Modulate 用 AWS 把語音聊天做成訊號
我拆 Modulate 的 AWS 架構,整理成台灣開發者可直接抄的語音分析管線、排隊策略與模板。
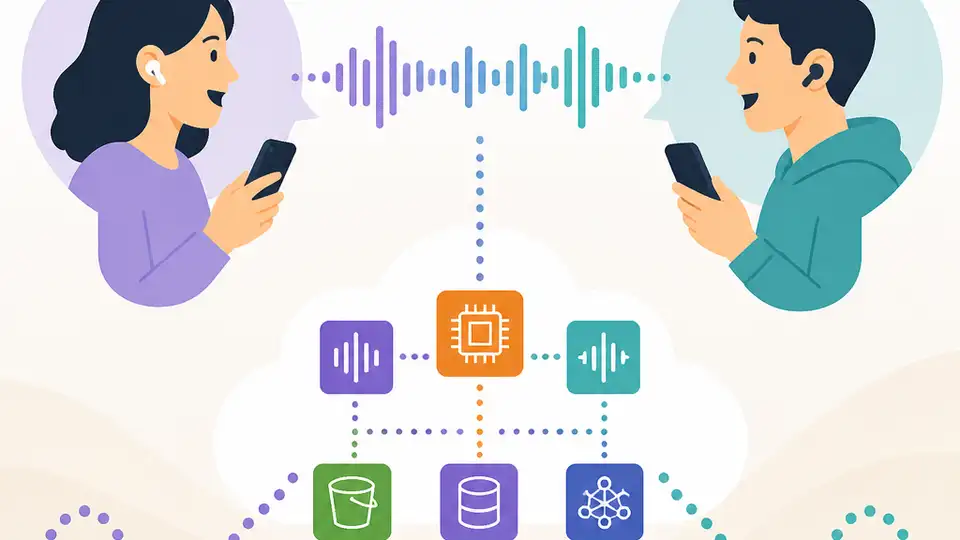
我把 Modulate 的 AWS 語音分析架構拆開,整理成可直接照抄的事件驅動管線、排隊策略和模板。
我看 Modulate 這套語音審核架構一陣子了,越看越有感。很多團隊一碰到語音聊天,就急著把 STT、模型、儀表板全塞進去,結果看起來很完整,跑起來卻像一坨黏在一起的流程。延遲一高,成本一飆,大家就開始怪模型不準,怪雲服務太貴,怪使用者太吵。問題通常不是這些。問題是你一開始就把系統做成一個大包袱。
Modulate 讓我覺得順眼的地方,不是它多會講 AI,而是它把語音聊天當成一條可重複處理的管線。先切成工作,再丟進佇列,再交給短命的服務去跑。這種做法很無聊,但很對。比起在簡報上講得天花亂墜,我更相信能撐住真實流量、能重複部署、能換場景的系統。這才是我想拆的方法論。
外部錨點:AWS 的案例研究先把形狀講清楚
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
我這次主要看的是 AWS 的案例研究:Building a Cost-Effective, AI-Driven Voice Intelligence Solution on AWS with Modulate。裡面沒有在賣弄理論,直接把他們怎麼用 AWS Lambda、Amazon SQS、Amazon Transcribe、Amazon SageMaker 串起來講得很明白。文中也有幾個我覺得很有用的數字:兩天做出 ToxMod 原型、少於 40 秒完成分析、對 Activision 的毒性暴露降低最多 50%、以及比現成工具便宜 10 到 100 倍的成本敘述。
先做出能跑的流程,再談產品故事
“In 2 days, the company built its first prototype for ToxMod, a product that is purpose-built for games to help proactively moderate voice chats.”
