Modulate’s AWS setup turns voice chats into signals
I break down Modulate’s AWS voice pipeline and give you a copy-ready serverless template for near-real-time moderation.
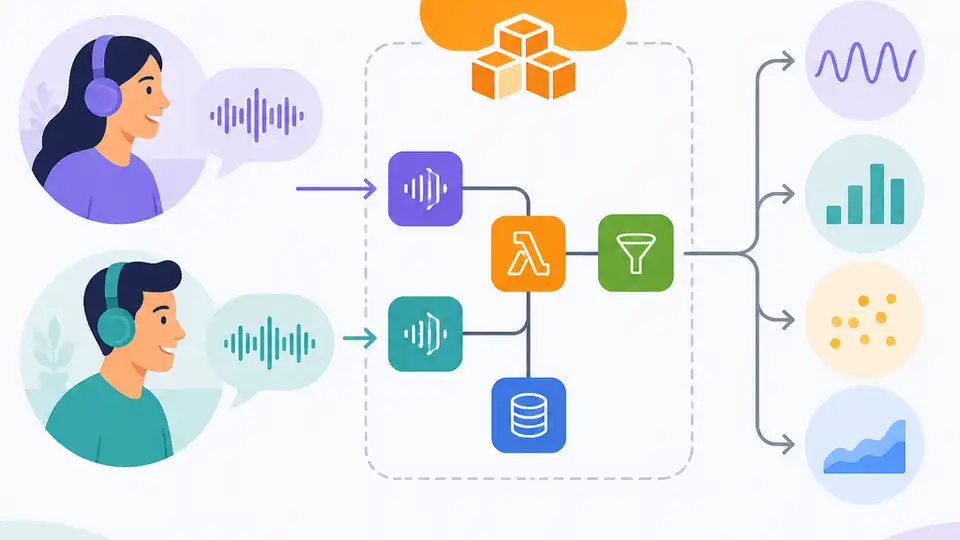
Modulate’s AWS setup turns voice chats into near-real-time moderation signals.
I've been looking at voice moderation stacks for a while, and most of them feel like a mess held together with hope. You get a speech-to-text service here, a queue there, some model inference bolted on later, and then everybody acts surprised when latency gets ugly and the bill starts creeping up. That’s the part that always bothers me: the demo works, but the system doesn’t feel like something you’d want to run all day, every day, at scale.
Modulate’s AWS case study finally made the shape of it click for me. Not because the idea is flashy, but because they built the whole thing like a pipeline, not a pile of features. They took voice conversations, broke them into jobs, pushed them through serverless pieces, and kept the architecture reusable enough to move from gaming moderation to rideshare safety and fraud detection. That’s the kind of engineering I respect. It’s not trying to be clever in public. It’s trying to survive production.
What I also like is that they didn’t pretend one model would solve everything. They combined speech-to-text, custom audio analysis, generative AI, and a queue-based flow so the system can keep moving without someone babysitting servers. That’s the real lesson here: if you want voice intelligence to be cost-effective, you need to design for repetition, not heroics.
Source wise, I’m working from AWS’s case study, Building a Cost-Effective, AI-Driven Voice Intelligence Solution on AWS with Modulate. The details that mattered to me were the 2-day prototype for ToxMod, the less-than-40-second analysis target, the up to 50 percent reduction in toxicity exposure for Activision, and the claim that the architecture runs 10–100 times more cost effectively than off-the-shelf tools.
They built the pipeline before they built the pitch
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
“In 2 days, the company built its first prototype for ToxMod, a product that is purpose-built for games to help proactively moderate voice chats.”
What this actually means is Modulate didn’t spend months polishing a slide deck and then panic-build the backend. They proved the workflow fast, then turned that proof into something repeatable. I’ve seen teams do the opposite and suffer for it. They overcommit to a product narrative before they know if the data path is even sane.
