Gaze Heads: Steering VLMs by Redirecting Attention
A small set of attention heads can steer a VLM to describe a chosen image region without retraining.

A small set of attention heads can steer a VLM to describe a chosen image region without retraining.
- Research org: Unspecified in arXiv abstract
- Core data: 83.1% accuracy
- Breakthrough: Identify “gaze heads” whose attention follows the described image region
Vision-language models can sound fluent while still being hard to reason about internally. This paper looks for a concrete mechanism inside the model, and finds one that behaves like a controllable pointer: a small subset of attention heads tracks the region the model is talking about, and nudging that attention can change what the model describes.
For engineers, that matters because it turns a fuzzy multimodal behavior into something you can inspect and steer. Instead of retraining or prompting harder, the authors show an inference-time intervention that redirects the model’s description to a chosen part of the image.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
When a vision-language model describes an image, it is not obvious how the model decides which visual region to talk about next. The output is sequential, but the image is spatial. That mismatch makes the internal process difficult to debug, especially when the model describes the wrong object, drifts to a different region, or ignores user intent.

This paper is trying to answer a practical mechanistic question: is there a specific internal component that tracks “where the model is looking” while it narrates an image? If so, that component could become a handle for steering model behavior in a predictable way.
The authors study this using comic strips as a controlled testbed. Comics are useful here because narrative order is laid out spatially, which makes it easier to tell whether the model is following the intended panel or jumping elsewhere.
How the method works in plain English
The core idea is simple: search for attention heads in the language-model backbone whose attention correlates with the image region currently being described. The authors call these heads gaze heads.
They identify them with a simple correlation score computed from a few forward passes. In other words, they do not need a large training run or a complicated probe. They look for heads whose attention pattern moves in sync with the region the model is narrating.
Once they find those heads, they test whether those heads are just observers or whether they actually matter for generation. The crucial intervention is to redirect the attention of the gaze heads toward a chosen region. If the mechanism is real, the model should start describing that region instead of the one it would normally pick.
The paper also tests what happens if the intervention is applied too broadly. Redirecting a small targeted set is useful; intervening on all heads is not. That contrast matters because it suggests the effect is not just generic noise in attention, but a specific circuit-level handle.
What the paper actually shows
The strongest result is that a single attention-mask intervention on the top-100 gaze heads, which is fewer than 9% of all heads, steers the model’s answer to any chosen comic panel with 83.1% accuracy.
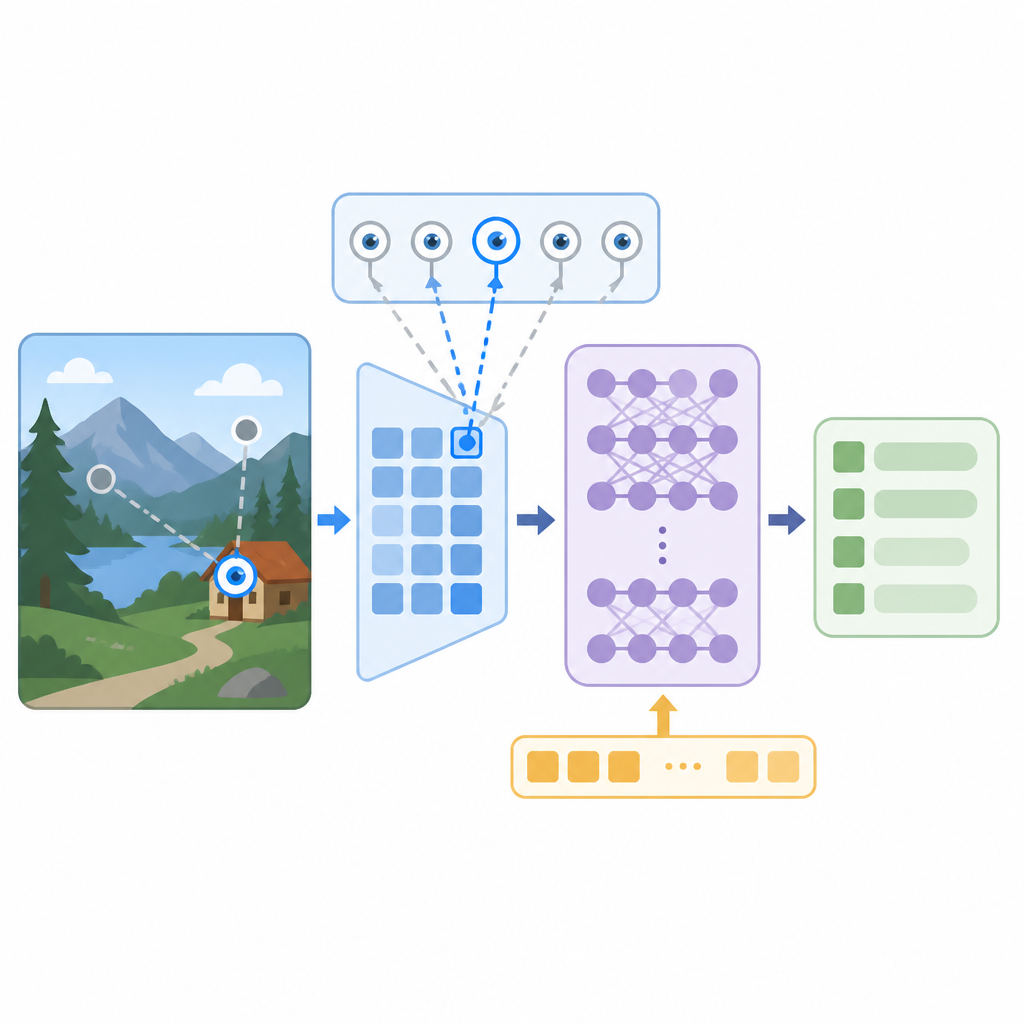
That is a concrete, operational result. It means the model’s description can be redirected at inference time by editing attention in a relatively small part of the network. The same intervention on random heads fails to redirect the answer, and intervening on all heads destroys generation. So the effect is selective, not just a brute-force rewrite of attention everywhere.
