n8n MCP 把工作流變工具庫
我拆 n8n MCP 的設定、差異與實作模板,讓你把工作流直接做成 AI 可呼叫的工具庫。

我把 n8n MCP 拆成一個可直接照抄的工作流工具庫做法。
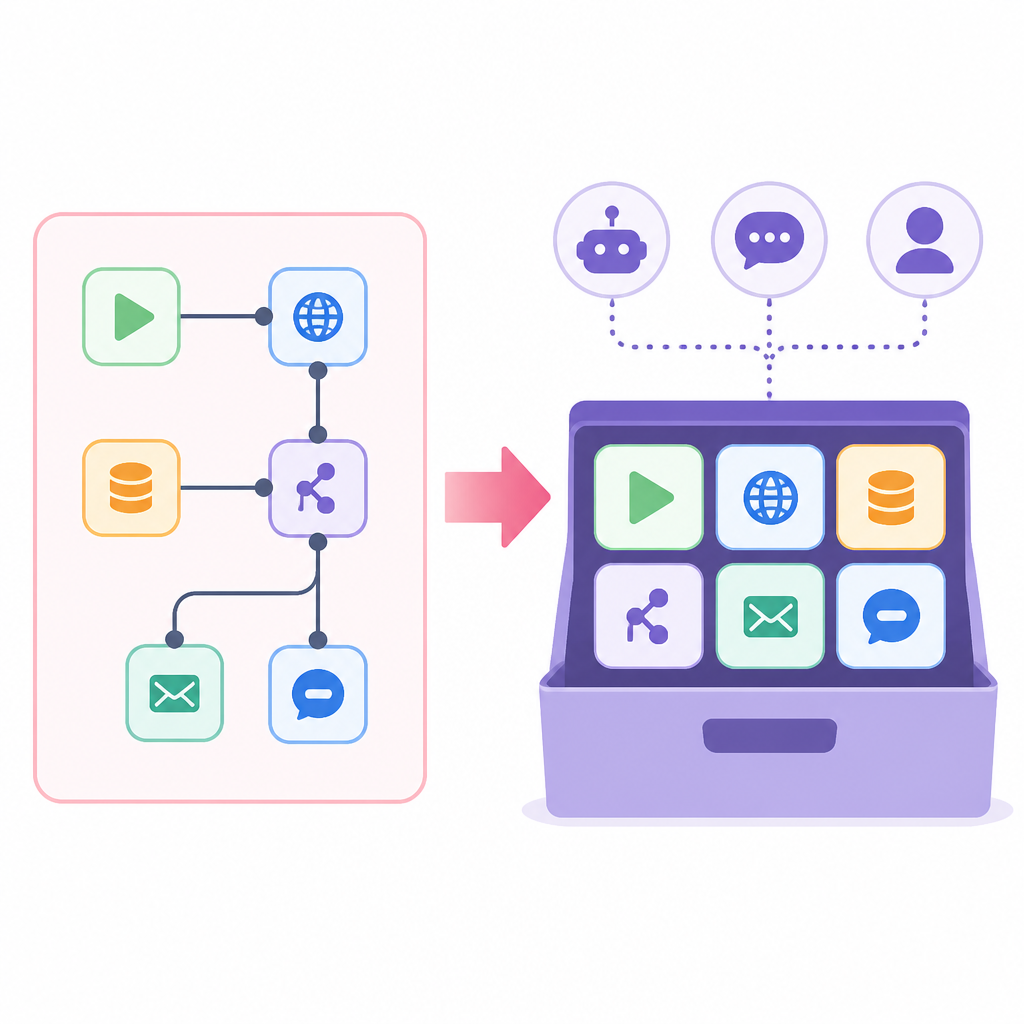
我用 n8n 一陣子了,越用越火大。流程是能跑沒錯,但一碰到 AI agent 要真的幫我做事,就開始露餡:不是要補自訂節點,就是要接一堆臨時 glue code,不然就是某個 HTTP node 一改參數整條線炸掉。更煩的是,當我只想多加一句「先查 CRM 再回覆」,整個 workflow 立刻變成一坨脆弱的分支地獄。能動,但很醜。
後來我看到這篇 Generect 的 n8n MCP 文章,才比較像被提醒到重點:n8n 不該只被當成自動化流程編輯器,它可以變成 AI 工具的入口。這不是在講「AI + automation 很棒」那種空話,而是把 workflow 重新定義成 agent 能直接呼叫的工具庫。這個角度,我覺得比文章本身寫得更值錢。
我真正想要的,是一種 setup:工具一次暴露好,MCP client 直接來叫,然後我不用每次都重寫同一套整合邏輯。文中也提到 n8n 已經有原生的 instance-level MCP server,Public Preview 從 2026 年 4 月開始,這點很重要,因為很多人只看過舊的 MCP Server Trigger,就以為 MCP 只能一條 workflow 一條 workflow 地接,完全漏掉更大的玩法。
別再把 n8n 當流程圖工具
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
“Updated June 2026: n8n now ships a native instance-level MCP server (Public Preview since April 2026) that lets Claude Desktop, ChatGPT, Cursor, or any MCP-compatible client build, test, and publish workflows directly inside your n8n instance — no JSON copy-paste.”