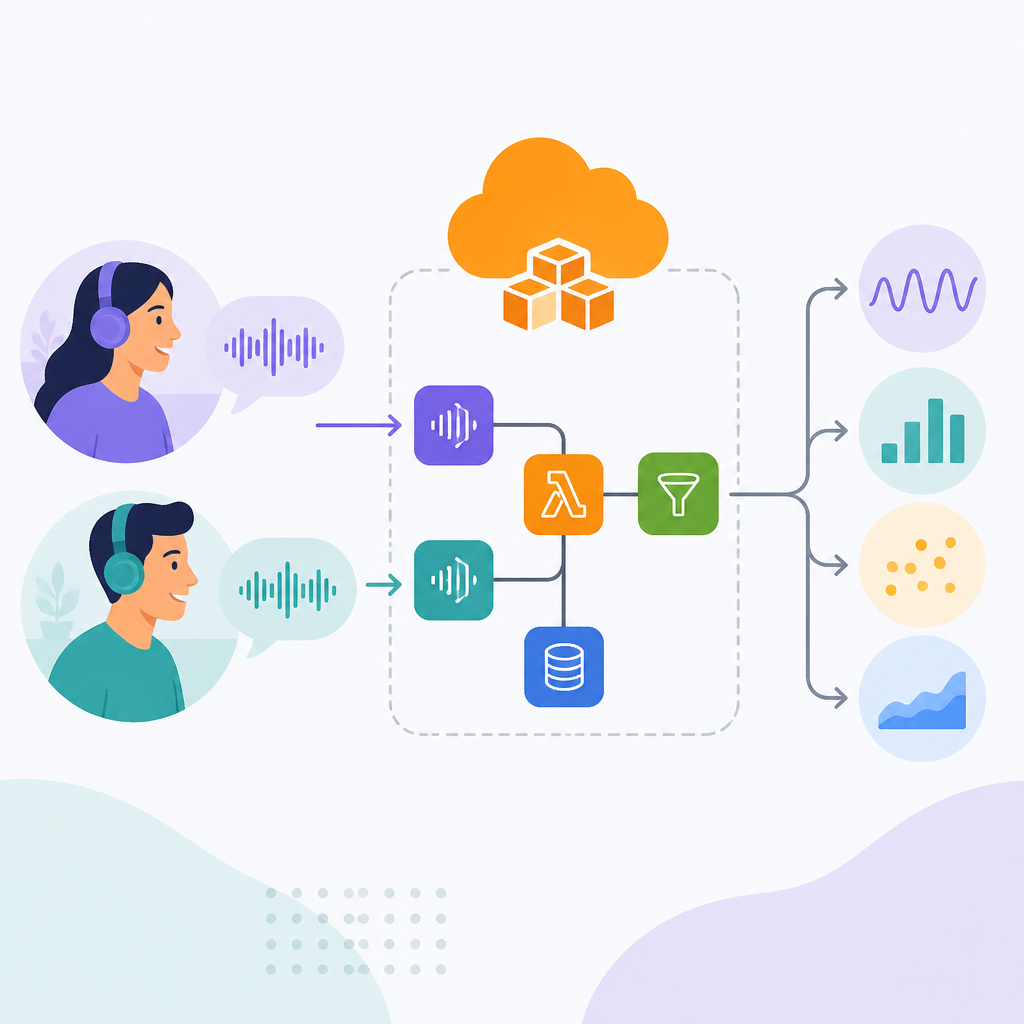
The important bit is not the two days. It’s the sequence. Prototype first, then architecture. They used AWS Lambda because it let them move quickly without buying into server management overhead. That’s the right instinct when your product depends on unknowns like volume, latency, and model quality. If the idea is wrong, you want to find out early. If the idea is right, you want a path to scale that doesn’t require a rewrite.
I ran into this same pattern when helping a team design a call-review workflow. Their first instinct was to build a monolith around audio ingestion, transcription, and scoring. It looked tidy in diagrams and awful in practice. Once we split it into event-driven steps, the whole thing became easier to test and cheaper to operate. That’s what Modulate seems to have understood from the start.
How to apply it: build the thinnest possible end-to-end path first. Don’t optimize for elegance. Optimize for proving that audio can move from input to decision fast enough to matter. If you can’t do that in a short prototype, the rest of the architecture is probably fantasy.
Serverless is not the point. Predictable cost is
“We built this architecture on AWS to analyze voice 10–100 times more cost effectively than what we could do with off-the-shelf tools.”
People love to talk about serverless like it’s a religion. I don’t care about the label. I care that Modulate used it to avoid paying for idle infrastructure while still being able to absorb spikes in voice traffic. That’s the actual win. If your workload is bursty and event-driven, serverless is just a practical answer to a boring but expensive problem.
