Turing-RL trains user simulators by fooling judges
Turing-RL trains user simulators to sound indistinguishable from real users instead of matching one fixed reply.

Turing-RL trains user simulators to sound indistinguishable from real users instead of matching one fixed reply.
- Research org: MIT CSAIL + collaborators
- Core data: No benchmark numbers in abstract
- Breakthrough: Reinforcement learning with a Turing-style LLM judge reward
Learning User Simulators with Turing Rewards looks at a problem that shows up anywhere you need realistic people in the loop: agent training, personalization evaluation, and social-science-style interaction studies. The paper argues that the usual way of training a user simulator—make the model match a single ground-truth response—may be the wrong target if the goal is realism.
Instead of asking, “Did the model reproduce this exact answer?”, the authors ask whether the model’s response is hard to distinguish from what the user might have said given the same history. That shift matters for engineers because interactive systems rarely face only one acceptable user reply. Real users are variable, contextual, and sometimes ambiguous, so a simulator that learns distributional realism may be more useful than one that chases a single reference.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Traditional user simulators are usually trained the same way many text generation models are trained: predict one target response as closely as possible. The abstract says prior approaches do this by maximizing log probability or by using a similarity reward. That works if you care about reproducing a reference, but it can be a poor fit for simulating people, where multiple replies could be plausible.
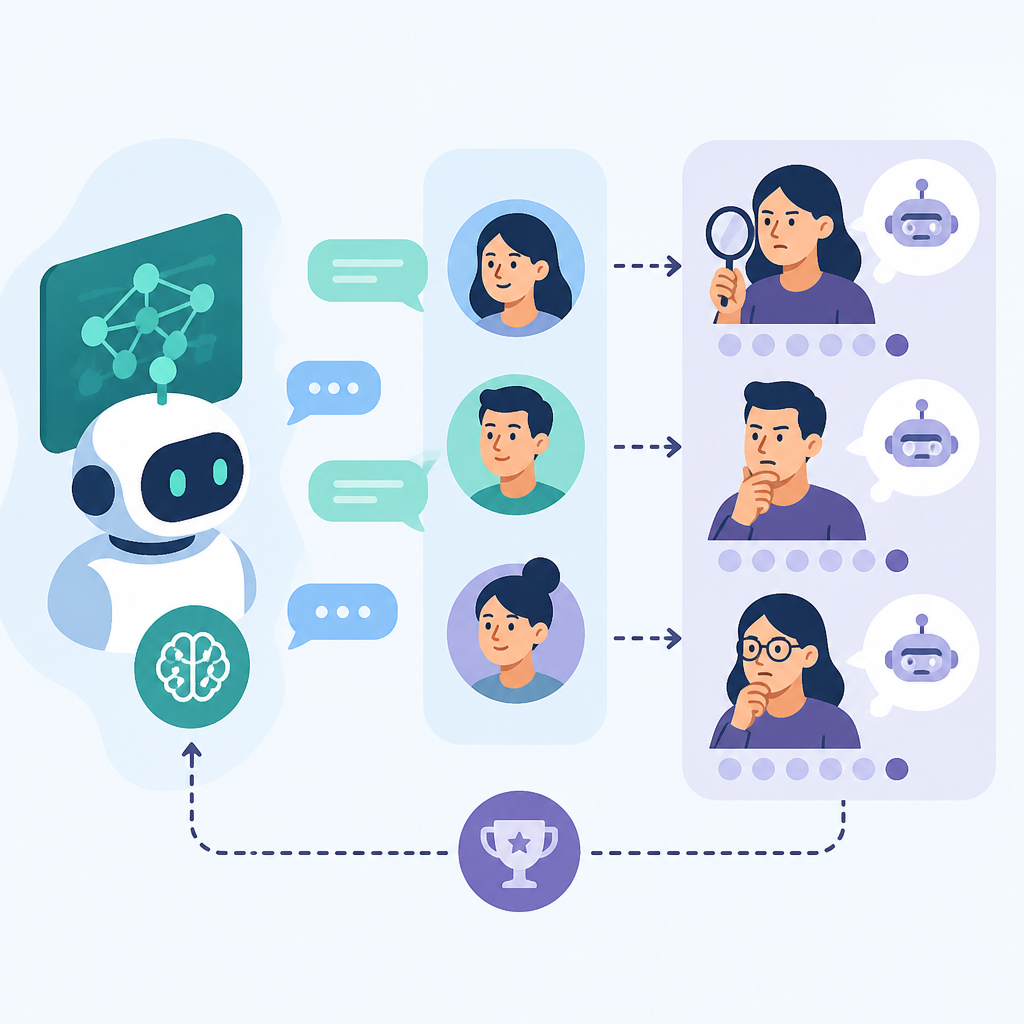
The paper’s core complaint is simple: response matching can reward being close to one annotated answer even when that answer is just one of many natural possibilities. In other words, a simulator can become good at imitation in the narrow sense while still being a weak stand-in for a real user in an interactive environment.
