PreRL: Training LLMs in pre-train space
PreRL shifts reinforcement learning from P(y|x) to P(y), using reward-driven updates in pre-train space to improve reasoning and exploration.

Reinforcement learning with verifiable rewards has become a useful way to improve LLM reasoning, but this paper argues it is still constrained by the base model’s existing output distribution. The authors propose a different target: instead of optimizing only the conditional distribution for a prompt, optimize the marginal distribution in pre-train space. You can read the paper, From $P(y|x)$ to $P(y)$: Investigating Reinforcement Learning in Pre-train Space, as an attempt to move reasoning improvement one layer earlier in the training stack.
In plain English, the idea is to stop treating reasoning as only a prompt-conditioned behavior and start shaping the model’s broader generation space directly. That matters for engineers because it changes where learning pressure is applied: not just “answer this prompt better,” but “reshape the model so correct reasoning becomes more reachable in general.”
What problem this paper is trying to fix
The paper starts from a specific limitation of RL with verifiable rewards, or RLVR. RLVR improves large language model reasoning by optimizing P(y|x), the probability of an output y given an input x. But the authors argue that this still depends on what the base model already knows how to produce. If the model’s output distribution is narrow or biased toward unhelpful trajectories, RLVR can only push so far.
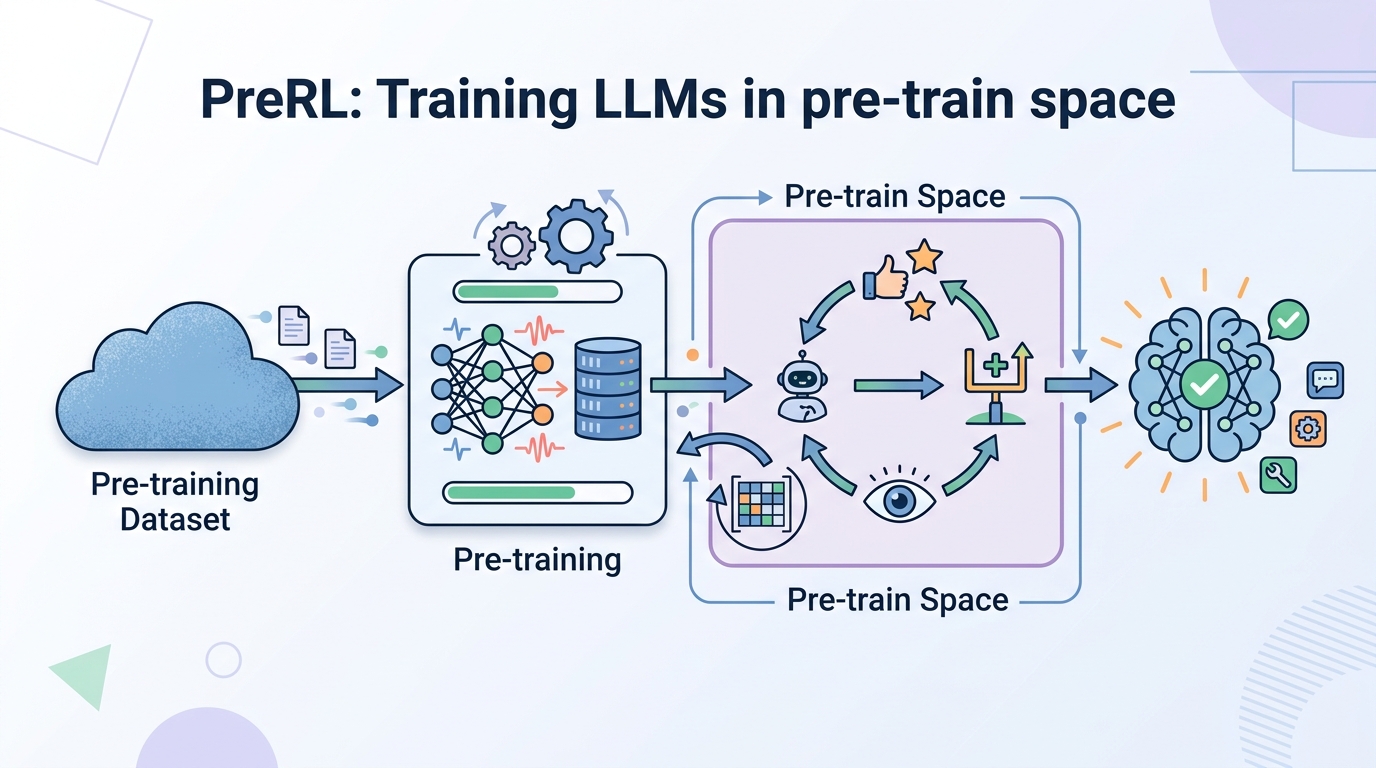
The proposed fix is to optimize P(y) instead, in what the paper calls the “Pre-train Space.” The intuition is that the marginal distribution can encode reasoning ability while preserving broader exploration capacity. That is a meaningful distinction: conditional optimization can reward the right answer for the right prompt, while marginal optimization aims to make the model’s overall generative landscape more reasoning-friendly.
The authors also point out another issue with conventional pre-training: it relies on static corpora and passive learning. In their framing, that creates a distribution shift when the goal is targeted reasoning enhancement. So the paper is not just proposing another RL recipe; it is arguing that the training regime itself should be more direct, more online, and more reward-driven.
How PreRL works in plain English
The method introduced here is called PreRL, short for Pre-train Space RL. The core move is simple: apply reward-driven online updates directly to P(y) rather than only to P(y|x). That means the model is updated in a way that is meant to improve the general space of possible outputs, not only prompt-specific behavior.
The paper says it both theoretically and empirically validates strong gradient alignment between log P(y) and log P(y|x). In practical terms, the authors are trying to show that optimizing the marginal distribution can act as a viable surrogate for standard RL. That alignment claim is important because it is what makes the approach plausible: if the gradients point in similar directions, then improving one space can help the other.
A key mechanism in the paper is Negative Sample Reinforcement, or NSR. The authors describe NSR as an especially effective driver for reasoning inside PreRL. The idea is to reinforce learning from negative samples so the model rapidly prunes incorrect reasoning paths while encouraging internal reflective behavior. This is not framed as a generic “more data helps” story; it is specifically about using negative examples to reshape the reasoning search space.
The paper also introduces Dual Space RL, or DSRL, which the authors describe as a Policy Reincarnation strategy. In this setup, models are first initialized with NSR-PreRL to expand the reasoning horizon, and then transitioned to standard RL for finer optimization. That two-stage design suggests the authors see pre-train-space pruning as a way to prepare the policy before conventional RL takes over.
What the paper actually shows
The abstract says the authors provide both theoretical and empirical validation for the gradient alignment between log P(y) and log P(y|x). It also says extensive experiments show that DSRL consistently outperforms strong baselines. Those are the main outcome claims available in the source.
