當目標是文風不是事實時,微調比 RAG 更有效
如果你要訓練 LLM 學會特定文風,微調才是正解;RAG 比較適合補事實,不適合改寫作風格。

如果你要訓練 LLM 學會特定文風,微調才是正解;RAG 比較適合補事實,不適合改寫作風格。
如果你要 LLM 寫出 1990 年代技術文件的味道,答案不是檢索,而是微調。Fabrizio Ferri Benedetti 的實驗把這件事講得很清楚:他用數千萬字的舊版 Microsoft 手冊訓練本地 adapter,最後得到的輸出不只會引用老文件,而是連章節節奏、詞彙選擇、段落開頭都像那個年代的文風。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
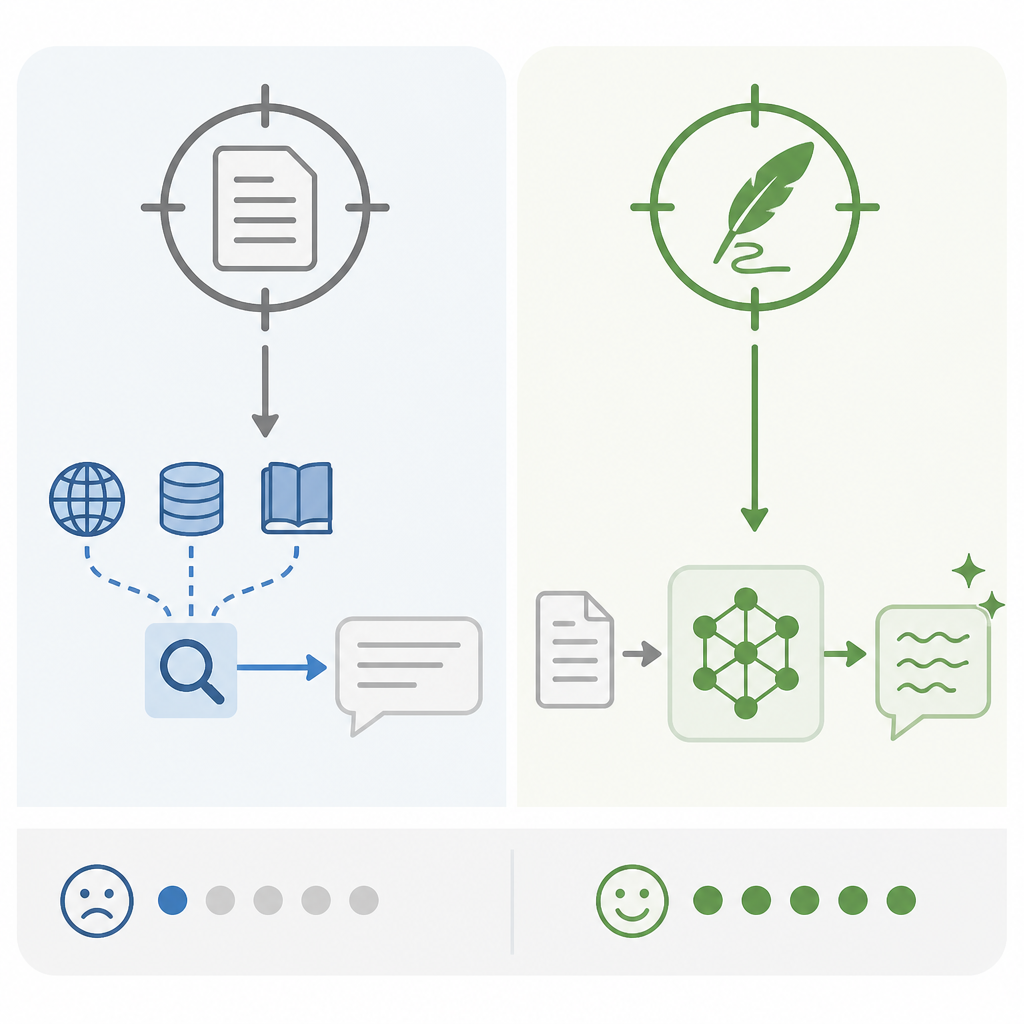
RAG 的設計目標是「回答問題時抓取相關資料」,所以它擅長的是事實正確、來源可追溯、內容可更新。這很適合產品手冊、法規問答、內部知識庫,但不適合文風轉換。Benedetti 的測試提示刻意偏向風格任務,例如要模型用 1990 年代 Microsoft 的口吻解釋 malloc(),或替虛構的 ConnectWifi() API 寫文件;微調後的模型真的寫出 man page 式標頭、synopsis 區塊與年代感措辭。

這裡的差別不是「有沒有看到範例」,而是「有沒有改變行為」。基準模型多半只會輸出現代 Markdown、親切解說,甚至直接跑題;微調後的 Qwen 變體卻能在不同提示下維持相同的註解格式與敘述節奏。文風不是一段可被撈出的文字,而是一組輸出分佈。你要的是分佈偏移,微調才做得到。
第二個論點
小型 adapter 已經足夠捕捉強烈風格,而且成本低到個人也能做。Benedetti 用的是 QLoRA,凍結底層權重,只在上面加輕量 adapter,整個實驗大約花了 50 美元、一天左右就完成。這代表不是只有大公司能做風格模型,獨立開發者也能在租來的 GPU 上完成一次可用的文風訓練。
資料品質比花俏提示更重要,這在他的結果裡很明顯。作者從 Bitsavers 蒐集、清理 OCR 噪音、過濾可讀段落,最後做出超過 192,000 筆 instruction 範例。這種語料反覆灌輸同一套文件慣例,像是標題、回傳值、程式碼區塊、交叉引用與範例。單靠 prompt engineering 不會長出這種深度模式;只有把這些模式寫進模型,才會真的穩定重現。
反方可能怎麼說
RAG 支持者的論點其實很強:如果你在乎的是正確性、來源、以及最新資訊,檢索比把知識烘進權重更安全。文件庫比重新訓練更容易更新,答案也更容易附上引用、稽核與修正。對企業系統來說,RAG 常常是更穩的預設方案。
還有成本問題。微調需要整理語料、跑訓練、做評估,還要維持部署流程;RAG 常常能直接接到既有架構上,前期阻力更小。對那些這季就要交付產品的人來說,檢索看起來確實比較務實。
但這個論點只適用於事實任務,不適用於文風任務。當你的目標是讓模型寫出特定年代、特定團隊或特定媒體的語氣,RAG 只是把更多文字放進上下文,並沒有改變模型的預設輸出習慣。Benedetti 的結果證明,模型必須內化模式,而不是旁邊放一堆範例。要風格就用微調,要事實就用 RAG,兩者不是替代品。
你能做什麼
如果你是工程師或 PM,先把問題拆成兩層:用 RAG 管來源真實性,用微調管語氣、結構與格式;如果你是創辦人,不要賣「RAG 解決一切」,而是賣一個知道何時該檢索、何時該模仿的系統。這才是文件助手、品牌寫作工具與內部知識產品真正的分工。風格靠訓練,事實靠檢索,懂這條線的人,會做出更好的產品。