PixelRAG 把截圖變可檢索上下文
拆解 PixelRAG 的截圖優先 RAG 流程,順手給你一份可直接抄去做視覺檢索的模板。

PixelRAG 把頁面截圖變成可檢索的 RAG 上下文。
我做 RAG 做到一個程度後,最怕的不是答錯,是它答得太像對的。你丟進去一頁有表格、有圖、有標註的文件,它很勤勞地把文字切碎、塞進向量庫,然後回你一段看起來很完整的答案。只是那個答案常常把版面、圖例、欄位關係全弄丟,最後變成「語氣很穩,內容很虛」。我以前一直以為是模型不夠強,後來才發現,很多時候是我們先把文件弄壞了。
這件事卡我很久。純文字抽取很方便,沒錯,但它把人類讀頁面時靠的東西都削掉了:排版、間距、圖和說明文字的相對位置、表格欄列的對應、甚至一個標題到底是在解釋上面那張圖還是下面那段字。RAG 團隊很愛說「先切 chunk 再說」,但我看過太多系統是在用殘片拼答案,拼到最後還覺得自己很聰明。
PixelRAG 給我的第一個感覺很直接:它承認頁面就是頁面,不是硬要變成文字 blob。它走的是 screenshot tiles、vision-language embeddings、以及對影像做檢索的路線。這聽起來不複雜,但你真的試過拿一份密密麻麻的文件問模型,它還要保留視覺結構時,就知道這件事沒那麼簡單。
我會特別想拆它,是因為它不是那種包裝很漂亮、底層卻很空的 demo。它是開源的,管線有,預建索引有,甚至還有不用 API key 就能打的 hosted API。這種東西不常見,我不拆一下對不起自己。以下我主要參考 EveryDev.ai 上的 PixelRAG 條目,它連到 Berkeley SkyLab、BAIR 和 Berkeley NLP Group 的原始工作;我不是在重述宣傳話術,我是在翻成你真的能拿去做的版本。
別再假裝文字就是整份文件
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
PixelRAG is a pixel-native retrieval pipeline that replaces text chunking with screenshot-based embedding.
翻譯一下就是:它不把文件先拆成文字 chunk 再硬找答案,而是先把頁面渲染成 screenshot tiles,直接把這些視覺區塊拿去做索引。檢索單位變成影像,不是字串。這差很多,因為表格不是把字排成列而已,圖表也不是把標籤散在空中而已;視覺關係本身就帶資訊。

我之前在內部文件上碰過同樣的坑。工程圖、架構圖、流程圖這些東西,一旦被抽成純文字,模型常常只抓到旁邊的說明段落,真正決定意思的那張圖卻沒進來。答案看起來很順,直到懂系統的人一看就知道它在瞎掰。這種錯不是「差一點」,是整個資訊通道選錯了。
PixelRAG 的核心判斷很硬:視覺結構不是裝飾,它就是答案的一部分。這跟一般 RAG 那種「先把所有東西扁平化,然後再想辦法補救」的習慣完全相反。我反而覺得這種反骨很務實,因為它不是在追求聰明,是在避免愚蠢。
實操上我會這樣做:如果你的語料有截圖、投影片、儀表板、PDF、或版面很重的 web docs,先別急著全丟 text-only pipeline。先把問題拆成兩類:哪些內容應該讀文字,哪些內容應該讀圖。只要答案仰賴版面,你就該保留視覺形式進檢索流程。
- 版面會改變語意的內容,用 screenshot tiles。
- 純敘述型文件,文字抽取還是可以保留。
- 不要把兩種資料混成一鍋,最後只會得到很黏的索引。
我覺得這裡最重要的不是「vision 比較強」這種空話,而是檢索應該保留真正承載答案的資訊通道。對某些文件來說,那個通道就是 pixels。你硬把它壓成字,等於先把答案拆掉一半。
管線故意做得很普通,我反而放心
PixelRAG 的管線我看完是有點爽,因為它沒把自己包成一個神祕大盒子。源頁面描述的四段很清楚:render、embed、index、serve。render 用 Playwright CDP 或 PDF 工具,embed 用 Qwen3-VL-Embedding,index 用 FAISS,serve 則是 FastAPI。這種組合不炫,但它可拆、可看、可換,我比較信。
白話講,這代表每個失敗點都能單獨抓出來看。檢索不準,你可以回頭看是不是 render 把頁面弄爛了,還是 embedding 沒抓到視覺 cue,或是 index 切得太粗。我受夠那種所有東西揉在一起的系統,壞了之後整條鏈都像黑箱,debug 起來像在拜神。
另外它把各階段拆成可安裝的元件,這點我很認同。條目裡提到像 pixelshot 這種渲染工具,以及 pixelrag chunk / embed / build-index、pixelrag serve 這種命令,表示你可以先測一段,再決定要不要接整套。這比一開始就把所有東西塞進單一服務好多了。
實操寫法很簡單:你自己做 visual RAG,也別把流程弄成一坨。render、embed、index、API 分開放,腳本分開跑,參數分開管。這樣你才知道問題是出在渲染、模型、索引,還是服務層。寧可 setup 長一點,也不要最後變成一個誰都不敢碰的黑盒子。
- 先 render,再人工看 tiles 有沒有被切壞。
- embedding 模型和版本要 pin 住,不然結果會飄。
- 搜尋 API 只做薄薄一層,不要把所有邏輯都塞進去。
這種普通,反而是它的價值。可 debug 的系統,才有資格碰 production 資料。
為什麼 screenshot tile 比 brittle parsing 靠譜
Text extraction discards layout, tables, figures, and styling — signals that make a page legible and answerable.
