Codex 日志寫爆 SSD 怎麼管
我拆開 Codex 日誌寫爆 SSD 的根因、風險和可直接套用的限流修復模板,給你一份能抄進 PR 的版本。

我把 Codex 寫爆 SSD 這件事拆成了可直接照抄的修復模板。
我最近一直在看這種「安全工具把自己先弄出安全事故」的戲碼,真有點煩。你一邊聽 OpenAI 講 GPT-5.5-Cyber 怎麼幫你補漏洞、怎麼守住生產環境,另一邊 Codex 卻在本地狂寫 SQLite 日誌,寫到能把消費級 SSD 直接熬死。這反差太刺眼了,像是有人一邊教你防火,一邊把打火機塞進你口袋裡。
更讓我不舒服的是,這類問題不是「模型答錯了」而已,而是基礎設施層面的失控。你以為自己只是開了個 AI 編程助手,結果它在背景默默高頻寫盤,機器很安靜,磁碟壽命卻在一點點掉。開發者最怕這種事:沒有報錯,沒有崩潰,只有硬體在悄悄流血。
我也看過類似場景。日誌系統預設開太猛,開發機風扇像起飛,最後排查半天,問題根本不是業務邏輯,而是「寫得太勤快」。AI 工具現在只是把這個老毛病放大了,速度更狠,後果更貴。
這篇拆解的觸發來源是這份知乎文章:https://zhuanlan.zhihu.com/p/2052695927035531367。原文把 OpenAI 的 GPT-5.5-Cyber、Codex Security、Patch the Planet,還有 Codex SQLite 日誌異常串在一起,我下面就照開發者能用的方式拆。
別被「修補地球」這句話帶跑偏
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
OpenAI 還發起了一個聽起來就很燃的計劃—— Patch the Planet(修補地球)。
這句聽起來像宣傳口號,但我讀下來只想說:它本質上是在講一個很現實的問題,開源世界的漏洞太多,維護者太少,AI 只是把「發現問題」這件事加速了。

原文裡有個數字我覺得很關鍵:被廣泛使用的開源專案中,94% 的專案,一年內 90% 以上的新增程式碼,靠的是不到 10 個開發者。這不是在煽情,它是在提醒你,安全修復不是「多發幾份報告」就能解決的。報告太多,維護者會先被噪音淹沒。
我以前在團隊裡也碰過類似情況。掃描器一開,告警像下雨,最後大家不是在修漏洞,而是在給漏洞做工單分流。AI 安全工具如果只會「發現」,不會「收斂」,那它就是把維護成本往別人身上甩。
所以 Patch the Planet 真正有價值的地方,不是名字多大,而是它強調了專業人工複核。研究員先去重、先驗證,再把乾淨的補丁送給維護者。這個思路很樸素,但很對。你不能把一車噪音倒給維護者,然後說自己在幫忙。
怎麼用到你自己的專案裡?我建議你把「AI 安全掃描」分成三層:第一層只負責發現;第二層負責聚類、去重、排序;第三層才進入人工確認和補丁生成。別讓自動化直接越過第二層,不然你會得到一個更快的垃圾製造機。
- 先定義「可行動」漏洞,而不是所有命中都算數。
- 給每條告警加去重鍵:檔案、函式、呼叫鏈、版本號。
- 把人工確認作為發布門禁,而不是事後補課。
GPT-5.5-Cyber 強在哪,不在「更會聊天」
原文給了幾個基準:CyberGym 85.6%、ExploitGym 39.5%、SEC-bench Pro 69.8%。這些數字的意思不是「它更聰明」,而是它更擅長做防禦任務裡的那套髒活累活:找漏洞、驗證風險、生成補丁、給人工審查證據。