翻譯一下就是:他們不是先把品牌故事寫滿,再回頭硬湊技術。先做出最小可行流程,確認語音資料真的能被處理,才往產品化走。這個順序很重要,因為很多團隊死在相反的路線上。先畫一個很漂亮的未來藍圖,結果資料流根本不穩,最後只能拿手工補洞。
我以前幫一個團隊看過語音客服的審核流程,他們一開始想把錄音上傳、轉文字、風險評分、通知客服,全放在同一個同步請求裡。圖畫起來很整齊,實際上只要其中一段慢一點,整條鏈就卡死。後來我叫他們先拆成事件流:上傳是上傳,分析是分析,通知是通知。一下子就好測多了,出錯也比較知道卡在哪。
實操寫法很簡單:先別急著做完整產品。先做一條從語音輸入到判斷輸出的最短路徑,確認資料真的能流過去。你要驗證的是流程,不是簡報。
- 先定義一個最小事件:例如「收到一段語音」。
- 只做一條最短鏈:接收、排隊、轉文字、打分、回傳。
- 先看延遲和失敗點,不要先追求介面漂亮。
Serverless 不是信仰,省下閒置成本才是重點
“We built this architecture on AWS to analyze voice 10–100 times more cost effectively than what we could do with off-the-shelf tools.”
這句我很買單,因為它講的是成本,不是姿勢。很多人講雲端架構,講到最後都在比誰比較會用新名詞。我不在乎你是不是用 serverless,我在乎的是你有沒有把錢花在真的有工作量的地方。語音分析這種東西很容易有尖峰流量,平常很閒,一來事件又暴衝。如果你為了這種工作量養一整批常駐服務,帳單一定很難看。
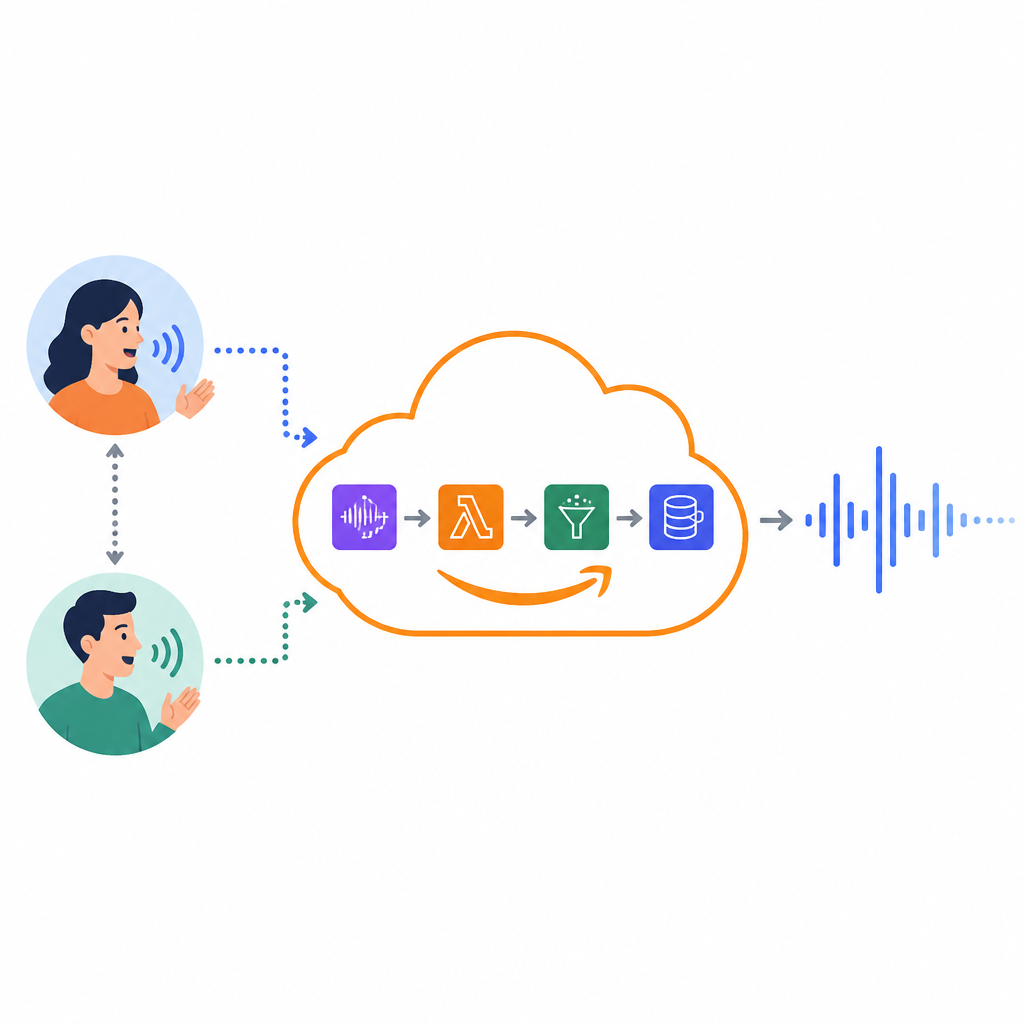
Modulate 用 AWS Lambda 的思路很務實。它不是把所有東西都丟進 Lambda,而是把適合短任務、事件驅動的部分切出去。這樣做的好處很直白:不用為了等流量而空燒資源,也比較容易把成本跟實際用量綁在一起。這比什麼「雲原生」四個字有用多了。
我之前看過一個語音質檢系統,團隊把音檔處理、特徵抽取、模型推論全部放在一台 VM 上,結果白天忙、晚上空,但費用照樣不小。後來改成事件驅動,尖峰時自動擴,平常縮掉,成本才終於像樣。
實操寫法是:先畫出你的事件來源,再決定哪段工作適合短生命週期的運算。不要先問「要不要上 serverless」,先問「哪裡在等資料、哪裡在燒閒置」。
- 把尖峰流量和常態流量分開看。
- 把可重試、可平行的工作拆出去。
- 先量每分鐘處理成本,再談整體雲帳單。
佇列才是把「即時」變成可運作的關鍵
“Modulate automatically queues its jobs using Amazon Simple Queue Service (Amazon SQS), a fully managed message queuing for microservices, distributed systems, and serverless applications.”