也就是說,文字抽取會把版面、表格、圖、樣式這些讓頁面「可讀」也「可答」的訊號丟掉。這句話我認同,而且我覺得它幾乎就是整個問題的核心。你把頁面 parse 成純文字,其實是在假設語意會完整穿過轉換。很多時候會,但很多時候不會,尤其當那頁面本來就不是一段乾淨的文章,而是表格、圖說、比較欄、流程圖混在一起的東西。
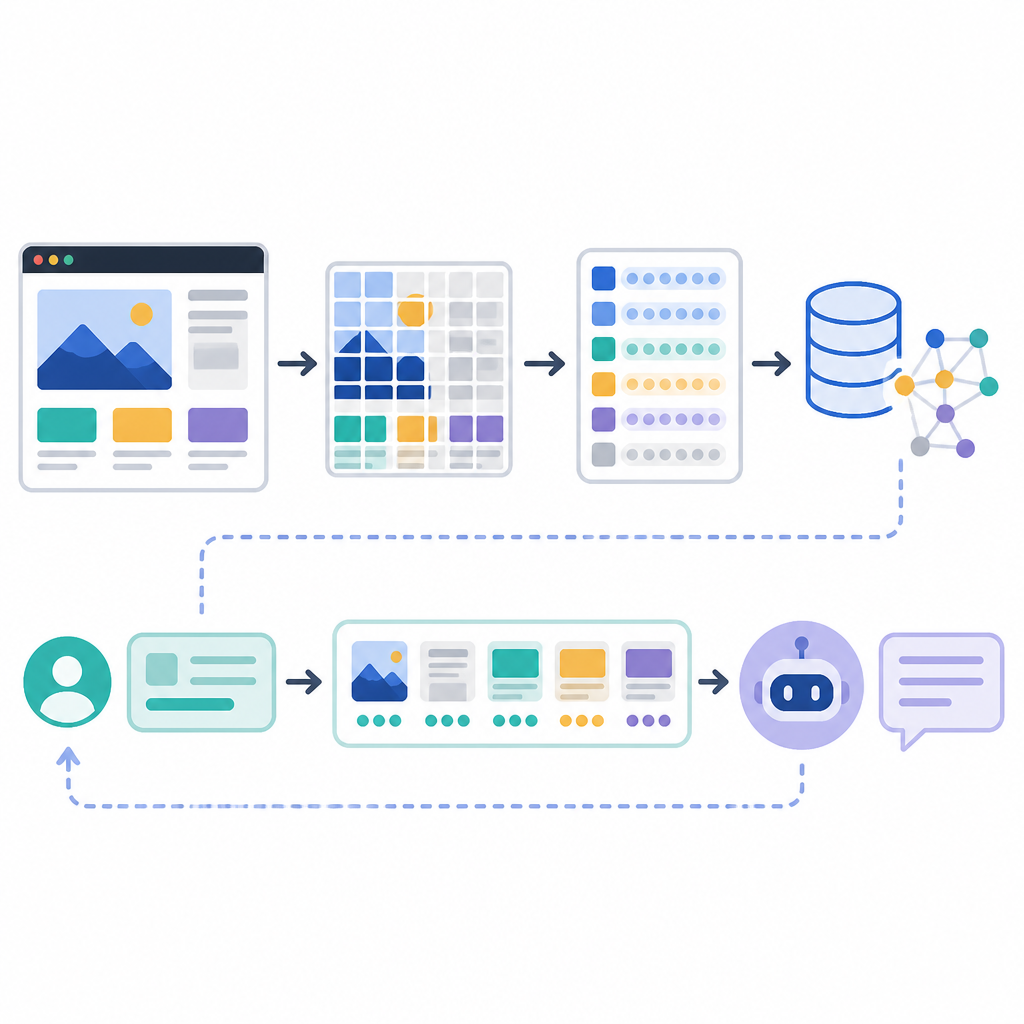
條目裡說 PixelRAG 把 screenshot 索引到向量空間,讓表格、圖表、排版、資訊圖都能保持完整並可搜尋。這句如果我要跟團隊講,我會直接劃線。因為大家最常卡住的問題就是:「明明答案就在那頁,為什麼模型就是沒抓到?」
我以前在財報、架構文件、產品規格上都碰過。真正的答案常常藏在表頭、圖例、左右對照欄,或者某個小字註解裡。文字 chunking 很容易把這些 cue 跟它解釋的內容切開。最後檢索回來的是錯的 chunk,生成器再自己腦補,答案就變成一個很像真的故事。
實操上,我會先把語料按視覺密度分級。API reference 這種乾淨的文件可以先 text-first;dashboard 截圖、onboarding flow、研究論文圖表就別硬壓成文字。先挑一小批視覺密度高的頁面做 hybrid benchmark,看 screenshot retrieval 的 top-k relevance 有沒有真的比較好。
這裡還有一個對 prompt 工程的提醒:如果答案依賴視覺排列,不要叫模型從抽出來的文字去猜排列。你要把排列本身給它,不然你等於拿一張爛影印本叫它復原原稿。那不是推理,那是折磨模型。
預建索引其實才是最會打中的地方
我覺得 PixelRAG 最聰明的地方,不是它的論文敘事,而是它沒有逼你從零開始。條目寫得很明白:hosted public API 已經索引了 8.28M Wikipedia articles、28.1M screenshot tiles,而且不用 API key 就能打。這種設計很會,因為它直接讓你測視覺檢索到底是不是你要的東西。
