Vector Lakebase makes Milvus a full AI data platform
5 ways Zilliz Vector Lakebase unifies serving, discovery, and batch analytics on one data foundation for AI teams.

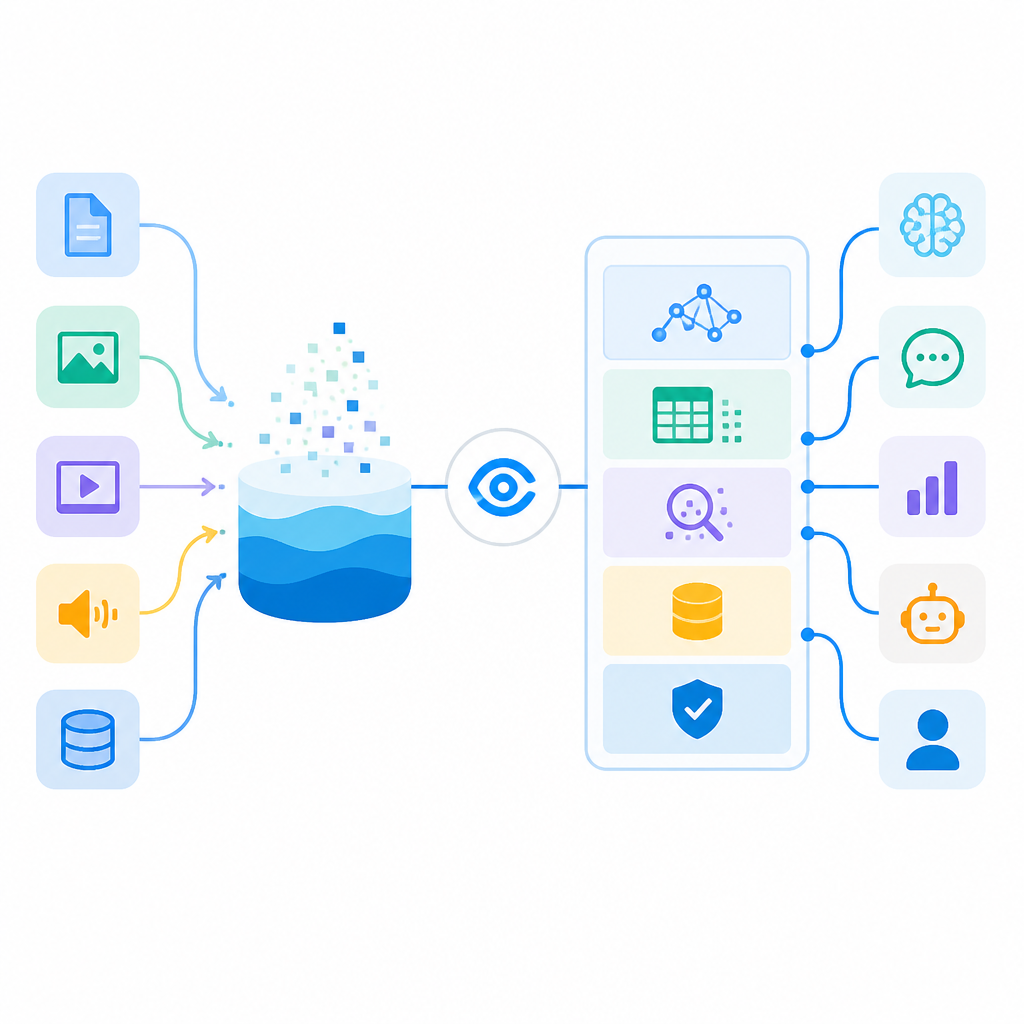
Zilliz Vector Lakebase unifies vector search, discovery, and batch analytics on one data foundation for AI.