翻譯一下就是:n8n 不只是拿來串 trigger 和 action 的地方,它開始變成 AI 工具可以直接對話的表面層。這個心智模型差很多。以前大家把 n8n 當成 Zapier 變體,然後 AI 一進來就開始卡住,因為每個需求都要重新接線。MCP 的價值,就是給模型一個標準方式去問工具、拿 context、做動作,不用每次都客製一套。

我看過太多人把 n8n 用成「高級版流程圖」,結果 AI 一要加入就整個亂掉。MCP 改的不是某個節點,而是整個互動方式。模型不需要知道你內部怎麼接線,它只要知道能呼叫哪些工具就好。這樣 glue code 會少很多,維護也比較不會像在補破網。
我自己做內部 ops 自動化時,最常遇到的痛點就是:先做 lead enrichment,再做 validation,再做通知,前面都很順。可是一旦要讓 AI 自己判斷要不要先查另一個來源,整條流程就會長出一堆分支,而且每個分支都像在偷塞規則。MCP 比較像把這些能力整理成工具,而不是硬把所有邏輯塞進一條線裡。
實操寫法很簡單:先不要設計「一條完整 pipeline」,先問自己「這個 agent 應該能呼叫哪些工具?」這個問題一換,n8n 的設計方式就會變。你不是在排步驟,你是在設計工具面。
- 把 n8n 當 orchestration layer,不只是 task chaining。
- 把可重用的動作暴露成 MCP client 能呼叫的工具。
- 盡量讓 workflow 邏輯留在 n8n 裡,不要散到外部 script。
舊 trigger node 跟原生 server 根本不是同一件事
這篇原文把 MCP Server Trigger 跟新的 instance-level server 都講到了,這點我覺得很關鍵,因為它們解的是不同問題。前者比較像「把單一 workflow 包成工具端點」;後者則是整個 n8n instance 都能被 MCP-compatible client 看到。這兩個層級差很多,真的不能混在一起理解。
也就是說,舊模式是 workflow-centric,新模式是 instance-centric。我個人覺得後者更合理。workflow-level trigger 很適合 demo,也適合單一用途的工具。但只要你開始做真的內部工具,馬上就會想要一個集中管理的地方,讓 agent 可以發現能力,而不是你手動在三個地方各自註冊一次。
我自己最討厭的就是「把 workflow JSON 複製去別的地方貼上」這種流程,做過的人都知道那不是架構,那是 workaround。文章裡提到原生 server 不用 JSON copy-paste,我認為這不是小細節,這根本就是重點。少一層手動搬運,就少一堆 broken reference、credential 錯位,還有那種「為什麼它現在指到 staging」的經典災難。
實操寫法:如果你只是想測一個單一 automation 能不能被 MCP client 呼叫,就先用 trigger node。等你要把 n8n 當成多個 AI client 共用的 automation backend,再切到 instance-level server。自架的話,先確認版本與部署方式;原文提到 community edition 需要 v2.18.4+,而雲端或企業版則要對照 n8n hosting docs。
- Workflow trigger = 一條 workflow 暴露成工具。
- Instance server = 整個 n8n 工作區都能被 MCP 感知。
- 要用哪個,看你是 demo 還是系統。
先把安裝弄穩,別急著碰 AI
原文有把 n8n Cloud、Docker、npm 這幾條安裝路線都列出來。這段看起來很平,但其實很重要。自動化平台如果安裝就很煩,你後面只會更煩。文章也提到 self-hosted 會碰到像 N8N_EDITOR_BASE_URL 這種環境變數,這種東西平常沒人想管,直到 OAuth redirect 在半夜壞掉才開始後悔。
翻譯一下就是:MCP 不是獨立魔法,它是建立在一個已經正常運作的 n8n instance 上。如果你的 editor URL 不對、credential 沒整理好、外部 client 根本連不到,那你先別談 AI。先把底座弄穩,不然你只是在 debug 網路跟設定,不是在做 automation。