白話講,你不用先花半天做一個 toy index,才去回答「這玩意到底有沒有用」。那種前置摩擦最容易把團隊熱情磨掉。只要能先試、先問、先比,你才知道它是不是值得接進自己的資料管線。
條目也提到它在 Hugging Face 上有 pre-built FAISS indexes 和 LoRA adapter weights,加上完整 pipeline source。這種組合的好處是,它不是只有概念,而是你真的可以下載、看、改、跑。我很吃這套,因為我不想只看一個漂亮 demo,我想知道它怎麼壞、怎麼修。
實操寫法是這樣:先把 hosted endpoint 當 benchmark,不要當依賴。拿文字 query、圖片 query、混合 query 去打,特別測那些靠版面才答得出來的問題。再跟你現在的 text RAG 比一次。如果 visual 版本真的比較容易找到對的頁或 tile,你就有證據,不是靠感覺。
如果你要 self-host,別忽略成本。條目提到這份 Wikipedia index 有 214 GB FAISS data、2048-dimensional embeddings。這不是小東西。你要把它當成基礎設施決策來算,不然很容易前面想得很美,後面硬碟跟記憶體先爆。
Claude plugin 那段,我會第一個偷來用
The repository includes a Claude Code plugin called pixelbrowse that gives Claude the ability to screenshot any URL and read the resulting image rather than fetching raw HTML.