這段很關鍵。很多產品喜歡說自己是即時,但實作上其實是同步硬撐。只要其中一段慢了,使用者就開始體感延遲。Modulate 的做法是先把工作排進 Amazon SQS,再讓後面的處理器平行吃單。也就是說,它不是假裝所有步驟都要同一秒完成,而是承認語音分析本來就需要一點緩衝。
案例裡提到他們可以在少於 40 秒內把結果交給客戶。這不是秒回,但對語音審核、風險偵測、詐欺判斷來說,這已經夠接近可行動的時間窗了。重點不是你有多快,而是你有沒有快到能介入當下情境。
我很常看到團隊把轉文字、模型推論、結果寫回做成一條硬同步鏈。這種設計一開始很爽,因為看起來像一個 API;流量一上來就出事。佇列的價值不是炫技,而是讓每一段都能獨立失敗、重試、擴容,不會整條一起陪葬。
實操寫法:把每個語音事件切成小工作單位,不要整段會話一口氣全塞進同步請求。能排隊的就排隊,能平行的就平行,能延後的就延後。
- 用佇列承接工作尖峰,不要直接壓在 API 上。
- 給每個步驟獨立重試機制。
- 把延遲目標訂成產品能接受的值,不要訂成面子工程。
他們沒迷信單一模型,而是把不同層次拆開
“To detect harmful speech, Modulate pairs the generative AI capabilities of large language models with bespoke audio analysis models.”
這句話很老實,也很像真的做過產品的人會講的話。語音審核不是單靠文字理解就夠了,因為語氣、音量、停頓、情緒,很多東西不是純文字能看出來的。Modulate 把大型語言模型跟客製化音訊分析模型一起用,等於是承認問題本來就有不同層次。
我喜歡這種拆法,因為它不把 AI 當萬靈丹。Amazon Transcribe 負責轉文字,SageMaker 負責訓練和部署自家模型,語意判斷再交給更上層的模型。這樣的分工很像做工程該有的樣子:能交給現成服務的就不要重做,真正有差異的地方才自己下去磨。
我看過不少團隊一頭熱想自己訓練整套語音辨識,最後只是在重造輪子。你如果不是語音辨識公司,真的沒必要從零搞起。你該花力氣的地方,是怎麼把辨識結果變成產品可用的訊號。
實操寫法:把 commodity layer 和 differentiated layer 分開。前者盡量用現成服務,後者才是你真正要控制的模型、規則和閾值。
- 轉文字交給成熟服務。
- 音訊特徵和風險判斷保留自家邏輯。
- 模型更新要能單獨替換,不要整個系統一起重跑。
可重用的不是功能,是整條骨架
“We can tune our system for different use cases and redeploy the same architecture and services for our different products with relatively little development work.”
