fine-tune a model without updating every weight. LoRA freezes the base model and trains small low-rank matrices that steer the layer behavior. Choose QLoRA when the base model does not fit comfortably in GPU memory, because QLoRA stores the frozen weights in 4-bit form and keeps the adapters trainable in higher precision.
Use this rule of thumb: LoRA fits when you have enough VRAM for the base model in reduced precision, while QLoRA fits when you need a bigger model on a smaller GPU. For a 7B model, QLoRA is often the practical path on a single 16 GB card.
You should see only adapter weights changing during training, while the base checkpoint stays frozen. If you inspect the saved artifacts, you should find a small adapter file rather than a full model rewrite.
Step 4: Optimize preferences with DPO or RLHF
Use preference training when there is no single correct answer, but you can tell which answer is better. DPO is the lighter option if you already have triples in the form prompt, chosen, and rejected. It runs as a single offline training loop and does not require a learned reward model.
Use RLHF when you need a full alignment pipeline and can afford the extra cost. RLHF trains a reward model from human preferences, then uses reinforcement learning to push the policy toward preferred outputs. It is more expensive, but it is a standard path when human judgment matters and the training budget is larger.
You should see the model prefer the chosen response over the rejected one on held-out prompts. A quick check is to compare paired outputs and confirm the model’s preferred style becomes more consistent after training.
Step 5: Use GRPO for rule-scored reasoning
Choose GRPO when you can score outputs with a rule instead of human labels. This is a strong fit for math, code, and exact-match tasks, because the reward can come from a verifier, a test suite, or a formal scoring function. The model samples multiple answers, scores them, and learns to favor completions that beat the batch average.
GRPO is useful when you want alignment from measurable correctness rather than preference labels. DeepSeek-R1 is a well-known example of a model trained with this style of optimization.
You should see better performance on tasks where the score is objective, such as passing tests or producing a correct final answer. If your scoring rule is noisy or vague, GRPO will be harder to stabilize.
Step 6: Reserve full fine-tuning for full control
Use full fine-tuning only when you need every parameter to move. This gives the most flexibility, but it also consumes the most VRAM, takes longer, and requires stronger infrastructure for training, versioning, and serving full checkpoints. It is usually a fit for teams building domain-specific foundation models rather than product teams customizing a single assistant.
Full fine-tuning is the right choice when adapters are not enough to reshape the model’s representations or when you need to own the entire checkpoint lifecycle. For most applications, it is the last option rather than the first.
You should see the largest possible change in model behavior, but also the largest cost in compute and operational complexity. If your team cannot comfortably manage full checkpoints, step back to LoRA or QLoRA.
| Metric | Before/Baseline | After/Result |
|---|---|---|
| Memory for a 7B base model | ~14 GB in bf16 | ~4 GB in 4-bit NF4 with QLoRA |
| VRAM requirement | 24 GB+ setup for easier full-base runs | 16 GB hardware can be enough for QLoRA |
| Trainable parameters | Billions in full fine-tuning | Tens of millions with LoRA adapters on a 7B model |
Common mistakes
- Using SFT for preference data. Fix: if your rows are prompt, chosen, rejected, switch to DPO or RLHF.
- Trying full fine-tuning first. Fix: start with LoRA or QLoRA unless you truly need every weight to move.
- Using GRPO without a solid score. Fix: only use it when the reward is objective, such as tests passing or exact match.
What’s next
After you pick a method, the next step is to design the dataset, split train and validation sets, and define evaluation metrics that match the objective you chose. From there, you can compare adapter-based training, preference optimization, and full checkpoint training on the same task and measure which one gives the best quality-to-cost tradeoff.
// Related Articles
- [AGENT]
Mistral Vibe proves the CLI agent still matters
- [AGENT]
Kimi Code CLI setup, pricing, and workflow guide
- [AGENT]
Windows is becoming an agent runtime, not a human desktop
- [AGENT]
5 Grok updates that change how I code
- [AGENT]
Codex brings ChatGPT into work and code tasks
- [AGENT]
Claude Code 动态工作流:AI 自写 Harness