Sequential fine-tuning improves essay scoring
Sequential fine-tuning of LLaMA better captures essay task dependencies than independent or shuffled training.

Sequential fine-tuning of LLaMA better captures essay task dependencies than independent or shuffled training.
- Research org: University of California, Irvine
- Core data: 65% F1 on evidence
- Breakthrough: Progressive fine-tuning on lead, position, claim, evidence, conclusion
Automated essay scoring sounds simple until you try to score writing the way humans actually read it: as a chain of dependent parts, not isolated labels. This paper argues that the order of training matters because the essay sections themselves are connected, and that connection should be reflected in how the model learns.
For engineers building educational NLP systems, the practical question is not just whether a model can classify essay components, but whether it can do so coherently across the whole response. The paper’s answer is that a smaller, task-aware model can be a strong choice when training is structured around discourse flow instead of random multitask mixing.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Automated Essay Scoring (AES) systems have a recurring weakness: they often treat essay parts in isolation even though those parts depend on one another. The abstract gives the example of discourse elements such as lead, claim, evidence, and conclusion, which are not independent labels in practice. A weak introduction can affect how the rest of the essay is interpreted, and a scoring model that ignores that relationship can end up inconsistent.

The paper also frames generalization as a second problem. Fine-tuned models can overfit training data and lose accuracy on unseen essays, which matters a lot in education where prompts, student styles, and writing quality vary. That makes AES a good test case for curriculum design: if the training sequence is smarter, maybe the model learns a more stable representation of discourse structure.
This is why the authors focus on task-aware fine-tuning of LLaMA-3.1-8B rather than trying to solve everything with a bigger general-purpose model. They are testing a simple but important idea: if the scoring tasks are related, maybe the training order should be related too.
How the method works in plain English
The model setup uses LLaMA-3.1-8B with parameter-efficient LoRA and 4-bit quantization. In practical terms, that means the authors are not fully retraining a huge model from scratch; they are adapting it in a more lightweight way, which is the kind of approach developers care about when compute budgets matter.
The core experiment compares three training curricula. In the sequential setup, the model is fine-tuned progressively on lead, then position, then claim, then evidence, then conclusion. In the independent setup, each task gets its own model. In the randomized setup, the tasks are shuffled in a multi-task training order.
That distinction is the heart of the paper. The authors are not just asking whether fine-tuning helps; they are asking whether the sequence of fine-tuning helps the model learn discourse-aware representations. If the essay itself has structure, then the training pipeline should probably respect that structure too.
They also compare the fine-tuned models against a general-purpose LLaMA-70B baseline. That gives the paper a useful engineering angle: can a smaller adapted model compete with a much larger one when the task is narrow and the curriculum is aligned with the problem?
What the paper actually shows
The abstract reports results on the PERSUADE 2.0 corpus, but it does not provide full benchmark tables in the note we have here. It does, however, give several concrete outcome numbers. Sequential fine-tuning delivers the strongest overall results, including 65% F1 for evidence and 87% F1 for conclusion, with corresponding accuracies of 63% and 85%.
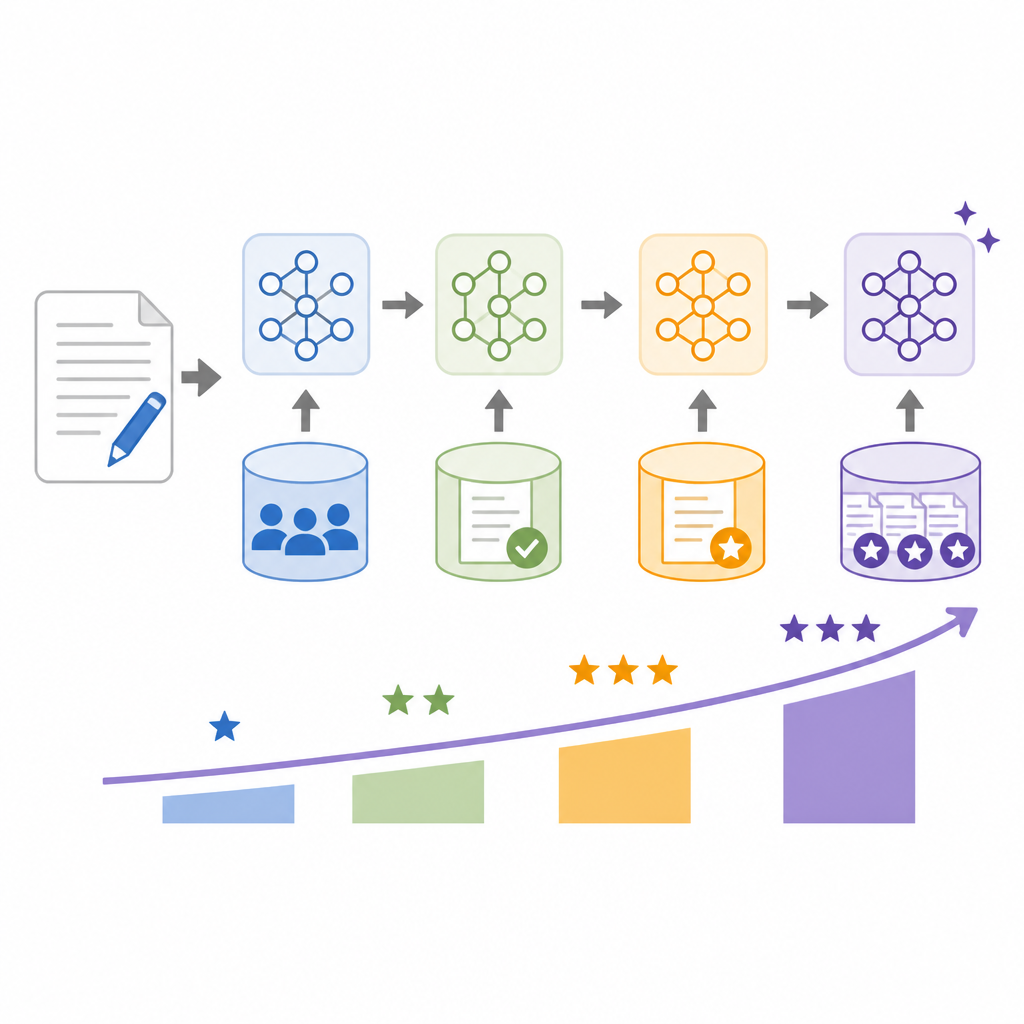
Those numbers matter because they point to a model that is learning more than surface-level cues. Evidence and conclusion are discourse-heavy tasks, and the stronger results suggest that the curriculum is helping the model carry information from earlier essay components into later ones.