這句其實就是整篇案例的核心。Modulate 真正值錢的不是某個功能,而是那條能重複使用的骨架。今天做遊戲語音審核,明天可以轉去叫車安全、詐欺偵測、客服稽核。場景變了,但資料流、排隊方式、部署方式可以大致不變。這才叫有資產感的架構。
我以前很討厭那種每接一個新客戶就重新做一套的團隊。每次都說「這個客戶很特殊」,結果特殊到最後,程式碼庫像垃圾場。Modulate 這種做法比較像把共通骨架先做穩,之後只換模型設定、門檻、通知規則。這樣新案子才不會每次都從零開始。
而且這種重用不是省工而已,是讓商業模式變得比較像樣。當你能把同一套架構快速套到不同垂直場景,你的交付速度、維運成本、學習曲線都會一起下降。這比每次重新發明一次管線實際太多了。
實操寫法:先把流程抽象成骨架,再把客戶差異放進設定。只要核心事件流不變,新案子就不該需要重寫整個平台。
我會直接抄的模板,不用客氣
如果你現在就在做語音審核、通話分析、客服風險偵測,下面這段我會直接拿去改。它不是照抄 AWS 文件,而是我把 Modulate 這套形狀翻成比較能落地的版本。你可以先從這個骨架開始,再換成你自己的服務名稱、模型和規則。
# 語音訊號分析管線模板(AWS 版本,可直接改用於台灣團隊內部系統)
## 目標
把語音聊天轉成可行動的訊號,在可接受延遲內完成審核、風險判斷或詐欺偵測。
## 核心服務
- Amazon API Gateway:接收上傳或事件請求
- AWS Lambda:處理事件與中繼邏輯
- Amazon SQS:承接工作、削峰、平行處理
- Amazon Transcribe:語音轉文字
- Amazon SageMaker:訓練與部署自家模型
- 選配:大型語言模型層,做語意補強與摘要
## 資料流
1. 客戶端送出語音片段或會話事件。
2. API Gateway 驗證請求後交給 Lambda。
3. Lambda 建立工作單,寫入 SQS。
4. Worker Lambda 從 SQS 取單並平行處理。
5. 每個 worker 依序做:
- 取出音檔或片段
- 送去 Transcribe 轉文字
- 跑自家音訊分析模型
- 視需要呼叫大型語言模型做語意分類
- 寫回資料庫、Webhook 或事件匯流排
6. 系統回傳審核結果、風險分數或警示標記。
## 設計原則
- 每一段只做一件事,方便替換。
- 只要能接受延遲,就不要硬做同步。
- 先處理片段,不要一開始就吞整段會話。
- 所有模型門檻都要可配置。
- 量成本時看每分鐘處理費用,不要只看總雲帳單。
- 量效能時看端到端延遲,不要只看單一服務回應時間。
## 推薦架構
API Gateway → Lambda → SQS → Lambda Workers → Transcribe / SageMaker → 結果儲存
## 推薦監控指標
- 每分鐘分析成本
- 佇列深度
- p95 延遲
- 失敗重試率
- 模型信心分數
- 毒性或風險命中率
## 可直接改的設定範例
audio_pipeline:
max_latency_seconds: 40
processing_mode: async
queue: sqs
transcription: amazon_transcribe
model_runtime: sagemaker
classification_layers:
- audio_signal_model
- transcript_model
- llm_reasoning
routing:
game_moderation: toxmod
ride_safety: voicevault
fraud_detection: voice_risk
metrics:
- cost_per_minute
- p95_latency
- false_positive_rate
- false_negative_rate
## 先抄這三個地方
- 佇列式工作流
- 轉文字與自家分析分層
- 同一套骨架重複部署到不同場景我自己的結論很簡單:Modulate 這種架構厲害的地方,不是看起來很 AI,而是它很像真的能活下去的系統。它把語音聊天變成可排隊、可重試、可重用的訊號,這比把所有東西塞成一個超大 API 實際太多了。
這篇主要衍生自 AWS 的案例研究:https://aws.amazon.com/solutions/case-studies/modulate-case-study/。我保留了原始案例裡的產品名稱、服務名稱與數字,其他拆解、白話翻譯和模板都是我自己整理的。