我更願意把它理解成一個專用安全工程師,而不是一個通用大模型。普通模型擅長給你解釋概念,安全模型要做的是把攻擊面一層層剝開。這個差別很大。前者像顧問,後者像值班工程師。
原文還對比了普通版 GPT-5.5、Claude Opus 4.7 和 Cyber 版。這裡我不想把重點放在「誰贏了誰」,因為那很容易變成口水戰。對開發者來說,真正有用的是:當模型開始進入高風險工作流時,評估指標必須貼近實際任務,而不是只看對話體驗。
我見過不少團隊把「模型表現好」理解成「上線沒問題」,結果一接到真實任務,模型開始穩定輸出看起來很合理、實際很危險的建議。安全場景尤其這樣。你不能只問它「能不能說」,你要問它「能不能在約束下做對事」。
怎麼落地?如果你在做內部安全助手,別直接讓它碰生產系統。先把它放進只讀環境,給它有限的程式碼快照、有限的執行權限、明確的稽核日誌。再把輸出限定成三種格式:風險說明、證據鏈、候選補丁。別讓它自由發揮寫長篇建議,那種輸出最容易把人帶溝裡。
- 把任務拆成「識別、驗證、修復建議」三段。
- 只給只讀上下文,不給任意執行權限。
- 所有建議必須附證據鏈,不能只給結論。
Codex Security 不是插件,它是工作流入口
原文說 Codex Security 插件把漏洞掃描、威脅建模、攻擊路徑追蹤、補丁生成直接焊進了 Codex 工作流。這描述挺準,我讀的時候想到的不是「插件」,而是新的入口層:它試圖把安全能力塞進你日常寫程式的路徑裡。
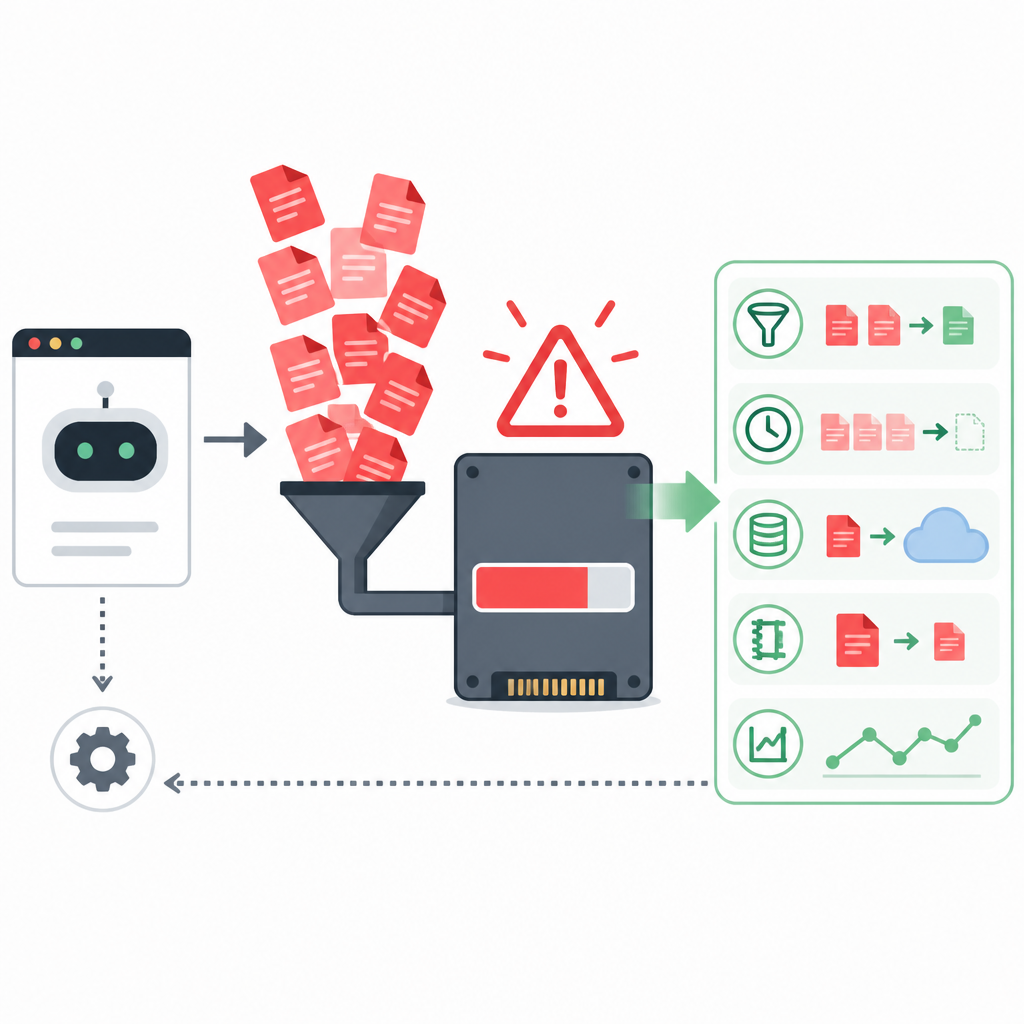
這件事的價值在於前移。以前很多安全檢查是「寫完再掃」,現在它想變成「邊寫邊看」。這當然更高效,但前提是工具本身得穩定,不然你會在編碼時多背一層故障風險。
原文提到,自今年 3 月研究預覽上線以來,Codex Security 已經掃描了超過 3000 萬次提交,覆蓋 3 萬多個程式碼倉庫,人工複核確認修復的發現超過 7 萬個,自動判定修復的超過 50 萬個。這個規模說明什麼?說明 OpenAI 不是在做一個玩具功能,它在試圖把安全掃描做成高頻基礎設施。
我對這種規模化工具一向有個偏見:只要它開始大規模寫日誌、快取狀態、追蹤上下文,就一定要盯住資源邊界。因為一旦你把「安全」做成常駐服務,資源消耗會跟著放大。安全工具最怕的不是慢,是悄悄把別的系統拖垮。
怎麼用?如果你要把類似 Codex 的安全插件接進團隊流程,我建議你先設三道閘:限制掃描頻率、限制本地持久化、限制長任務執行時間。尤其是本地持久化,別預設讓它把所有中間狀態都落盤。很多「穩定性問題」其實都出在這裡。
還有個很實用的習慣:把插件的日誌目錄單獨放到一個可監控分區裡,給它設磁碟配額。這樣一旦它開始發瘋,你至少能看到它在燒什麼,而不是等 SSD 壽命被磨掉一半才發現。
真正的 bug 不在模型,在寫盤策略
這部分是我最想吐槽的。原文裡那個問題很具體:Codex 在流式傳輸和長時間運行時,會以極高頻率往本地 ~/.codex/logs_2.sqlite 寫 TRACE 日誌,峰值能到 16MB/s,實測有人算出一年可寫入 640TB。這個量級已經不是「日誌多一點」了,這是在拿 SSD 當耗材。
最離譜的是,它還很安靜。檔案看起來不大,因為它在反覆寫入、刪除、清理,肉眼看不出什麼異常,但快閃記憶體晶片已經在吃滿負荷。開發者最容易被這種假象騙過去:目錄大小沒漲,不代表寫入量沒漲。