The case study says Modulate has been on AWS since day one and chose AWS Lambda as a core part of the architecture. That matters because familiarity reduces friction. A lot of teams pick a new platform for ideological reasons, then lose months learning the platform while the product waits. Modulate didn’t do that. They used what they already knew, which let them move fast and keep the system simple enough to replicate.
The cost story also explains why this matters beyond gaming. Voice analysis can get expensive quickly when you try to process everything all the time. If you build it around always-on compute, your margins get ugly. If you build it around events, queues, and short-lived functions, you can tie spend to actual usage. That’s what makes the pay-as-you-go model believable instead of just marketing copy.
How to apply it: map your workload by event. Ask what triggers a job, what can be processed in parallel, and what can wait in a queue. Then decide what should be Lambda-style compute, what should be managed services, and what should never be synchronous. If your architecture can’t explain its own idle time, it’s probably too expensive.
- Use serverless for bursty voice workloads, not for everything.
- Keep the expensive parts out of the request path when you can.
- Measure cost per analyzed minute, not just infrastructure spend.
Queues are the difference between “real time” and “fake real time”
“Modulate automatically queues its jobs using Amazon Simple Queue Service (Amazon SQS), a fully managed message queuing for microservices, distributed systems, and serverless applications.”
This is the part most product teams hand-wave away. They say “near real time” and then build a synchronous chain that falls apart the moment traffic gets weird. Modulate didn’t seem to do that. They used Amazon SQS to buffer work and let processing happen in parallel. That’s how you keep the system moving without making every step depend on the last one finishing instantly.
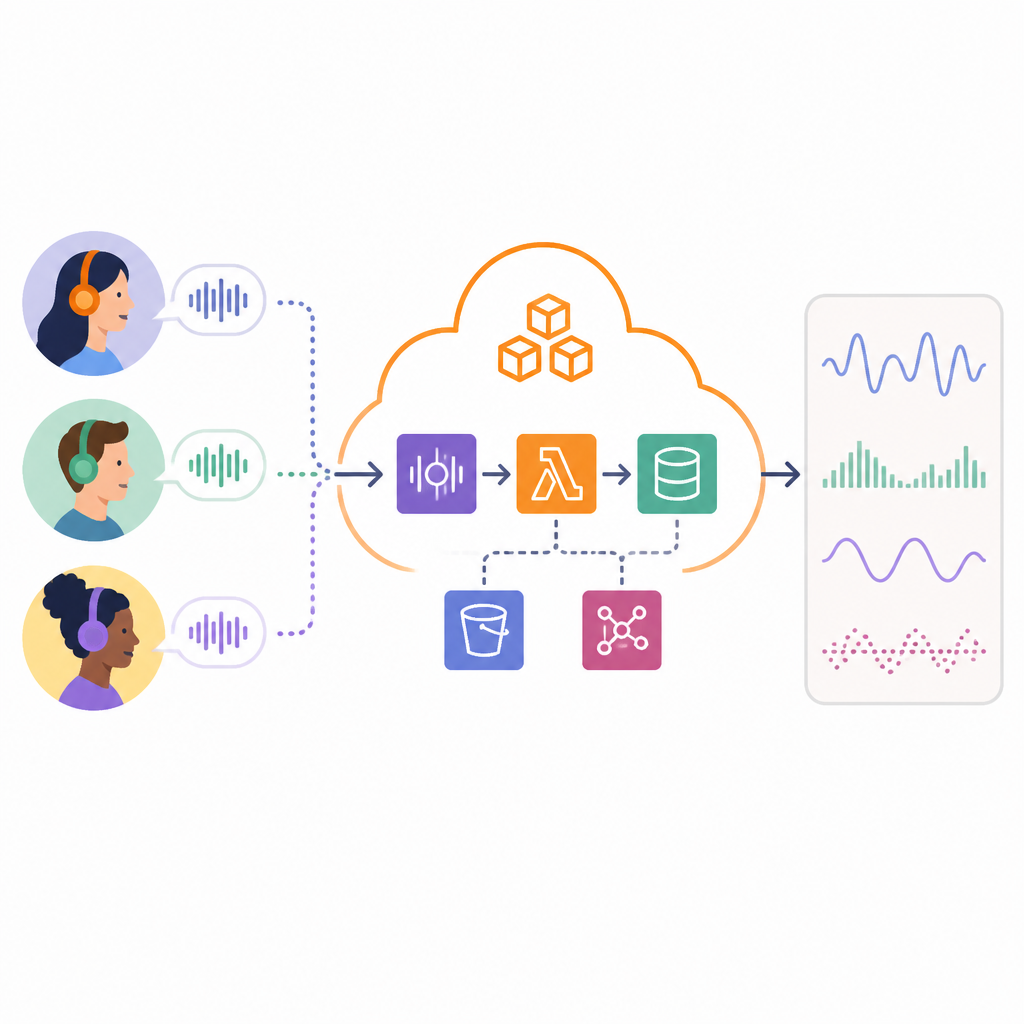
The case study says they can share results with customers in less than 40 seconds. That’s not instant, and that’s fine. In moderation and fraud detection, useful is often better than perfect. If your system can detect harmful speech while the conversation is still active, you’re ahead of the problem. The trick is not to confuse “fast enough to act on” with “must be synchronous.”