The authors also show continuous control. If the gaze target is switched in the middle of generation, the model wraps up its current panel description and moves to the new one within a few tokens. That suggests the mechanism is not only useful for one-shot steering, but can also support dynamic control while the model is already speaking.
Beyond comics, the same intervention redirects answers to chosen regions in natural COCO images. That broadens the claim from a neat comic-strip demo to a more general multimodal setting, at least within the paper’s tested examples.
The mechanism also appears across model scales from 2B to 32B parameters and across other VLM architectures. However, the paper notes an important limitation: some frozen-encoder families do not show a comparable head set. So this is not presented as a universal property of every vision-language model.
Why developers should care
If you build with VLMs, this paper points to a new kind of control surface. Instead of only steering with prompts or fine-tuning, you may be able to steer behavior by editing a small internal attention subset at inference time.
That could be useful for debugging, alignment experiments, region-specific captioning, or interactive multimodal tools where the user wants the model to focus on a particular part of an image. It also gives mechanistic interpretability teams a more grounded target: not just “the model attends somewhere,” but “these heads appear to track what is being described.”
There is also a systems angle. The intervention is described as a simple attention-mask edit, which makes it easier to imagine integrating into an inference stack than a retraining pipeline. The paper does not claim this is production-ready, but it does show that targeted internal edits can act as practical levers for multimodal behavior.
Limits and open questions
The abstract gives a strong qualitative story, but not a full benchmark suite. It reports the 83.1% comic-panel steering result, but it does not provide broader task metrics, latency numbers, or robustness analysis beyond the settings described in the summary.
The method also relies on finding the right heads first. The paper says the gaze heads can be found with a simple correlation score from a few forward passes, but that still assumes the model exposes a discoverable pattern. If a model family does not develop a comparable set of heads, the intervention may not transfer.
Another open question is how stable this control is under different prompts, image styles, or longer conversations. The abstract shows switching targets mid-generation and extending the method to COCO images, but it does not claim full generality across all multimodal workloads.
Still, the main takeaway is clear: some VLMs appear to use a small, identifiable attention circuit to keep narration aligned with image regions, and that circuit can be redirected without retraining. For anyone building or analyzing multimodal systems, that is a useful new handle.
Bottom line
This paper turns a mysterious internal behavior into something measurable and steerable. If the model is describing the wrong part of an image, the right attention heads may be enough to push it back on track.
- Small targeted attention edits can redirect multimodal descriptions.
- The effect is strongest on a discoverable subset of “gaze heads,” not all heads.
- The method works across some model sizes and architectures, but not all frozen-encoder families.
// Related Articles
- [RSCH]
Build a Small Language Model with DeepMind
- [RSCH]
PAC-MAN makes humanoid dodgeball safer
- [RSCH]
ReToken uses one learned token to fetch visual context
- [RSCH]
ML helps trace Seiberg dualities
- [RSCH]
Fruitfly-Inspired Regression Without Heavy Models
- [RSCH]
Mental World Modeling: Simulating minds, not just scenes