我看過團隊一開始就衝「AI agent integration」,結果連 workflow 權限跟存取都還沒穩。這順序完全反了。正確順序應該是:先讓 n8n 可達、可測、可重現,再把 MCP 疊上去。這樣你才知道壞掉的是哪一層,不會把所有問題都怪到模型身上。
實操寫法:先選一條安裝路線,不要今天 Cloud、明天 Docker、後天又想改 npm。你只要做到三件事就好:能打開 editor、能存 workflow、能跑一次 test execution。這三件事都穩了,再開始接 MCP。自架環境的話,把 base URL、webhook URL、auth method 放進同一份部署文件,別讓未來的你自己翻半天。
我會一起看的官方資源有這些:n8n docs、Model Context Protocol、Anthropic 的 MCP 文件。如果你想看 client 長什麼樣,Claude Desktop 跟 Cursor 都算常見起手式。
第一條 workflow 先做得無聊一點
Generect 那篇拿 Gmail 到 Slack 當例子,我覺得這選得不錯,因為它夠小、夠直觀,而且一眼就知道有沒有成功。這種大小很適合第一版。套到 MCP 也一樣,不要一開始就做一個什麼都會的 agent。先做一個工具、一個 client、一個結果,先把整條鏈路跑通。
也就是說,你第一條 MCP-backed workflow 要驗證的只有一件事:agent 能不能請求工具、n8n 能不能執行、結果能不能用乾淨的格式回來。就這樣。你如果一開始就想做全自動助理,最後只會花一堆時間在 prompt 行為上打轉,根本沒時間看整合到底哪裡壞。
我自己在做內部 lead routing 時也踩過這個坑。第一版超小:查 lead、驗 domain、送 Slack 通知。先把這三件事跑穩,後面再加 enrichment 和 scoring 就很順。第一版越無聊越好,因為無聊代表可重複,代表你真的有東西能維護。
實操寫法:選一條你本來就懂的 workflow,然後只暴露一個明確動作。如果你用的是 MCP Server Trigger,就把這條 workflow 當工具測一次;如果你用的是 instance-level server,就先註冊像「fetch lead status」或「create task」這種簡單能力。先把回傳格式弄乾淨,不要急著塞更多分支。
- 先挑你本來就熟的 workflow。
- 只暴露一個能回傳明確結果的 action。
- 先從 client 測通,再加其他分支。
工具設計比 prompt 花招重要
這段是很多新手文章最愛略過的地方。原文有講到更聰明的系統跟更好的 context,但真正的收益其實來自工具設計。MCP 不會把爛 workflow 變好,它只是給模型一扇標準入口。門後面如果很亂,模型還是得吃你的爛設計。
翻譯一下就是:每個暴露出去的 workflow 都應該只做一件窄而清楚的事。不要把一個工具做成「處理所有 CRM 任務」,那樣最後只會變成一個巨大 endpoint,測試超痛苦。比較好的做法是把 lookup、update、create 拆開,名稱用動詞,回傳結構化資料,少一點隱性副作用。
我會這麼兇,是因為我真的清過太多所謂的「AI-ready」workflow,結果本質只是把亂七八糟的 automation 用聊天介面包起來。模型能不能推理得好,前提是工具合約要清楚。MCP 可以幫忙,但它救不了糟糕的設計。
實操寫法:在你把 workflow 暴露成工具前,先寫清楚 input 跟 output。這個工具是讀資料還是寫資料,要講明白。只要它可能因為 credential 不見或欄位格式錯誤而失敗,就把失敗提早露出來,不要吞掉。這樣 agent 才真的能 debug。
我自己的規則很簡單:如果我沒辦法用一句話講完這條 workflow 在幹嘛,那它就太大了,不該直接暴露成工具。先拆,再說。
少寫 custom code,不代表不用做架構
原文很強調少 connector、快整合,這點我同意。但我也要補一個警告:少 connector 不等於不用架構。你還是得決定哪些事情放 n8n、哪些放 client、哪些該留在正常 API service。MCP 在中間,這很方便,可是也很容易變成大家亂丟東西的垃圾桶。
也就是說,n8n MCP 最適合的是 operational、repeatable、而且容易驗證的工作。它不是你整個 backend 的替代品。如果你本來就有一個很正常的 service 在處理 business logic,不要因為 workflow 編起來比較順手,就把它整個重寫成一百個 node。那樣只會讓系統更難維護。
