SFT、LoRA、DPO、RLHF、GRPO 選型指南
一篇實作指南,幫你依資料型態、硬體與目標,選出合適的 LLM 微調方法。

這篇教你依資料型態、硬體與目標,選出合適的 LLM 微調方法。
這篇給 ML 工程師、應用 AI 開發者與技術主管看,目的是把基礎模型改造成符合產品資料、語氣或推理目標的版本。照做完,你會得到一條可執行的選型路徑,知道 SFT、LoRA、QLoRA、DPO、RLHF、GRPO 與全量微調各自適合什麼資料與算力。
你也會拿到一個簡單判斷法:先看你手上的標註,再對應訓練目標,最後挑能達到品質門檻、但成本最低的方法。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Hugging Face 帳號,並可存取 Transformers 文件與 PEFT GitHub repo。
- Python 3.10+
- PyTorch 2.2+
- 可用 CUDA 的 GPU,QLoRA 至少 16 GB VRAM,LoRA 或 SFT 較順手則建議 24 GB 以上。
- 至少一份可用資料集,格式可以是 input-output pairs、preference triples,或可規則評分的 completions。
- 可選但實用:Weights & Biases 帳號,用來記錄訓練曲線。
Step 1: 分類你的訓練資料
第一步是先看你手上的標註長什麼樣,因為資料格式會直接決定方法。每個 prompt 如果只有一個正解,就走 supervised fine-tuning。若你有被選中與被拒絕的回答,就屬於 preference training。若你能用規則自動打分,就可以走 reinforcement-style optimization。

在寫任何訓練程式前,先把資料整理成以下三類之一。
input-output pairs -> SFT / LoRA / QLoRA
(prompt, chosen, rejected) -> DPO / RLHF
prompt + scoring rule -> GRPO-style RL你應該看到每一列資料都能被一句話標記。若你無法用一句話說清楚 row type,代表資料還沒整理好。
Step 2: 用 SFT 訓練標準輸出
當你想讓模型模仿已知好答案時,就用 supervised fine-tuning。這是產品團隊最常用的起點,特別適合穩定語氣、格式、分類標籤與領域措辭。Instruction tuning 是常見變體,資料看起來像短對話,一邊是 user,一邊是 assistant。
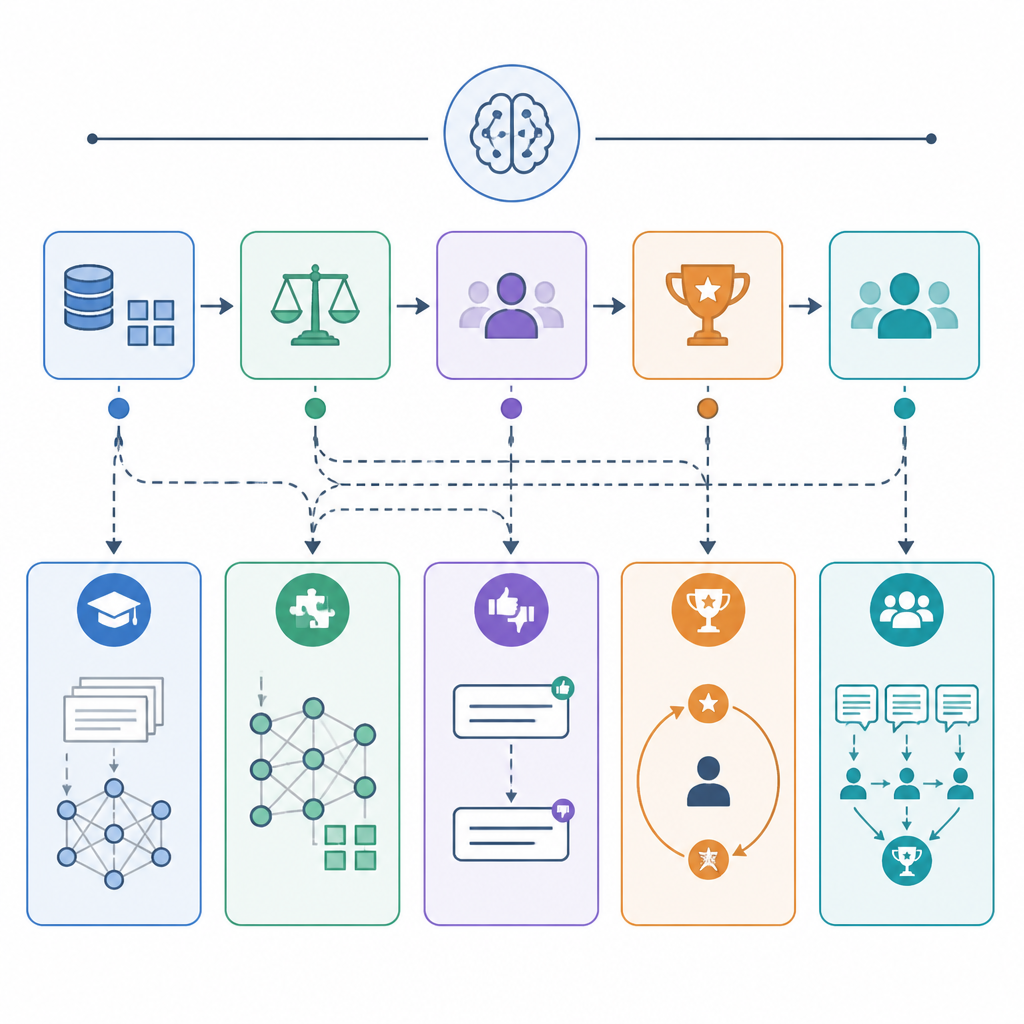
SFT 的做法是直接用標註好的 prompt-answer pairs 更新模型,讓它在新提示上產生相似回答。若你想降低算力,通常會把 SFT 和 parameter-efficient fine-tuning 一起用,只訓練 adapter,不動整個 base model。
你應該看到 training loss 下降,而且抽樣輸出開始更接近目標風格。快速驗收的方法,是拿 validation set 的例子去問模型,確認回答的結構與語氣一致。
Step 3: 用 LoRA 或 QLoRA 加上 adapter
當你不想更新每一個權重時,就選 LoRA。它會凍結 base model,只訓練小型低秩矩陣,去調整各層行為。當 base model 放不進 GPU 記憶體時,就選 QLoRA,因為它會把凍結權重壓成 4-bit,再保留可訓練的 adapter 用較高精度更新。
可以先用這個判斷:如果你有足夠 VRAM 跑 reduced precision 的 base model,就先考慮 LoRA;如果你需要在較小 GPU 上跑較大的模型,就用 QLoRA。對 7B 模型來說,單張 16 GB 卡常常是 QLoRA 的實用路線。