The paper also says the sequential model surpasses the Independent training approach and outperforms a general-purpose LLaMA-70B baseline on conclusion, despite the baseline’s much larger capacity. That is the most practically interesting claim in the abstract: a smaller, task-optimized model can beat a far larger model on at least one key essay-scoring task.
Randomized training is not useless, but it is less stable. The abstract says it improves position scoring to 57% F1, yet it is less consistent elsewhere. So the message is not that multitask training is bad in general; it is that in this setting, task order and dependency structure seem to matter more than simple task mixing.
The paper’s own summary bullets reinforce that point. Fine-tuning is essential for task-specific adaptation, sequential curriculum learning yields the strongest overall performance, and task interdependence is critical for coherent evaluation. The authors also conclude that small, task-aware models can outperform larger, generalist models.
Why developers should care
If you are building scoring, ranking, or structured evaluation systems, this paper is a reminder that training strategy is part of model design, not just an optimization detail. When labels or subtasks depend on one another, curriculum order can become a meaningful lever for quality.
That has implications beyond essay scoring. Any pipeline that evaluates multi-part outputs — think rubric-based grading, checklist-style review, or structured content validation — may benefit from training that respects the order and dependency of the target structure. The paper does not prove that this transfers everywhere, but it gives a concrete example of why it might.
The compute angle is also important. By using LoRA and 4-bit quantization on an 8B model, the authors are pointing toward a more accessible path than relying on massive generalist LLMs. For teams that cannot afford to deploy or fine-tune very large models, task-specific adaptation may be the better engineering tradeoff.
Limitations and open questions
The abstract is strong on the main result but light on some details developers would want before reproducing it at scale. It does not include a full benchmark breakdown across all tasks in the note provided here, so the comparative picture is partial.
It also leaves open how sensitive the results are to dataset choice, prompt formatting, or the exact LoRA and quantization settings. The paper says templates and implementation details are released to support reproduction, but the abstract alone does not tell us how robust the findings are across other corpora or scoring rubrics.
Another open question is generality. The paper argues that curriculum design aligned with discourse structure improves AES, but that is still a specific domain with specific task dependencies. The broader lesson is promising, yet it still needs testing in other structured evaluation settings before you treat it as a universal recipe.
Even with those caveats, the engineering takeaway is clear: when the target problem has an internal sequence, the training sequence may matter too. This paper is a useful reminder that sometimes the best way to make a model coherent is to teach it in the same order that coherence appears in the data.
Bottom line
Sequential fine-tuning is the paper’s main contribution, and the abstract suggests it is not a minor tweak but a real performance lever. For developers working on AES or other structured NLP systems, the lesson is straightforward: if your labels depend on each other, train the model as if they do.
- Sequential curriculum learning beat independent and shuffled fine-tuning in this AES setup.
- A smaller LLaMA-3.1-8B model with LoRA and 4-bit quantization was competitive with LLaMA-70B on conclusion.
- The paper’s strongest signal is that task order can improve coherent, discourse-aware evaluation.
// Related Articles
- [RSCH]
Explainable RL for Air Traffic Control
- [RSCH]
Skill Self-Play lets LLMs co-evolve skills
- [RSCH]
SM4RT brings rigid motion into 4D reconstruction
- [RSCH]
Prompt engineering turns codegen into a repeatable workflow
- [RSCH]
CLEAR prompts turn AI search into usable answers
- [RSCH]
Prompt engineering in 2026: the cheat sheet