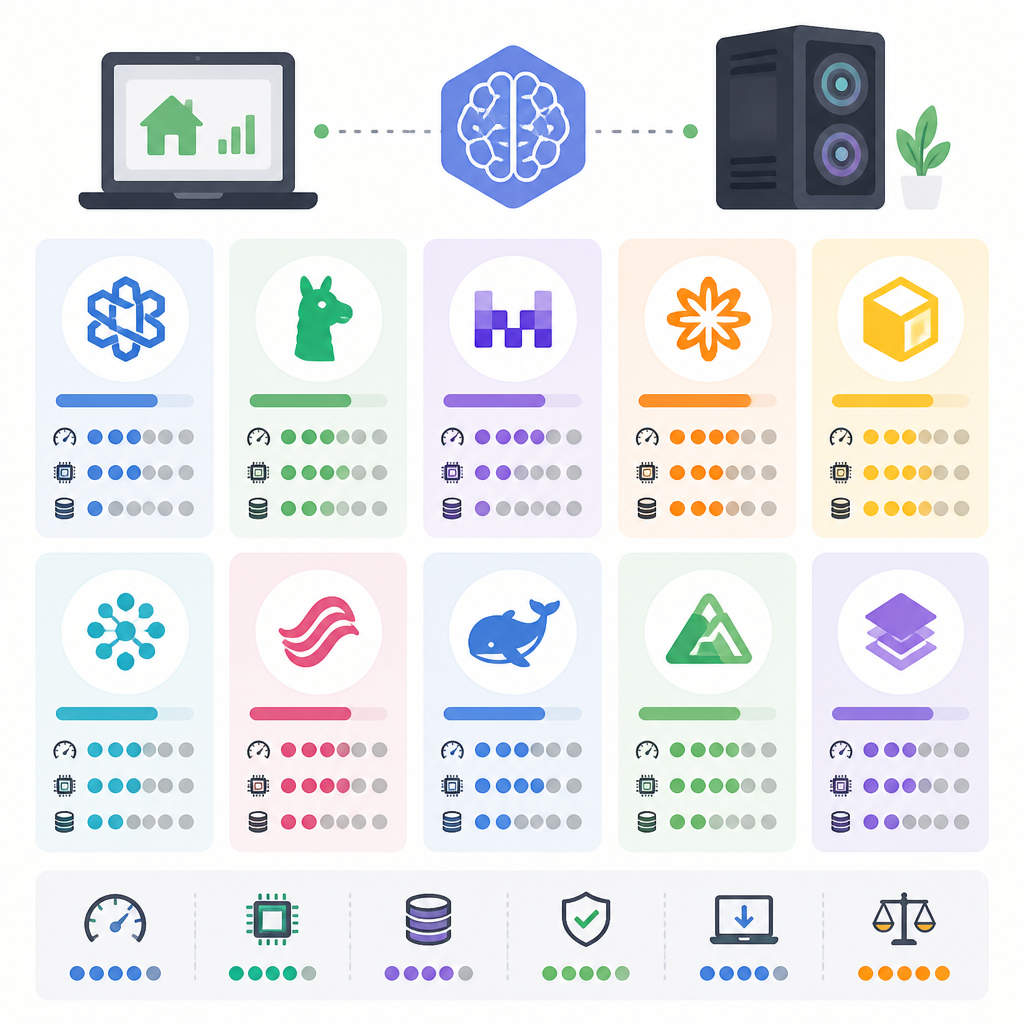
10 款可本地跑的開源 LLM,2026 這樣選
10 款可本地部署的開源 LLM,從 8GB 到 136GB VRAM 都有對應選擇,適合比對推理、寫程式、長上下文與代理任務。

這篇整理 10 款可本地執行的開源 LLM,幫你依硬體、上下文和任務類型挑出合適模型。
開源模型已不再只是備案。看完這 10 項,你可以快速決定:要選最強推理、最省顯存、最長上下文,還是最適合代理工作流的本地模型。
| 項目 | 強項 | 代表規格 | 典型 VRAM |
|---|---|---|---|
| Qwen 3 235B-A22B | 推理與寫程式 | LiveCodeBench 89%,SWE-Bench 40.0% | 約 132 GB Q4 |
| DeepSeek V4 Pro | 數學與技術工作 | GSM8K 96.0%,LiveCodeBench 93.5% | 約 136 GB Q4 |
| Kimi K2.6 | 長上下文流程 | 200 萬 token context window | 完整上下文需 80GB+ |
| GLM-5 / GLM-5.1 | Agentic AI | Tau2-Bench 89.7% | 64GB+ VRAM |
| Llama 3.3 70B | 單卡全能型 | MMLU 82%,HumanEval 86.0% | 約 40 GB Q4 |
1. Qwen 3 235B-A22B:整體最強的本地選擇
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
如果你只想選一個模型來扛推理、寫程式和長文工作,Qwen 3 235B-A22B 是最完整的答案。它的 MoE 設計每次只啟用 22B 參數,實際運算壓力比名義規模更可控。

代價是硬體門檻很高。約 132 GB VRAM 的 Q4 需求,代表它更像工作站或伺服器模型,而不是一般筆電能碰的選項。
- LiveCodeBench:89%
- SWE-Bench:40.0%
- 授權:Apache 2.0
- 適合:企業代理、複雜程式任務
2. DeepSeek V4 Pro:數學與技術推理更狠
DeepSeek V4 Pro 在數學和技術題上特別亮眼。96.0% 的 GSM8K 和 93.5% 的 LiveCodeBench,讓它成為重視正確率的工作流首選。
它同樣很吃資源,Q4 約 136 GB VRAM,加上 671B MoE 架構,明顯是多卡或企業等級硬體才有的配置。
- GSM8K:96.0%
- SWE-Bench:67.8%
- 授權:MIT
- 適合:數學、研究、競賽程式
3. Kimi K2.6:長上下文處理最有感
Kimi K2.6 的核心價值是 200 萬 token 上下文。這類模型不是拼單次回答,而是讓你能讀長文件、掃大型 codebase,或維持很長的對話脈絡。
它的成績比較偏實用面:LiveCodeBench 85%,SWE-rebench 43.8%,再加上 Apache 2.0 授權,部署彈性不錯。
- Context window:200 萬 token
- LiveCodeBench:85%
- 授權:Apache 2.0
- 適合:文件分析、多輪工作流
4. GLM-5 / GLM-5.1:做代理任務更對味
GLM-5 / GLM-5.1 比較像為 agent 設計的模型,重點是規劃、工具呼叫與多步驟執行。Tau2-Bench 89.7% 這類指標,正好說明它擅長完成任務鏈,而不只是聊天。
如果你要做自動化助理、流程編排或需要模型自己拆解步驟,這一組值得優先測。它同時有 89% 的 LiveCodeBench,程式能力也不弱。