This is a practical issue for developers building assistants, recommendation flows, or conversational products. If your simulator is too reference-bound, it may overfit the dataset and miss the variability that matters when you test policies, personalize experiences, or stress-test dialogue strategies.
How Turing-RL works in plain English
The proposed method is called Turing-RL, and the name is a clue: it borrows the spirit of a Turing test. Rather than rewarding the simulator for matching a specific response, it uses a discriminative Turing reward. An LLM judge scores how indistinguishable a generated response is from a real user response, given the user’s history.
That judge-based reward is then used in reinforcement learning. The simulator LLM learns not to copy a canonical answer, but to produce a response that could plausibly have come from the user in that context. The abstract frames this as optimizing for indistinguishability rather than response matching.
In practical terms, that means the training objective is closer to “sound like a real person in this conversation” than “recreate this exact line.” For simulation tasks, that is a meaningful distinction. A model can be useful even if it does not hit the one reference answer, as long as it behaves like a believable user under the same conditions.
The paper does not describe the full implementation details in the abstract, so we should be careful not to overstate how the judge is prompted or how the reward is calibrated. What is clear is the high-level loop: generate a response, score its indistinguishability with an LLM judge, and use that score as reinforcement learning signal.
What the paper actually shows
The abstract reports evaluation across two domains: conversational chat and Reddit forum discussion. Across both, Turing-RL “consistently outperforms baseline methods” on both LLM evaluation metrics and human evaluation metrics. That is the strongest result available in the source.
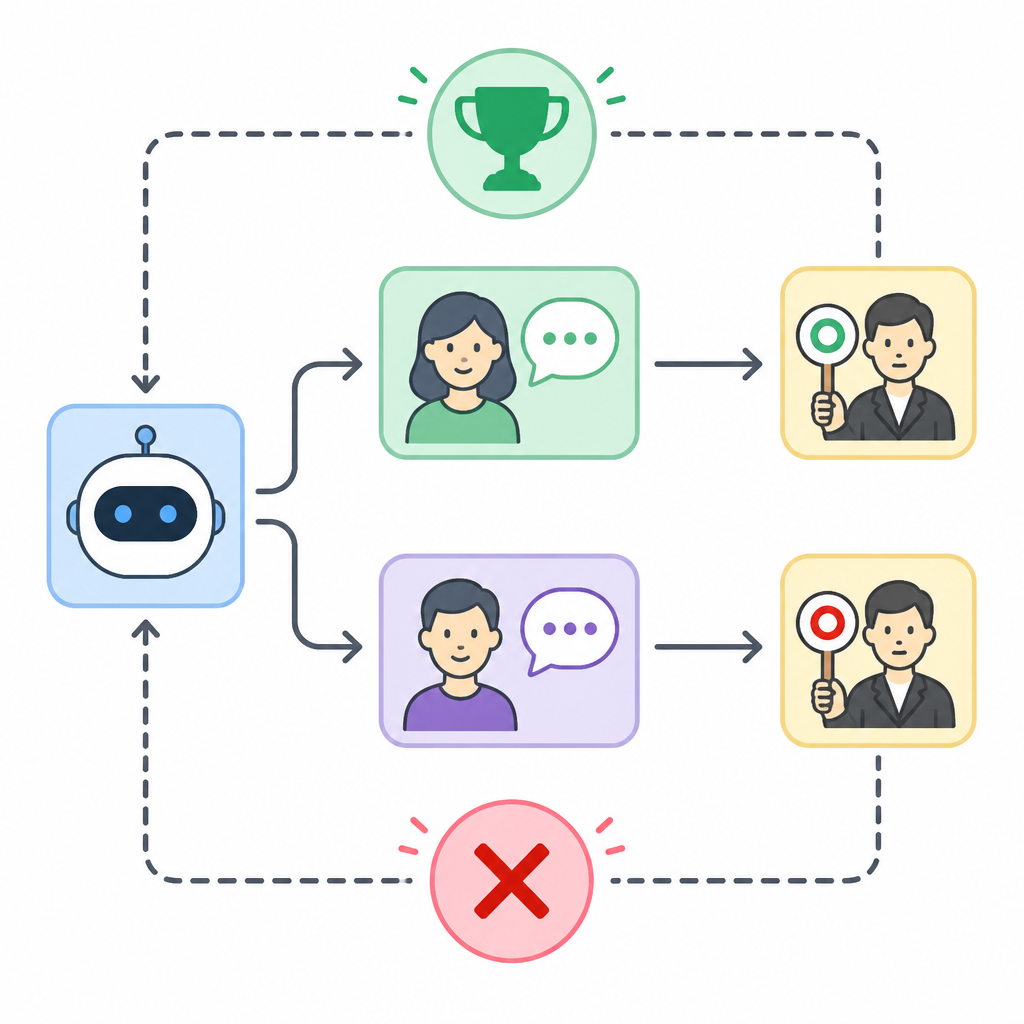
There are no benchmark names, no numeric scores, and no ablation table in the abstract, so this is not a paper you can read as a leaderboard story. Still, the direction of the result matters: the method wins in both automated and human judgment, and it does so across two different interaction settings rather than a single narrow dataset.
The result also supports the paper’s main thesis: if your goal is to simulate users, optimizing for indistinguishability can work better than optimizing for exact response matching. That is a useful signal for anyone who has been treating simulator training as a standard supervised learning problem.
What the abstract does not show is just as important. We do not know from the provided text how large the gains are, how sensitive the method is to judge quality, or whether the approach generalizes beyond chat and Reddit-style discussion. Those are the obvious questions to ask before treating Turing-RL as a drop-in simulator recipe.
Why developers should care