原文提到,有 GitHub 使用者實測開機運行 21 天,主 SSD 被寫入約 37TB 資料。這個數字已經足夠讓人警覺了。更關鍵的是,相關 issue 從 4 月就有人提,後面一路有人補刀,到 6 月 14 日又把問題頂上來。也就是說,這不是一次偶發事故,而是一個被社群反覆指出、但遲遲沒徹底解決的資源管理問題。
我在專案裡也見過類似「預設日誌等級太高」的坑。開發階段大家嫌日誌少,生產階段大家嫌日誌多。最後沒人去調,因為「先這樣跑著」。結果一拖就是幾個月,直到磁碟告急、I/O 抖動、機器變卡,才開始認真看。
怎麼處理這種問題?別只改日誌等級,得把寫盤策略一起改掉。要麼做取樣,要麼做批次刷盤,要麼做記憶體環形緩衝。最差也要給 TRACE 級別加速率限制。日誌不是越細越好,日誌的成本也得算進去。
- 給 TRACE 日誌加每秒寫入上限。
- 把高頻日誌改成批次落盤。
- 為本地 SQLite 設定配額和輪轉策略。
SQLite 沒錯,錯的是你把它當無限桶
我不想把鍋甩給 SQLite。SQLite 本身沒問題,問題是你拿它做高頻日誌存儲,還預設允許持續寫入、清理、再寫入。資料庫是拿來管理資料的,不是拿來當無限吞吐的垃圾桶。
原文裡最讓我警覺的一點,是「寫入再刪除、寫入再刪除」的模式。很多人只看檔案大小,不看底層寫放大。SSD 不是機械硬碟,寫入壽命是實打實會被消耗的。你每次覺得「反正只是日誌」,硬碟都在替你記帳。
我建議你把這個問題翻譯成工程語言:這是一個「背景寫放大失控」的案例。它和模型能力沒直接關係,和資源治理關係很大。只要你的工具會長時間運行、會流式輸出、會記錄上下文,就有可能踩到這個坑。
怎麼防?最簡單的辦法是把日誌分層。熱日誌放記憶體,冷日誌批次落盤,稽核日誌單獨存儲。然後再給每層設定不同保留期。別把所有東西都塞進一個 SQLite 檔案裡,最後再指望它自己長出節制。
如果你是做平台工程的,我還建議加一個「日誌寫入預算」指標。這個指標不花俏,但很管用。比如每個 agent 每小時最多寫多少 MB,超過就降級到摘要日誌。你會發現,這種硬約束比事後排查好用得多。
OpenAI 的回應說明了什麼
原文最後提到,OpenAI 研究員 Vaibhav Srivastav 回應說,這個問題已經修復,並隨最新 Codex 版本發布,使用者需要透過 npm 或 bash 安裝腳本升級。這個回應很直接,也挺符合工程現實:先修,再讓大家升級。人名可對照這裡:Vaibhav Srivastav。
但我更在意的是這件事暴露出來的節奏問題。一個安全工具剛高調發布,社群馬上抓到資源寫入異常,這會讓人對「預設安全」這句話多一層懷疑。不是說功能沒價值,而是說發布時對資源邊界的把控還不夠細。
我一直覺得,做基礎設施工具的人最該怕的不是「功能不夠多」,而是「預設值太激進」。預設值一旦激進,使用者就會替你承擔後果。Codex 這次的日誌問題就是典型例子:你不改設定,它就按自己的節奏寫,最後硬碟先扛不住。
如果你在團隊裡推類似工具,我的建議很簡單:預設關閉高頻 TRACE;預設只保留摘要日誌;預設給本地儲存加上上限;預設把升級說明寫得比功能介紹更醒目。聽起來很保守,但這才是能長期跑的做法。
說白了,AI 工具進入安全場景後,最值錢的不是「會不會找漏洞」,而是「會不會老老實實待在邊界裡」。邊界感差的工具,能力越強,風險越大。
