DeepSpec 應被視為資料重生管線,而不是訓練技巧
DeepSpec 最好的理解方式,是把它當成對對話資料做重生的管線,而不是一個單純的訓練技巧。

DeepSpec 最好的理解方式,是把它當成對對話資料做重生的管線,而不是一個單純的訓練技巧。
DeepSpec 應該被視為資料重生管線,不是訓練花招。以 Qwen3 搭配 Eagle3 的流程來看,核心動作很直接:保留 system 與 user turn,丟掉原本的 assistant turn,再透過相容 OpenAI API 的服務把這段 assistant 答案重新生成。這不是實作細節,而是訓練訊號的來源被改寫了,模型學到的不再是混雜品質的對話紀錄,而是你真正想要優化的那個模型家族所產生的回應。
第一個論點:DeepSpec 的價值在於先修正標籤,而不是調整 loss
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這個方法最強的地方,是它把問題往上游移。若一段對話裡的 assistant 回答過弱、過舊,或與目標模型不一致,拿它來訓練就等於教模型模仿錯誤行為。DeepSpec 會用目標模型重新生成那個回答,讓監督目標對齊模型自身的分佈。這比起靠更好的 optimizer 去補救髒標籤,更像真正的蒸餾。

流程本身也說明了這件事:system message 保留,assistant message 刪除,user message 透過 client.chat.completions.create 重播給目標模型。這代表重建後的資料集不是隨機增強,而是對每段對話的 assistant 端做受控改寫。對一個來源混雜的語料庫來說,內部一致性通常比花俏的訓練參數更重要。
第二個論點:OpenAI 相容服務層,才是它能落地的關鍵
DeepSpec 之所以有說服力,不是因為它發明了新解碼器,而是因為它用了一個夠簡單的服務抽象。程式碼直接呼叫帶有本地 base_url 的 OpenAI 風格 client,代表重生步驟可以接到 SGLang 或任何相容推理後端。這大幅降低管線成本,因為你可以替換引擎、擴充吞吐,訓練程式卻完全不用改。
這一點在規模化時尤其重要。資料重生只有在便宜到足以批次執行時才有價值;如果每一步都要自寫 RPC、重寫 decoding、手工串 prompt,資料量一大就會崩。相反地,OpenAI 相容介面把重生變成標準批次工作。對已經有 model serving 基礎設施的團隊來說,這就是實驗概念和可重複資料工廠的差別。
反方可能怎麼說
最強的反對意見是,DeepSpec 會壓縮多樣性。如果每個 assistant turn 都由同一個目標模型重生,資料集就會變得自我參照。模型也許會更像自己,但不一定更正確、更穩健,或更有用。批評者還會指出,重生可能放大目標模型原有的偏誤,並抹掉原始 assistant 輸出的某些有價值訊號。
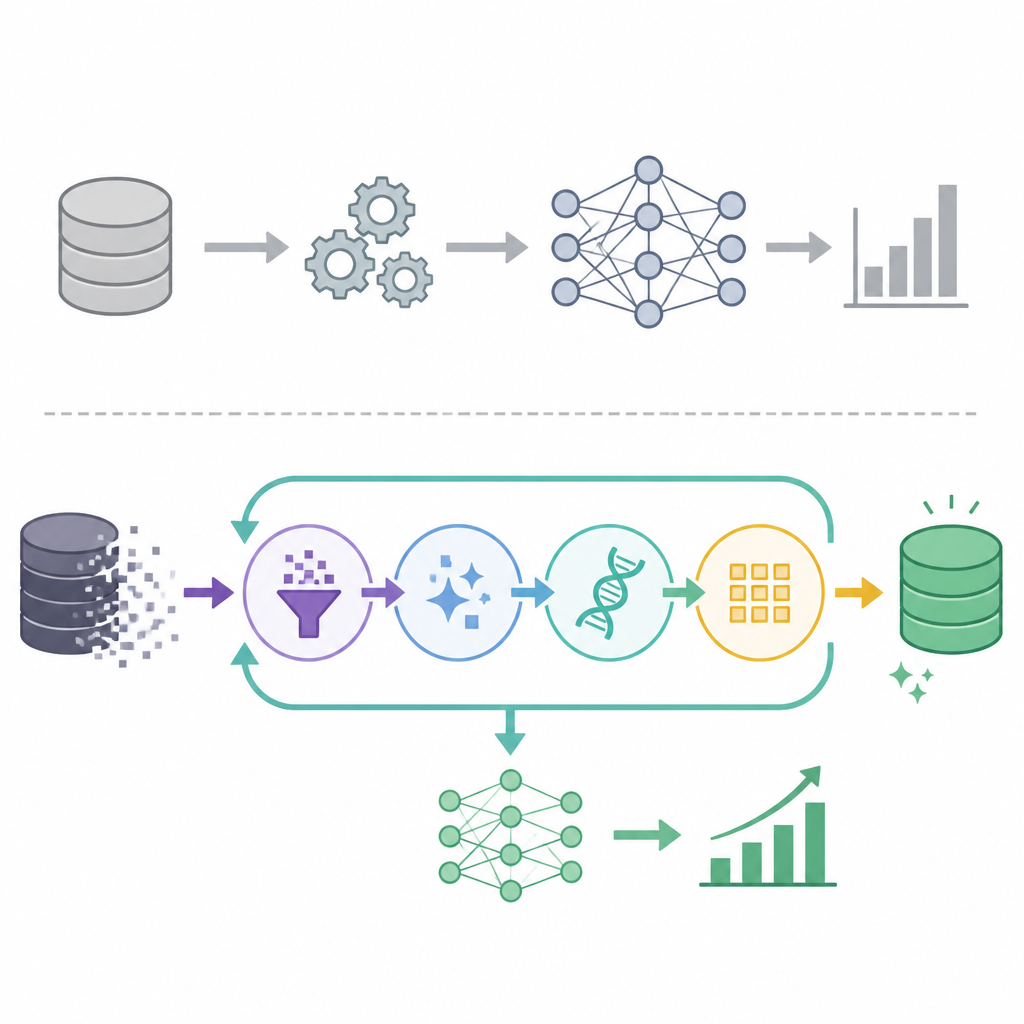
這個質疑是成立的。DeepSpec 不是資料清洗的全部,也不是人類評測或任務基準的替代品。它是一個過濾與對齊步驟,不是 truth oracle。不過,這個限制不削弱方法本身,反而界定了它的用途:當基礎語料雜訊高、回答不一致時,先用更強的目標模型重生 assistant turn,合理地把訓練底盤墊高,再進入 fine-tuning。重點是把重生後的資料當成更好的訓練基材,而不是當成真理。
你能做什麼
如果你是工程師、PM 或創辦人,當你的訓練集有不錯的 user prompt,卻有不可靠的 assistant 回答時,就該用 DeepSpec。把管線建立在穩定的 chat API 上,保留 system 和 user turn,分批重生 assistant turn,並用留出評測比較新舊資料。若重生後的語料能提升一致性、拒答品質與指令遵循,而且沒有讓困難任務表現被抹平,就保留它;若只是讓模型更會說漂亮話,卻更不準,就停下來重整來源資料。