If you build agent assistants, you need ways to test behavior before you expose the system to real users. A believable user simulator can help with offline training, evaluation, and scenario generation. This paper suggests that the best simulator may not be the one that reproduces a reference response most faithfully, but the one that is hardest to tell apart from an actual user.
That matters for personalization too. When you are modeling user preferences or interaction patterns, the output space is often multi-modal. A simulator trained to match a single target can collapse that diversity. A Turing-style objective may preserve more realistic variation, which could make evaluations less brittle.
There is also a research workflow angle. Social science and human-computer interaction studies often need controlled but realistic synthetic participants. A method that explicitly optimizes for indistinguishability could be a better fit for generating those agents, as long as the judge and training setup are trustworthy.
Limitations and open questions
The biggest limitation in the source material is that the abstract gives no benchmark numbers. So while the paper claims consistent improvement, you cannot judge effect size from the abstract alone. That makes it hard to compare the method against other simulator-training approaches without reading the full paper.
Another open question is dependency on the LLM judge. If the judge is biased, inconsistent, or too easy to game, the learned simulator may optimize for the judge rather than for genuine realism. The abstract does not say how robust the reward is to judge choice or prompt design.
There is also a broader systems question: how well does a simulator trained to fool a judge transfer to downstream tasks that care about long-horizon behavior, not just one-turn plausibility? The abstract focuses on response indistinguishability, so it does not tell us whether the approach captures deeper user dynamics.
Even with those caveats, the paper’s main idea is straightforward and useful: for user simulation, matching one answer may be the wrong objective. If your product depends on realistic synthetic users, a Turing-style reward is worth paying attention to.
Bottom line
Turing-RL reframes user simulation as a realism problem, not a reference-matching problem. The method uses an LLM judge to reward responses that are indistinguishable from real users, and the abstract says it beats baselines in chat and Reddit settings on both automated and human evaluation.
- It targets user simulators for agents, personalization, and social-science-style interaction research.
- It replaces single-answer matching with a Turing-test-inspired reinforcement learning reward.
- It reports better performance than baseline methods, but the abstract provides no numeric benchmarks.
// Related Articles
- [RSCH]
LOCUS opens U.S. local law for legal AI
- [RSCH]
OmniAgent brings active perception to video understanding
- [RSCH]
ArXiv AI papers push agents, memory, and data
- [RSCH]
ReproRepo scales reproducibility audits with GitHub issues
- [RSCH]
Variable-Width Transformers cut wasted capacity
- [RSCH]
VERITAS lets robots verify and improve at runtime