Zilliz says its new public preview gives AI teams one place to serve, explore, and process vector data, with tiered performance options and pay-as-you-go compute. The launch builds on Milvus, which Zilliz says is used by more than 10,000 enterprises and AI teams.
| Item | Latency | QPS | Recall | Storage / Compute model |
|---|---|---|---|---|
| Performance-Optimized | Single-digit ms | 1,000+ | 95-98%, tunable to 99%+ | In-memory |
| Capacity-Optimized | Sub-100ms | 100-500 | 95-98%, tunable to 99%+ | Memory + NVMe |
| Tiered-Storage | ~100ms | 10-50 | 95-98%, tunable to 99%+ | Memory + NVMe + object storage |
| On-Demand Search | Workload-dependent | Workload-dependent | Not specified | Pay only when compute is active |
1. Tiered Real-Time Serving
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The core of Vector Lakebase is still production vector search, but Zilliz now packages it in three serving tiers so teams can match cost to workload. That matters because not every AI app needs the same latency or memory footprint.

For teams building agent memory, retrieval-augmented generation, or user-facing semantic search, the tier choice is a practical one: spend for speed when queries are hot, or move down a tier when traffic is steadier.
- Performance-Optimized: 1,000+ QPS, single-digit-millisecond latency
- Capacity-Optimized: 100-500 QPS, sub-100ms latency
- Tiered-Storage: 10-50 QPS, about 100ms latency
2. Zero-Copy Semantic Data Plane
Zilliz is pitching Vector Lakebase as a way to stop moving billions of vectors between separate systems. Instead of copying data for serving, exploration, and analytics, all three run against one logical copy on shared lake-native storage.
That design is meant to reduce the days-long shuffle that often slows model improvement loops. In Zilliz’s framing, the same data can answer a production query, support a discovery session, and feed a training-data pipeline without migration overhead.
- One logical copy of the data
- Shared lake-native storage
- Designed for gigabytes to petabytes
3. On-Demand Search
On-Demand Search is the cost-control piece of the release. Zilliz says teams can run search directly on external data lakes and pay only for object storage and active compute, instead of keeping infrastructure warm for idle periods.
That is useful for bursty workloads such as offline enrichment, one-off investigations, or periodic batch jobs. It also gives teams a way to keep data where it already lives while still querying it through the same platform.
Use cases: ad hoc semantic search, overnight deduplication, periodic embedding refresh, lake queries without data copies4. Interactive Discovery
Interactive Discovery is the middle ground between production serving and offline analytics. Zilliz describes it as a way to inspect and mine vector data in a more exploratory mode, without pulling it into a separate stack first.
This matters for data scientists and ML engineers who need to test hypotheses quickly. If a team wants to inspect clusters, compare retrieval behavior, or find weak labels before a model retrain, discovery can happen on the same foundation as serving.
- Fits interactive analysis sessions
- Works on the same data as production search
- Reduces handoff between analytics and serving teams
5. Batch Analytics for the Feedback Loop
Zilliz frames AI systems as a loop: serve, learn, improve data, then serve again. Batch Analytics is the part that supports the improve-data step, especially when teams need to process large corpora or prepare training sets at scale.
That is where the platform’s unified storage story becomes more than a storage pitch. If a team can run batch jobs on the same vectors that power real-time search, it can keep the feedback loop tighter and avoid duplicate pipelines.
- Semantic deduplication
- Multi-petabyte training-data prep
- Large-scale offline processing on the same foundation
How to decide
Pick Performance-Optimized if your app lives or dies on fast retrieval and high query volume. Choose Capacity-Optimized if you want a balance of cost and responsiveness, or Tiered-Storage if your workload is steadier and storage cost matters more than raw speed.
Choose On-Demand Search if your usage is spiky, Interactive Discovery if analysts need to explore vector data without copying it, and Batch Analytics if your team is trying to keep the serve-learn-improve loop inside one platform. For most AI teams, the real question is not which single feature is best, but which mix removes the most duplicated infrastructure.
// Related Articles
- [IND]
Kimi K3 pushes open-weight AI toward default
- [IND]
Anthropic’s open-model fight reveals its lonely AI stance
- [IND]
Immich Docker Compose setup that avoids common errors
- [IND]
Millions Raised for Zhipu-style Social World Model
- [IND]
Anthropic’s Book Scanning Strategy Could Set a Pattern
- [IND]
Huang’s open-letter playbook for open-weight AI