I’ve watched teams kill their own latency budget by trying to make audio ingestion, transcription, inference, and response all happen in one request cycle. It looks elegant until traffic spikes or one downstream service slows down. A queue gives you breathing room. It also gives you a place to retry, inspect, and scale independently. That’s not glamorous, but it’s how production systems stay alive.
How to apply it: split the pipeline into stages and let each stage own one job. Put the handoff points on a queue. Make sure each stage can fail without taking the whole system down. Then set a latency target that reflects actual product needs, not ego.
- Queue audio snippets or transcription jobs, not entire user sessions.
- Process in parallel where the model and data allow it.
- Design for retries and partial failure from the beginning.
They mixed off-the-shelf services with custom models instead of pretending one layer was enough
“To detect harmful speech, Modulate pairs the generative AI capabilities of large language models with bespoke audio analysis models.”
I like this because it’s honest engineering. Modulate didn’t claim a single model could understand everything in voice. They combined large language models with custom audio analysis because voice moderation needs both semantic understanding and signal-level analysis. That’s a much more believable approach than trying to force one tool to do all the work.
They also used Amazon Transcribe for speech-to-text, which is the kind of decision I’d expect from a team trying to ship a product instead of a research demo. Transcribe gives them a managed foundation, and the custom models handle the parts that are specific to their use case. That split matters. You don’t want to rebuild commodity speech recognition just to say you own the stack.
What this actually means is the architecture is modular enough to swap pieces without breaking everything else. If transcription improves, you can update that layer. If your harmful speech classifier needs tuning, you can adjust that layer. If a new use case needs fraud detection instead of toxicity detection, the pipeline stays familiar even if the model logic changes.
How to apply it: separate commodity functions from differentiated functions. Use managed services for the boring parts, then invest your own effort where your product actually wins. If you find yourself rebuilding transcription, queuing, or API plumbing from scratch, pause and ask why.
Reuse is where the real speed comes from
“We can tune our system for different use cases and redeploy the same architecture and services for our different products with relatively little development work.”
This sentence is basically the whole story. Modulate’s big advantage is not just that they can moderate games. It’s that they built a voice engine they can retarget. That’s why they could move from ToxMod to VoiceVault in two weeks and apply the same serverless architecture across gaming, rideshare, food delivery, financial services, insurance, and contact centers.
I’ve seen teams burn months rebuilding the same pipeline for every new vertical because they treated each product as a special snowflake. That gets old fast. Modulate seems to have made a better trade: build one repeatable event-driven core, then tune the models and business logic around it. That’s how you get faster go-to-market without turning the codebase into a landfill.
The case study also mentions Amazon SageMaker for building, training, and deploying ML and foundation models. That matters because model operations are part of the reuse story too. If your training and deployment flow is managed, you can spend more time on the product logic and less time on infrastructure glue. Again, not glamorous. Just useful.
How to apply it: identify the parts of your system that are truly domain-specific and the parts that are just plumbing. Standardize the plumbing. Keep the domain logic configurable. Then write the architecture so a new use case is mostly a new model, a new threshold, and a new customer workflow, not a new platform.
Template thinking beats one-off product thinking
What I really take from Modulate is that they didn’t build a single app. They built a template for voice intelligence. That’s why the architecture keeps showing up across products. That’s why the economics work. And that’s why the same system can support moderation today and fraud detection tomorrow.