The paper includes one concrete set of behavioral measurements tied to NSR-PreRL: it increases transition thoughts by 14.89x and reflection thoughts by 6.54x. The authors use those numbers to support the claim that NSR rapidly prunes incorrect reasoning spaces while stimulating endogenous reflective behaviors. That is the clearest quantitative signal in the abstract.
What the abstract does not include is benchmark-by-benchmark detail. There are no task names, no exact scores, and no full evaluation table in the source material here, so those specifics should not be assumed. The safe takeaway is that the method is reported to outperform strong baselines, but the abstract alone does not let us inspect where, by how much, or on which datasets.
That limitation matters if you are evaluating whether this is ready to influence a production training pipeline. The paper’s main evidence, as provided here, is conceptual plus aggregate experimental success, not a fully transparent benchmark breakdown. So the claims are promising, but the source excerpt does not let us independently judge robustness across tasks or model sizes.
Why developers should care
If you build or tune LLM systems, this paper is interesting because it reframes reinforcement learning as a problem of shaping the model’s generative prior, not just correcting prompt-level behavior. That could matter for reasoning-heavy applications where the model needs to explore better intermediate steps, not merely land on a correct final answer.
The NSR result is especially practical in spirit. A lot of training pipelines focus on positive supervision or reward signals for correct outputs. This paper argues that negative samples can do more than just penalize mistakes: they can actively carve away bad reasoning regions and encourage reflective trajectories. For teams working on reasoning traces, self-correction, or search-like generation, that is a useful design idea even before you adopt the full method.
The DSRL strategy also suggests a broader engineering pattern: use a coarse-to-fine training schedule. First expand the reasoning space with pre-train-space reinforcement, then switch to standard RL for refinement. That kind of staged optimization may be easier to reason about than trying to solve everything with one RL objective.
- PreRL targets the marginal output distribution
P(y)instead of onlyP(y|x). - NSR-PreRL is presented as a strong mechanism for pruning incorrect reasoning paths.
- DSRL combines pre-train-space pruning with standard RL in two stages.
- The abstract reports 14.89x more transition thoughts and 6.54x more reflection thoughts under NSR-PreRL.
- No benchmark table or exact task scores are included in the source excerpt.
Limitations and open questions
The biggest limitation is that the source material is still abstract-level. It tells us the direction of the results, but not enough to assess failure modes, compute cost, training stability, or sensitivity to model scale. It also does not explain how broadly the gradient alignment claim holds across architectures or domains.
There is also an unresolved practical question around deployment. Optimizing P(y) in pre-train space sounds powerful, but it may be harder to integrate into existing RLHF or RLVR pipelines than a standard reward model loop. The paper positions PreRL as a surrogate for standard RL, but the abstract does not give enough implementation detail to know how invasive the change is.
Still, the core idea is clear: if reasoning quality is partly limited by the model’s underlying output space, then training only at the prompt-response level may leave gains on the table. This paper argues for a more structural approach, and its DSRL recipe is a concrete attempt to combine broad exploration with targeted optimization.
For developers, the practical lesson is not “replace your current RL stack tomorrow.” It is more nuanced: if your model struggles with reasoning depth, reflective steps, or search diversity, it may be worth thinking about where the training signal is applied. PreRL suggests that some of the best gains may come from reshaping the model’s space of possible answers before you ask it to specialize.
Related Articles

LLMs plus knowledge graphs for ML explainability
Apr 20

Autoencoders for stochastic dynamics get geometric regularization
Apr 20

ASMR-Bench Tests Sabotage Detection in ML Code
Apr 20

OpenAI pushes GPT-5.4-Cyber into security work
Apr 19

Stanford’s 2026 AI Index, explained with charts
Apr 17

How to Trust LLM Judges, Per Input
Apr 17