- Tau2-Bench:89.7%
- Quality Index:49.64
- LiveCodeBench:89%
- 適合:代理、規劃、多步驟任務
5. Llama 3.3 70B:最實際的全能型
Llama 3.3 70B 是很多本地部署場景裡最平衡的選擇。生態成熟、工具支援多,搭配量化後,仍有機會在高階消費級硬體上跑起來。
82% 的 MMLU、86.0% 的 HumanEval,加上約 40 GB VRAM 的 Q4 需求,讓它落在「夠強、又不至於太難養」的甜蜜點。
- MMLU:82%
- HumanEval:86.0%
- VRAM:約 40 GB Q4
- 適合:通用用途、微調
6. Gemma 3 27B:中階硬體最均衡
Gemma 3 27B 很適合想要品質與成本平衡的人。它還支援 vision,對多模態工作有額外價值。
約 16 GB VRAM 的 Q4 需求,對單卡桌機或 MacBook Pro M4 Max 這類設備都更現實。MMLU 約 78.6%,HumanEval 87.8%,整體非常均衡。
- MMLU:約 78.6%
- HumanEval:87.8%
- 多模態:支援
- 適合:單卡部署、影像任務
7. Mistral Small 3.1 24B:16GB 顯存的務實解
Mistral Small 3.1 24B 的定位很清楚:在 16 GB VRAM 內,盡量保留長上下文與穩定指令遵循。它不是最大,但很實用。
128K context 搭配約 16 GB Q4,讓它很適合 RAG、客服機器人和文件型應用。若你要的是穩定落地,而不是榜單最前面,這款很值得試。
- Context window:128K token
- VRAM:約 16 GB Q4
- 授權:Apache 2.0
- 適合:RAG、長文件
8. Phi-4 14B:小模型裡的推理效率派
Phi-4 14B 的優勢是小而聰明。對於在意推理效率,而不是單純追求參數量的人,它很有吸引力。
約 8 到 10 GB VRAM 的 Q4 需求,讓它能進入邊緣裝置、較小桌機,甚至商業產品。MIT 授權也讓商用整合更單純。
- 模型大小:14B
- VRAM:約 8-10 GB Q4
- 授權:MIT
- 適合:邊緣部署、商業應用
9. MiMo-V2.5-Pro:代理式寫程式與雙語工作
MiMo-V2.5-Pro 偏向 agentic coding,重點是長鏈任務與自動化流程。它不是最容易量化比較的那種模型,但方向很明確。
如果你的場景包含中英雙語、程式輔助或任務拆解,這款值得放進測試清單。它更像專長型工具,而不是萬用型聊天模型。
- 焦點:agentic coding
- 強項:長鏈推理
- 授權:open weight
- 適合:自動化、雙語流程
10. MiniMax M2.7:多模態輸入最完整
MiniMax M2.7 支援文字、影像與音訊,適合處理不只文字的工作。當你的產品需要跨媒體理解時,這種能力比單一榜單分數更重要。
它的 SWE-rebench 為 39.6%,而且建議 64GB+,所以不是輕量選項。若你要做創作工具、豐富助理或高階多模態系統,它比較對路。
- 多模態:文字、影像、音訊
- SWE-rebench:39.6%
- VRAM:建議 64GB+
- 適合:創作與多模態應用
怎麼挑:先看硬體,再看任務
如果你要的是整體最強,而且硬體足夠,先看 Qwen 3 235B-A22B;如果偏數學與技術推理,DeepSeek V4 Pro 更合適;如果你常處理超長文件,Kimi K2.6 最直接。
多數人更實際的起點會是 Llama 3.3 70B、Gemma 3 27B 或 Mistral Small 3.1 24B。要做代理,選 GLM-5.1;要小型商用部署,Phi-4 14B 最省心。