你應該看到訓練時只有 adapter weights 在變,而 base checkpoint 保持不動。若你檢查輸出檔案,應該會看到小型 adapter 檔,而不是整包模型被重寫。
Step 4: 用 DPO 或 RLHF 優化偏好
當答案沒有唯一正解,但你能判斷哪個比較好時,就用 preference training。若你已經有 prompt、chosen、rejected 三元組,DPO 是較輕量的選項。它是單一離線訓練流程,不需要另外訓練 reward model。
若你需要完整 alignment pipeline,而且預算也夠,RLHF 會更合適。RLHF 先用人類偏好訓練 reward model,再用 reinforcement learning 把 policy 往偏好的輸出推進。它成本較高,但當人類判斷很重要時,是很標準的做法。
你應該看到模型在 held-out prompts 上更常偏好 chosen response。快速驗收的方法,是比較成對輸出,確認訓練後的偏好風格更一致。
Step 5: 用 GRPO 跑規則評分推理
當你能用規則直接替輸出打分時,就選 GRPO。這很適合數學、程式碼與精確比對任務,因為 reward 可以來自 verifier、測試套件,或正式的 scoring function。模型會一次取樣多個答案,先評分,再學習偏向高分完成。
GRPO 的價值在於,它用可驗證的正確性取代人類偏好標註。DeepSeek-R1 就是常被提到的代表案例。
你應該看到模型在客觀任務上的表現變好,例如測試通過率上升或最終答案更正確。若你的 scoring rule 很吵或很模糊,GRPO 會比較難穩定。
Step 6: 只在需要全控制時做全量微調
當你真的需要每個參數都能移動時,才用 full fine-tuning。它彈性最大,但也最吃 VRAM、最耗時,還需要更強的訓練、版本管理與部署能力。通常它比較像是做領域基礎模型的團隊會走的路,而不是只想客製單一助理的產品團隊。
如果 adapter 不足以改變模型表徵,或你必須擁有完整 checkpoint 生命週期,全量微調才是正解。對多數應用來說,它是最後一站,不是第一站。
你應該看到模型行為變化最大,但同時也會看到算力與維運複雜度一起上升。若團隊無法穩定管理完整 checkpoint,就退回 LoRA 或 QLoRA。
| 指標 | 基準/優化前 | 結果/優化後 |
|---|---|---|
| 7B base model 記憶體 | 約 14 GB bf16 | QLoRA 約 4 GB 4-bit NF4 |
| VRAM 需求 | 較容易的 full-base runs 需要 24 GB+ | 16 GB 硬體可足夠跑 QLoRA |
| 可訓練參數量 | 全量微調為數十億參數 | LoRA adapter 在 7B 模型上通常只有數千萬參數 |
常見錯誤
- 把偏好資料拿去做 SFT。修法:若資料列是 prompt、chosen、rejected,就改用 DPO 或 RLHF。
- 一開始就做全量微調。修法:除非你真的需要每個權重都動,否則先用 LoRA 或 QLoRA。
- 沒有穩定的評分規則就用 GRPO。修法:只在 reward 可以被客觀驗證時使用,例如測試通過或 exact match。
接下來可以看什麼
選定方法後,下一步是設計資料集、切分 train 與 validation,並定義和目標一致的評估指標。接著你可以在同一任務上比較 adapter-based training、preference optimization 與 full checkpoint training,找出品質與成本最划算的組合。