你可以直接照著改的那套做法
如果你現在也在做一個會長時間運行、會寫日誌、會碰本地儲存的 AI 工具,我建議你直接拿下面這套規則當起點。它不花俏,但能救命。
第一,把日誌策略拆成三檔:預設、除錯、稽核。預設檔只保留必要事件,除錯檔只在短時間內打開,稽核檔單獨落盤並限流。第二,把本地持久化從「預設開啟」改成「顯式開啟」。第三,給每個 agent 加資源預算,尤其是磁碟寫入預算。第四,所有長任務都要有超時和降級路徑。
我知道很多團隊會嫌這套流程麻煩,但麻煩是有意義的。因為一旦工具開始常駐,任何一個「先不管」的小洞,最後都會變成維運帳單。你不在設計階段管住它,就只能在事故階段補票。
最後我想說,OpenAI 這次的兩面性其實很典型:一邊是更強的安全能力,一邊是更糟的資源失控。開發者真正該學的,不是站隊夸誰,而是把這種反差當成警報。能力提升了,邊界也必須一起收緊,不然工具會比你想的更快把自己玩壞。
可抄的模板
# AI 安全插件資源控制模板
## 1. 預設策略
- TRACE 日誌預設關閉
- 只保留摘要日誌,保留期 7 天
- 本地 SQLite 僅用於短期快取,不用於無限追加
- 所有長任務必須設定超時
## 2. 磁碟寫入預算
- 單個 agent 每小時最大寫入:100 MB
- 單個 agent 每天最大寫入:1 GB
- 超過預算後自動降級為摘要模式
- 超過 2 次預算觸發,自動暫停高頻日誌
## 3. 日誌分層
- 熱日誌:記憶體環形緩衝
- 冷日誌:批次刷盤,每 30 秒一次
- 稽核日誌:單獨目錄,單獨配額
## 4. SQLite 使用規範
- 禁止把 TRACE 級別日誌直接寫入主 SQLite 檔案
- 只允許寫入聚合後的事件摘要
- 設定資料庫最大大小上限
- 啟用輪轉和清理任務
## 5. 執行期保護
- 流式任務開啟 I/O 監控
- 當寫入速率超過閾值時自動降級
- 當磁碟占用超過 80% 時暫停非必要記錄
- 記錄所有降級動作到稽核日誌
## 6. 升級檢查清單
- 檢查預設日誌等級
- 檢查本地快取目錄位置
- 檢查磁碟配額是否啟用
- 檢查長任務是否有超時
- 檢查是否存在無限寫入路徑
## 7. 團隊落地建議
- 安全掃描和日誌系統分開評審
- 把資源預算寫進 PR 模板
- 上線前做 24 小時壓力測試
- 把寫入量納入可觀測性面板
## 8. PR 模板裡直接加這一段
### 資源與日誌檢查
- [ ] 是否新增高頻日誌
- [ ] 是否寫入本地持久化儲存
- [ ] 是否設定寫入速率上限
- [ ] 是否設定磁碟配額
- [ ] 是否有降級和回滾方案
## 9. 適合貼到 README 的一句話
本專案中的 AI 元件預設受磁碟寫入預算約束,禁止無限制高頻落盤。
這套模板不是專門給 Codex 用的,是給所有「會長時間跑、會寫日誌、會碰本地儲存」的 AI 工具用的。你可以直接貼進 PR 模板、平台規範或者 README 裡,先把邊界立起來,再談智慧。
來源:https://zhuanlan.zhihu.com/p/2052695927035531367。其中關於 GPT-5.5-Cyber、Codex Security、Patch the Planet 和 SQLite 寫盤問題的敘述,主要來自原文與其引用的社群回饋;我在這裡做的是面向開發者的拆解和模板化整理,不是原文照抄。