我現在最順的做法,是把 n8n 當 orchestration layer,把 MCP 當 access layer。邏輯留在該留的地方,模型拿到的是乾淨的呼叫入口。這樣 workflow 還讀得懂,agent 行為也比較可預測。
實操寫法:只把那些「可操作、可重複、可驗證」的任務暴露給 MCP。核心 business rule 如果需要強測試、版本控管、複雜分支,就留在 code 裡。你不確定的話,就問自己:一個 junior teammate 只看 node 名稱,能不能安全跑這條流程?如果不能,先簡化再暴露。
我會優先放進 MCP 的類型有這些:
- Lead lookup 和 enrichment
- 跨系統狀態查詢
- Ticket 建立與 routing
- 有結構化輸出的通知流程
可抄的模板
# n8n MCP starter pattern for beginners
用在你想把一條 workflow 暴露成 AI client 可呼叫的工具時。
## 1) 先定義 workflow 形狀
- 只做一件事
- 只有一個清楚 input
- 只有一個結構化 output
- 除非必要,不要有隱性副作用
## 2) 在 n8n 建 workflow
- 打開你的 n8n instance
- 建立一條新 workflow
- 加上以下其中一種:
- `MCP Server Trigger`:單一 workflow 工具
- instance-level MCP server:如果你的 n8n 版本支援
- 把實際做事的 nodes 接進去
- node 名稱用動詞,而且要具體
## 3) 定義 tool contract
Input example:
{
"email": "[email protected]"
}
Output example:
{
"found": true,
"name": "Sam Lee",
"company": "Acme",
"status": "validated"
}
## 4) 從 MCP client 連進來
- 用 Claude Desktop、Cursor、ChatGPT,或其他 MCP-compatible client
- 指向你的 n8n MCP endpoint
- 先測一個最簡單的 request
## 5) 第一個工具要無聊
適合的第一批工具:
- 查一筆資料
- 驗證欄位
- 建立 ticket
- 發送通知
不適合的第一批工具:
- 什麼都做的 workflow
- 有多個副作用的流程
- 回傳一大坨不結構化文字的工具
## 6) 加 guardrails
- 每次執行都記錄
- credential 缺失就直接失敗
- 回傳結構化錯誤
- 讀取與寫入分成不同工具
## copyable checklist
- [ ] n8n instance 可連線
- [ ] credentials 已設定
- [ ] editor base URL 正確
- [ ] MCP endpoint 已曝光
- [ ] 至少一條 workflow 已端到端測通
- [ ] output 是結構化 JSON
- [ ] client 已能成功呼叫工具
## example tool naming
- `lookup_contact`
- `validate_domain`
- `create_support_ticket`
- `send_slack_alert`
## example prompt to test
"Look up the contact for [email protected] and return the result as structured data."
## next step
第一個工具穩了,再加第二個共享相同資料形狀的工具。
不要還沒穩就急著擴張。這段我是真的會直接貼進團隊文件。它把 scope 壓小,把工具合約講清楚,debug 面積也不會大到讓人想翻桌。如果你想讓 workflow 撐得住真實使用者,先從這裡開始。
最後補一句:這篇文章最有價值的地方,不是它寫得很適合新手,而是它把 workflow 往工具化的方向推了一步。n8n 加 MCP 的重點,不是「AI 可以接上自動化」,而是「自動化可以被 AI 以工具方式呼叫」。這個差別,我覺得值得你真的記住。
來源我拆的是 Generect 原文,再加上 n8n 官方文件、MCP 規格、Anthropic MCP 文件 做交叉整理。模板是我自己重寫的,概念與範例則是從這些來源延伸出來的。