The numbers in the case study are useful because they anchor the architecture in reality: up to 50 percent less toxicity exposure, 300 percent ROI for gaming studios, less than 40 seconds to analyze voice chats, and a 2-week path to market for VoiceVault. I’m not treating those as universal promises. I’m treating them as evidence that the stack is doing what it says on the tin.
If I were building this from scratch, I’d copy the shape, not the exact implementation. I’d keep the event-driven flow, the queue, the managed speech layer, the custom model layer, and the repeatable deployment pattern. I’d also keep the discipline of measuring cost per minute and latency per stage. That’s the part teams forget when they get excited about “AI voice intelligence.”
How to apply it: think in reusable pipelines, not isolated products. If a new use case can’t fit the same skeleton, ask whether the problem is actually different or whether your architecture is just too rigid.
The template you can copy
# Voice intelligence pipeline on AWS, modeled after Modulate's architecture
## Goal
Analyze voice snippets in near real time, classify harmful or fraudulent behavior, and return results fast enough to act on.
## Core services
- Amazon API Gateway for request intake
- AWS Lambda for event-driven processing
- Amazon SQS for buffering and parallel job handling
- Amazon Transcribe for speech-to-text
- Amazon SageMaker for custom model training and inference
- Optional: an LLM layer for semantic classification and summary
## Flow
1. Client uploads audio or sends a conversation event to API Gateway.
2. API Gateway validates the request and forwards it to Lambda.
3. Lambda creates a job record and places the job on SQS.
4. Worker Lambdas consume jobs from SQS in parallel.
5. Each worker:
- pulls the audio snippet
- sends it to Transcribe
- runs custom audio analysis
- optionally calls an LLM classifier
- writes the result to a datastore or webhook target
6. The system returns a moderation or fraud signal to the customer.
## Pseudocode
text
on_event(audio_event):
job_id = create_job(audio_event)
send_to_queue(job_id)
worker(job_id):
audio = fetch_audio(job_id)
transcript = transcribe(audio)
audio_signals = analyze_audio(audio)
text_signals = classify_text(transcript)
score = combine(audio_signals, text_signals)
store_result(job_id, score)
notify_customer(job_id, score)
## Design rules
- Keep each stage narrow and replaceable.
- Use queues anywhere latency can be traded for reliability.
- Process snippets, not full sessions, when possible.
- Measure cost per analyzed minute.
- Measure end-to-end latency from ingestion to decision.
- Make model thresholds configurable per customer or use case.
- Separate commodity tooling from proprietary logic.
## Suggested deployment shape
- API Gateway -> Lambda -> SQS -> Lambda workers -> Transcribe/SageMaker -> result store
- Add retries and dead-letter queues for failed jobs
- Add observability on queue depth, processing time, and classification confidence
- Keep the architecture identical across products; swap only model configs and business rules
## Configuration example
yaml
voice_intelligence:
max_latency_seconds: 40
processing_mode: async
queue: sqs
transcription: amazon_transcribe
model_runtime: sagemaker
classification_layers:
- audio_signal_model
- transcript_model
- llm_reasoning
routing:
game_moderation: toxmod
fraud_detection: voicevault
metrics:
- cost_per_minute
- p95_latency
- toxicity_exposure_reduction
- fraud_flag_precision
## What to copy first
- The queue-based job flow
- The split between transcription and custom analysis
- The reusable deployment pattern
- The latency and cost metrics
If you want the shortest possible version of the lesson, it’s this: build the voice pipeline once, make it event-driven, and keep it reusable enough that new products are mostly configuration. That’s what Modulate did, and that’s why the architecture feels like an actual business asset instead of a one-off demo.
My source was AWS’s case study at aws.amazon.com/solutions/case-studies/modulate-case-study/. I’ve rewritten the explanation in my own words and added the copy-ready template above; the product claims, service names, and quoted statements come from AWS and Modulate’s case study.
// Related Articles
- [TOOLS]
Grok 4.5 hits Cursor with $2/$6 pricing
- [TOOLS]
AGT turns agent calls into governed actions
- [TOOLS]
OpenClaw v2026.7.1 turns control UI into a workspace
- [TOOLS]
OpenAI’s screenless speaker turns ChatGPT into a companion
- [TOOLS]
SCALE turns CUDA code into portable GPU builds
- [TOOLS]
2027 AI/ML internship jobs are being tracked daily