翻成白話就是,這個 plugin 讓 Claude 先看截圖,而不是傻傻抓 raw HTML。這對 agent 工作很實際,因為很多網站的 DOM 根本不是使用者看到的東西。表格、圖表、浮動元件、側欄、卡片排版,這些都不是純 HTML scraping 能漂亮處理的。
我喜歡這個設計,因為它很直接地解決一個老問題:網頁很髒,DOM 常常是很爛的代理。agent 如果任務是「看懂這頁」,那 screenshot 往往比 source code 更接近真實世界。這不是哲學,是少犯蠢。
條目還說 pixelbrowse 會呼叫本地 pixelshot CLI,不需要 MCP server 或後端。這點我也覺得實用,因為它把 browser-read 路徑維持得很輕,不必先把整個 agent 架構重做一遍。你可以把它塞進現有 tool-use 流程,先讓模型多一個「看圖」能力。
實操上,如果你在做 browser-capable agent,我會建議先加 screenshot-read tool,再加更多 scraping 邏輯。先拿它去處理 dashboard、docs、admin UI 這種視覺導向頁面,再跟 HTML-only 的成功率比一次。我猜很多團隊會發現,視覺路徑其實贏不少。
- dashboard、文件、後台介面,用 screenshot tool。
- form fields、metadata、結構化欄位,保留 HTML scraping。
- 讓 agent 自己選視圖,不要你先替它鎖死。
很多時候,工具比模型更重要。你給對表示法,模型就少一半要硬猜的事。
自架能不能活,才是真考驗
EveryDev 條目寫 PixelRAG 能跑在 Linux + CUDA、macOS + Apple Silicon/MPS,甚至還有 CPU fallback。這點我很在意,因為很多 AI 開源專案嘴上說 open source,實際上只有特定 GPU 才能活,其他人看了都只是陪跑。
白話講,這代表它真的有想讓一般開發者接得上。條目也提到它用簡單 YAML config 就能從本地文件或 PDF 建自訂索引。這才是 self-hosted 工具該有的樣子:一個 config、一個 source directory、一條 pipeline。
訓練部分還另外拆成 train/ 專案,依賴也有 pin,像 Torch 和 cuDNN 版本都分開處理。我反而放心,因為訓練環境最容易死在版本地獄裡。把訓練和推理拆開,是有經驗的人才會做的事。
實操上,如果你要把 PixelRAG 改成自己的語料,先從一個小目錄開始,不要一開始就把整個 doc lake 丟進去。先挑 20 到 50 頁代表性文件,驗證 render、embedding、retrieval 這條鏈是不是正常。先小規模證明,再放大,不然你只是在把問題搬大。
另外,視覺索引的成本要算進去。screenshot tiles 比 text chunks 重很多,這是代價。你是在用儲存和 embedding 成本,換回文字抽取會弄丟的語意。有些領域這筆帳非常划算,但你得先承認它真的有成本。
我會直接抄的模板
# PixelRAG-style visual RAG template
## When to use
Use this for corpora where layout matters:
- tables
- charts
- diagrams
- PDFs with dense formatting
- web pages where visual placement changes meaning
## Pipeline
1. Render each page into screenshot tiles.
2. Embed tiles with a vision-language embedding model.
3. Store vectors in FAISS.
4. Serve retrieval through a thin HTTP API.
5. Optionally add a browser screenshot tool for agents.
## Minimal config
source_dir: ./docs
output_dir: ./pixelrag-out
render:
engine: playwright-cdp
tile_width: 1280
tile_height: 1600
embed:
model: Qwen3-VL-Embedding
batch_size: 16
index:
type: faiss_ivf
dim: 2048
serve:
host: 0.0.0.0
port: 8000
## Query strategy
- text query: for semantic lookup
- image query: for visual similarity
- hybrid query: for questions that mention both content and layout
## Retrieval policy
- return top-k tiles
- include source page URL or file path
- include tile coordinates
- include thumbnail or rendered preview in the UI
## Agent tool shape
{
"name": "pixelbrowse",
"description": "Screenshot a URL and search the page visually",
"input_schema": {
"type": "object",
"properties": {
"url": { "type": "string" },
"query": { "type": "string" },
"mode": { "type": "string", "enum": ["text", "image", "hybrid"] }
},
"required": ["url", "query"]
}
}
## Build checklist
- [ ] render sample pages and inspect tiles manually
- [ ] verify tables and figures survive rendering
- [ ] benchmark against text-only RAG
- [ ] pin model and FAISS versions
- [ ] test text, image, and hybrid queries
- [ ] expose a simple API before adding agent complexity
## Practical rule
If the answer depends on what the page looks like, keep the page as an image in the retrieval path.
If the answer depends only on prose, text chunking is fine.
Don’t force one representation to do both jobs badly.這段我故意寫得很平,不是為了好看,是為了你真的可以直接貼進 repo。重點不是把它當成一篇文章的裝飾,而是把它當成你自己的起手式。你要改的只有 corpus、模型、索引大小,還有你到底要不要讓 agent 看圖。
我對 PixelRAG 的結論很簡單:它不是想把 RAG 變神,它只是想阻止 RAG 對那些本來就不該被扁平化的文件亂來。這個目標比很多花俏說法誠實多了,也實際多了。
來源致謝:主要根據 https://www.everydev.ai/tools/pixelrag 與其連結到的原始專案資訊整理;我寫的部分是方法拆解、實作建議和可抄模板。相關工具與專案連結也可參考 FAISS、FastAPI、Hugging Face、Qwen3-VL-Embedding。